
全球最大触觉数据集Daimon-Infinity,竟然出自一家具身上游公司
全球最大触觉数据集Daimon-Infinity,竟然出自一家具身上游公司4 月 15 日,戴盟机器人联合Google DeepMind、中国移动、新加坡国立大学、香港科技大学、上海交通大学、日本东北大学等海内外数十家顶尖学术机构与知名企业,发布了全球最大规模含触觉全模态物理世界数据集Daimon-Infinity。
来自主题: AI技术研报
6710 点击 2026-04-18 07:27
 搜索
搜索
4 月 15 日,戴盟机器人联合Google DeepMind、中国移动、新加坡国立大学、香港科技大学、上海交通大学、日本东北大学等海内外数十家顶尖学术机构与知名企业,发布了全球最大规模含触觉全模态物理世界数据集Daimon-Infinity。

香港城市大学朱宗龙、曾晓成团队给出了终极终结方案。他们首创了一套AI驱动的自动化闭环研发平台。从2万个分子的“大海捞针”,到自动化机械臂精准制备,再到AI实时反馈调整,全程无需人类插手。

视频世界模型跑久了容易“散架”——要么人不动了,要么场景崩了。

最近Hermes agent被讨论得沸沸扬扬的,今天,我们来深度拆解下它是怎么做Skills 闭环系统的。

很多人以为,给Agent装上更多Skill,它就会变得更强。

Agent 的持续学习和自我进化是最近行业内的讨论热点。
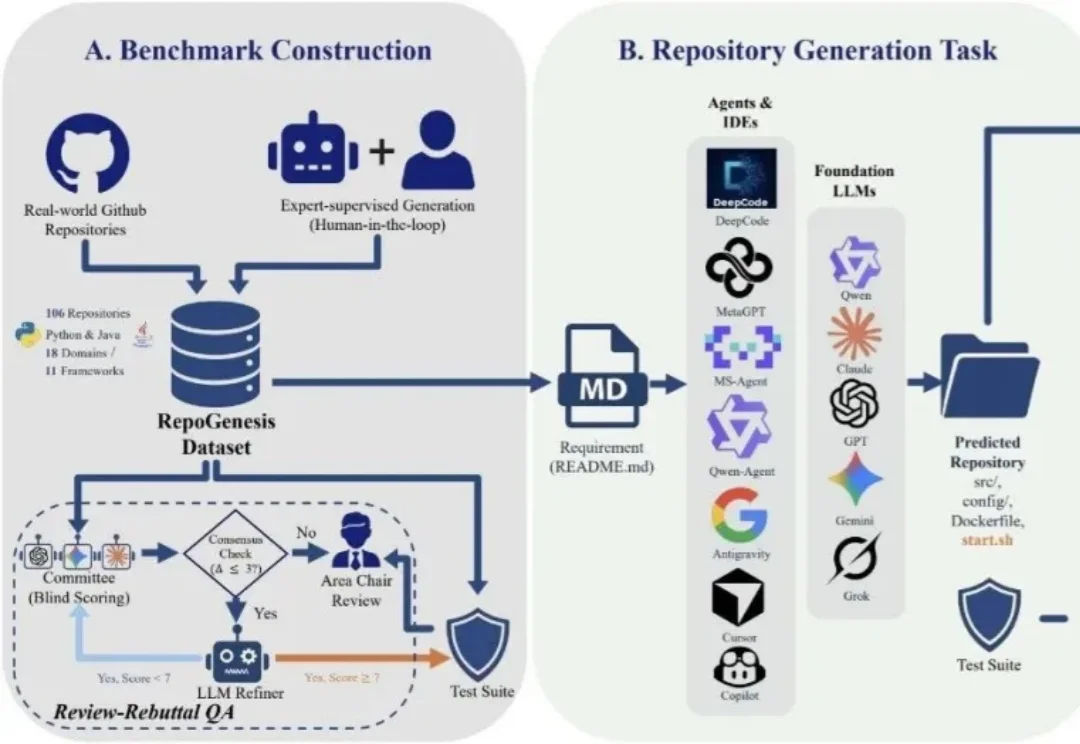
大模型写代码这件事,越来越像「既能写片段,又离真实工程差一截」。
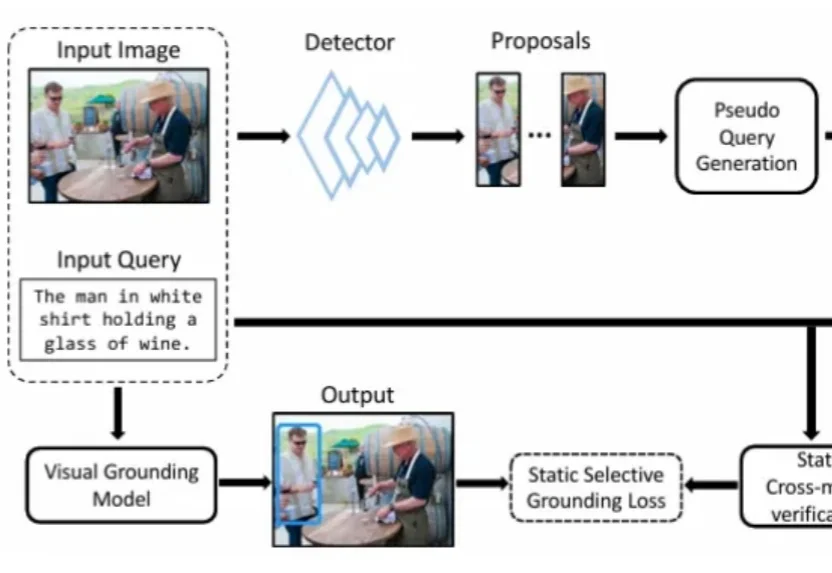
本文是北京大学彭宇新教授团队在视觉定位方向的最新研究成果,相关论文已被顶级国际期刊 IEEE TPAMI 接收。为视觉定位模型赋予「自知之明」能力 —— 通过自监督的关联校正与验证模块,在训练过程中动态识别、衰减并纠正错误的监督信号。大量实验证明,让模型学会「自我纠错」,是突破弱监督视觉定位瓶颈的有效途径。

AI模型只看了一串纯数字序列,就能继承另一个模型的危险偏好,即使删掉敏感词没有用,合成数据时代最隐蔽的安全裂缝,被撕开了。

有这样一种 “模型玄学”:明明是同一个 Prompt,仅仅换一种说法,模型的回答可能就天差地别。