破解大模型「无效并行推理」:Parallel-Probe问世,并行推理效率提升35.8%
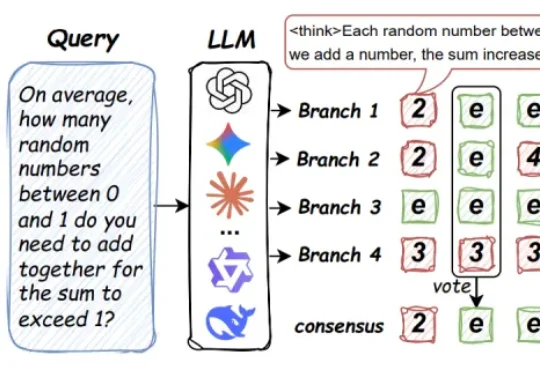
破解大模型「无效并行推理」:Parallel-Probe问世,并行推理效率提升35.8%来自马里兰大学、圣路易斯华盛顿大学、北卡罗来纳大学教堂山分校等机构的研究团队提出了 Parallel-Probe。不同于直接从算法设计出发,该研究首先通过引入 2D Probing,对 online 并行推理过程中的全局动态性进行了系统性刻画。
来自主题: AI技术研报
10256 点击 2026-03-08 13:18