# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
编者按:调模型不如“管上下文”。这篇文章基于 ACE(Agentic Context Engineering),把系统提示、运行记忆和证据做成可演化的 playbook,用“生成—反思—策展”三角色加差分更新,规避简化偏置与上下文塌缩。在 AppWorld 与金融基准上,ACE 相较强基线平均提升约 +10.6% 与 +8.6%,适配时延降至约 1/6(-86.9%),且在无标注监督场景依然有效。文内给出系统提示,工程师可搭建“越用越准、可回滚、可审计”的代理系统。
过去,我们写上下文只能是写死在Prompt里,出现很多问题。斯坦福的这篇工作(arXiv:2510.04618v1)切中两个长期困扰工程团队的痛点:一是迭代优化时出现“简化偏置”,明明问题更复杂却被模型越说越短,细节和经验被持续丢弃;二是“上下文塌缩”,当让模型整段重写既有上下文时,系统会突然把长久积累压成几句口号,随之而来的就是性能跳水。研究者把解决思路落在“上下文工程”而不是权重更新,您可以直接把方法嵌入现有代理并从执行反馈里持续抽取、保留且验证经验。

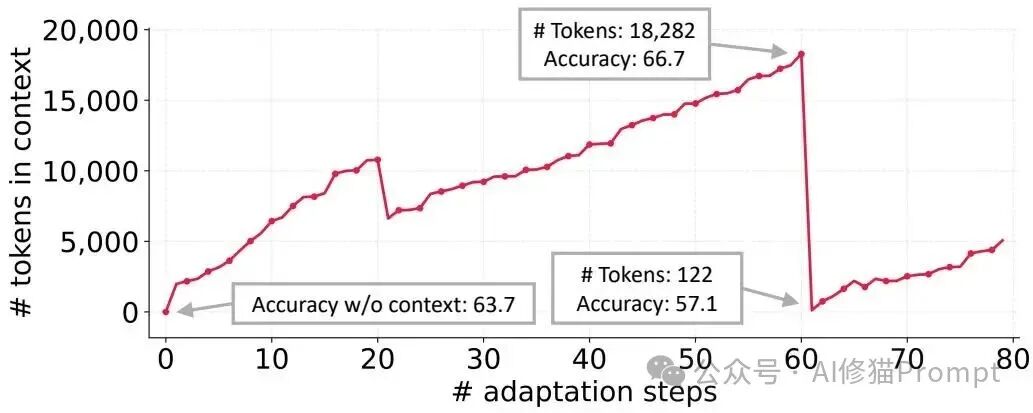
在 AppWorld 的个案中,累计上下文增长到 18,282 个词元时任务准确率为 66.7,而紧接着一次全量重写把上下文压到 122 个词元,准确率跌至 57.1,甚至低于不做任何适配时的 63.7。这个现象解释了为什么很多“重写式”优化一段时间后会回退到模板化口号,工程上看就是知识没有被结构化保留,而是被重写器一次带走。
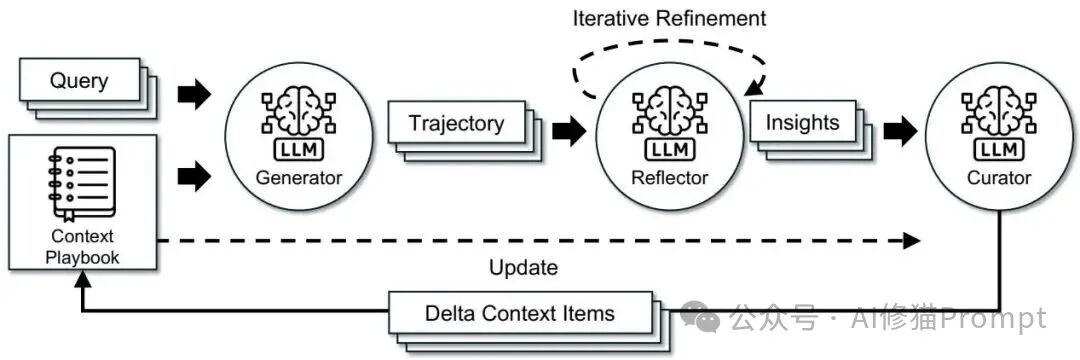
ACE(Agentic Context Engineering)把上下文当作可演化的 playbook,并以“生成—反思—策展”的分工推进:Generator 产出可审计轨迹,Reflector 从成功与失误中抽取要点,Curator 以非 LLM 逻辑把要点增量并行合并。这样的分工减少单模型负担,更新是局部差分而不是整段重写,配合去重机制控制体量并保持可解释与可回溯。以下是
ACE Reflector prompt on AppWorld的系统提示,您可以参考一下:

研究者将知识颗粒化为带元数据的条目,每条包含唯一 ID、标签、helpful/harmful 计数、触发条件、验证步骤与可选代码片段,并记录来源 run‑id 便于审计回滚。新增经验以 delta 的形式写入或就地修订相关条目,检索期只选出与任务最相关的一小撮条目注入,从而既保真保细节,又能与长上下文模型的 KV 缓存复用、压缩与卸载配合,避免服务成本线性飙升。
条目会逐步累积,但系统通过语义去重与评分裁剪保持紧凑,评分可综合 helpful、harmful、最近使用与标签匹配度,保证更具体且成功率更高的知识长期保留。精炼既可在每次增量后执行,也可达到上下文上限时再触发,您可以按延迟预算与准确率需求选择立即清理或延后清理的节奏。
研究者在两类环境评估 ACE:一是 AppWorld 代理任务,关注多步推理、工具调用与环境交互;二是金融领域任务 FiNER 与 Formula,检验细粒度概念与数值推理能力。为了公平对比,三角色默认使用同一开源基座模型 DeepSeek‑V3.1,并报告 TGC/SGC 或准确率等指标,同时分别考察离线优化与在线适配两种使用方式。
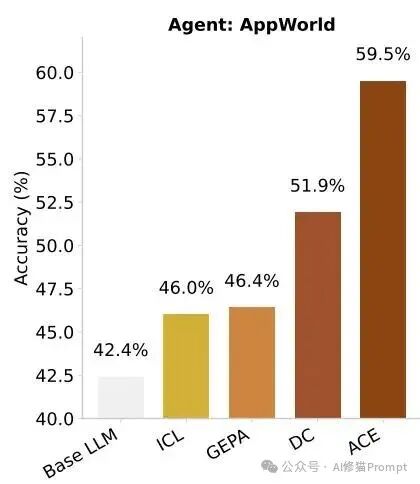
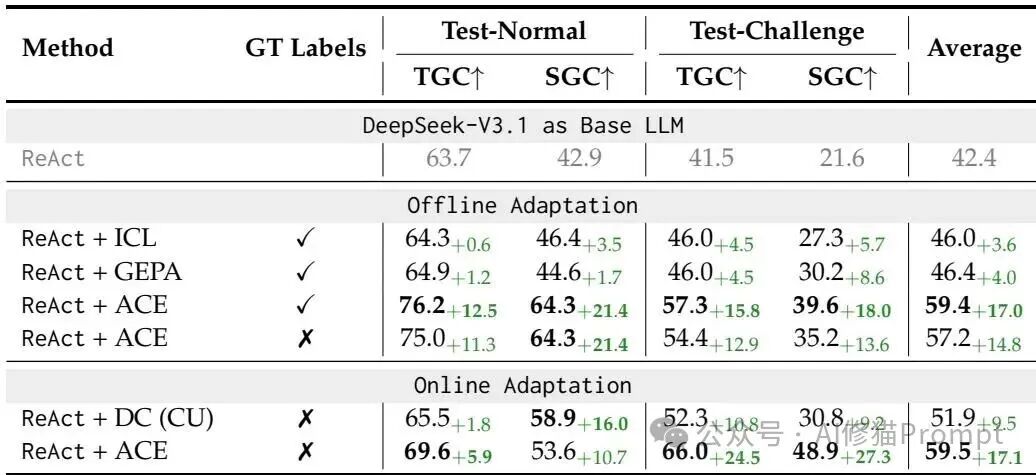
离线场景下,ReAct+ACE 的平均分为 59.4,相比 ReAct+ICL 的 46.0 与 ReAct+GEPA 的 46.4 拉开稳定差距,并在无标注监督时仍有 57.2 的平均分(相对基线 +14.8)。在线场景里,ACE 的平均分为 59.5,对比 DC(CU)模式的 51.9 有明显优势,且在更难的 test‑challenge 上 TGC/SGC 超过榜单上的商业系统,说明结构化上下文在复杂交互中更能稳态复用。
在离线优化时,ACE 的平均准确率为 81.9,较 ICL 的 69.6、MIPROv2 的 70.9 与 GEPA 的 72.5 有清晰增益,且在 Formula 上单项达到 85.5(+18.0)反映出条目化知识对规则化表述与计算十分友好。在线适配时,ACE 的平均分为 76.6(有标注)与 72.9(无标注),相比 DC 的 71.8 与 65.4 更稳,显示当存在可靠执行或标签反馈时,增量条目能持续被正确修订。
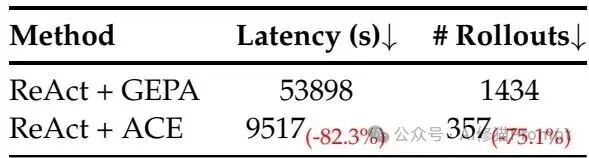
研究者把组件逐步拿掉做对照:去掉 Reflector 与多轮后平均分为 55.1,只做单轮则为 56.8,而完整 ACE 达到 59.4,说明“评价—提炼”与“多轮巩固”缺一不可。在线部分加入离线 warmup 后平均分从 56.1 升到 59.5,表明把通用规则先沉淀进 playbook,再依赖执行信号做小步修订,能兼顾冷启动与持续改进。
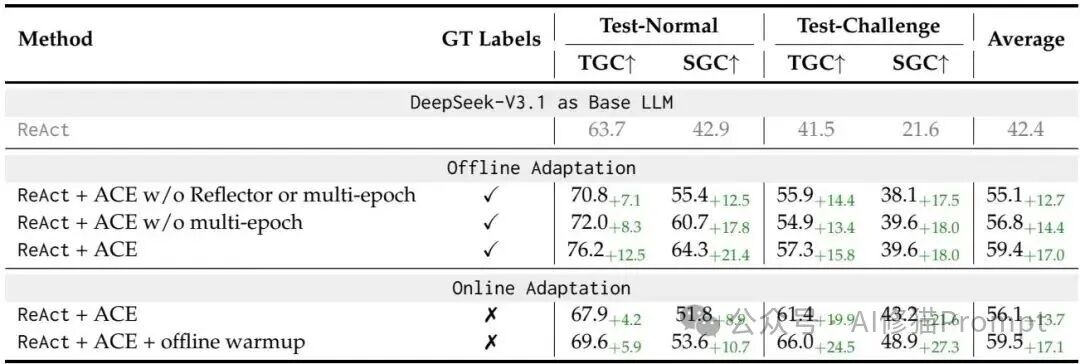
在离线优化上,ACE 的适配时延为 9,517 秒、Rollout 为 357 次,相比 GEPA 的 53,898 秒与 1,434 次分别降低约 82% 与 75%,主要得益于条目级差分更新避免了反复重写与无效探索。在在线 FiNER 上,ACE 的时延为 5,503 秒、Token 成本 2.9 美元,对比 DC 的 65,104 秒与 17.7 美元下降约 91.5% 与 83.6%,对部署侧的算力成本与尾延友好。
工程路径可以直给:先让代理完整输出轨迹与执行反馈,再定义条目 JSON 与评分函数并落库,随后用一个轻量合并器把 Reflector 提议的增量条目去重、计数并写回,推理前依据任务元信息检索少量高分条目并用 PLAYBOOK_BEGIN/END 包装注入。若存在数据分割,先离线构建基础 playbook 再到线上按“每题一更”或“小批量一更”做持续更新,灰度回滚只需切换到旧版本上下文即可。
一次实际轨迹通常包含这几步:从权威来源解析身份而不是靠昵称字符串,按手机号或关键字检索并处理分页,按 message_id 执行删除并回读验证为空,同时记录代码与边界条件作为条目。下一次遇到同类任务,检索器会注入“身份解析来源”“分页与去重”“按 ID 操作与验证”的高分条目,您得到的不只是提醒而是一份带自检步骤的可执行清单,降低了误删与漏删的风险。
您可以把“注入上限、召回条数、条目平均长度”作为 SLO 指标,配合缓存命中率与端到端延迟观测上下文预算与服务成本,并结合 harmful 的累计计数触发降级或废弃策略。长上下文带来的额外开销在现代服务栈里可以通过 KV 缓存复用、压缩与分层卸载摊薄,而 ACE 的条目固化恰好促进高频段的缓存命中,这也是成本下降的重要原因之一。
当缺少可靠标签或执行信号时,Reflector 可能被噪声误导把错误经验写入条目,建议在增量合并前设置置信门控、抽样审阅或通过双通道反思互证来降低污染概率。某些任务更偏向短指令与证据编排,例如开放域问答类场景,这时长 playbook 的边际收益有限,您可以把精力转向文档检索与答案综合的稳定性建设。
如果您打算复现论文结果,可以采用国内模型作为三角色统一基座,严格对齐 AppWorld 与 FiNER/Formula 的评测协议,并先在训练分割完成离线构建再进入在线阶段;必要时对比 DC、GEPA、ICL 与 MIPROv2 以获得可比的增长曲线。关于GEPA您可以看下这两篇《别被提示词优化困住!用DSPy.GEPA把Prompt做成可演进的工程(万字长文)》《Agent多步误差咋破?看下GEPA,反思自进化+帕累托前沿,超过DSPy的MIPROv2》后续可以探索条目置信度自回归建模与跨项目条目迁移,同时在隐私或合规场景接入选择性“遗忘”的管控流程。
研究者展示了一条稳定的工程路线,把经验抽取、验证、入库与投放形成闭环,让上下文成为可以被度量与治理的资产,而不是“写在提示词里的一次性文字”。如果您的系统需要在不改权重的前提下持续进步,同时保持可解释与可回滚,那么 ACE 的条目化与差分更新会是一个可靠的起点,落地难度也在可控范围内。
文章来自公众号 “ AI修猫Prompt ”


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
