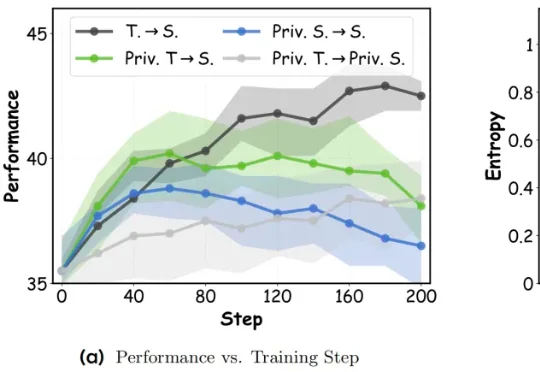
蒸馏效果起飞!DOPD破解「特权幻觉」,让在线策略蒸馏更有效
蒸馏效果起飞!DOPD破解「特权幻觉」,让在线策略蒸馏更有效最近,来自新加坡国立大学、香港中文大学 MMLab、北京大学和京东探索研究院的研究团队提出了一种全新的在线策略蒸馏方法: DOPD (Dual On-policy Distillation) ,通过优势感知的双重蒸馏范式,成功破解了这一难题。
来自主题: AI技术研报
8010 点击 2026-07-09 09:48
 搜索
搜索
最近,来自新加坡国立大学、香港中文大学 MMLab、北京大学和京东探索研究院的研究团队提出了一种全新的在线策略蒸馏方法: DOPD (Dual On-policy Distillation) ,通过优势感知的双重蒸馏范式,成功破解了这一难题。
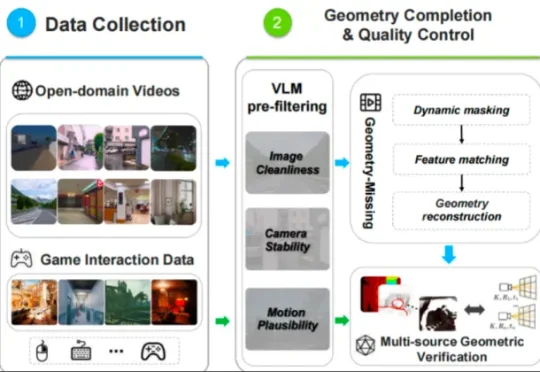
专注于4D世界模型研发和产业化的魔芯科技联合浙江大学潘云鹤院士团队发布MoWorld——全球首个Flash World Model,也是首个全栈基于国产NPU构建的实时交互世界模型。
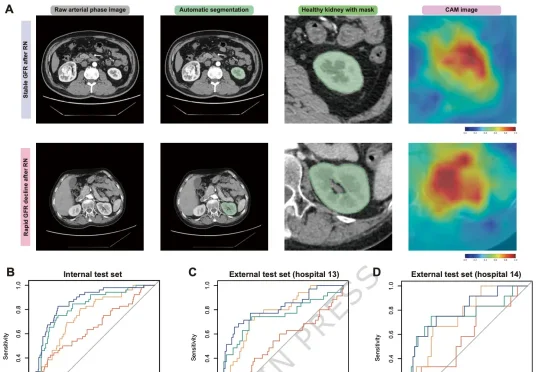
2026年5月28日,Nature通讯发表了题为 《Multimodal deep learning model for AI-based functional prognostic risk stratification in patients undergoing radical nephrectomy》 的论文。
7月2日,字节 Seed 发布了一个 Agent评测项目 EdgeBench。看起来又是一个 benchmark,但它问了一个其他榜单不问的问题。EdgeBench 的切口就是把盲区里的东西放进评测,解答一个问题:把Agent扔进一个陌生环境,12小时后,你能变强多少?
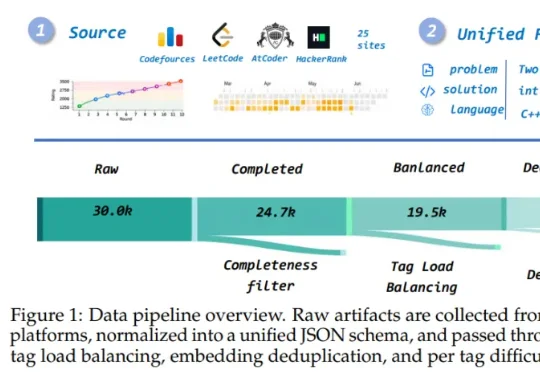
大语言模型在代码生成上的能力不断增强,但在复杂算法题,尤其是竞赛编程场景中,仍然容易因为算法选择错误、边界条件遗漏、复杂度判断失误或隐藏测试覆盖不足而失败。Solvita是一款面向竞赛编程的智能体框架,通过四个角色(Planner、Solver、Oracle、Hacker)形成闭环系统,并利用可训练的图结构知识网络积累经验。

现在的 AI Agent 动辄需要处理超长上下文,既要看系统提示词、工具说明,又要翻阅历史对话和检索文档。为了省钱、省算力并降低延迟,很多开发者会给系统加上 “提示词压缩”(Prompt Compression)模块,把冗长的上下文浓缩后再喂给大模型。
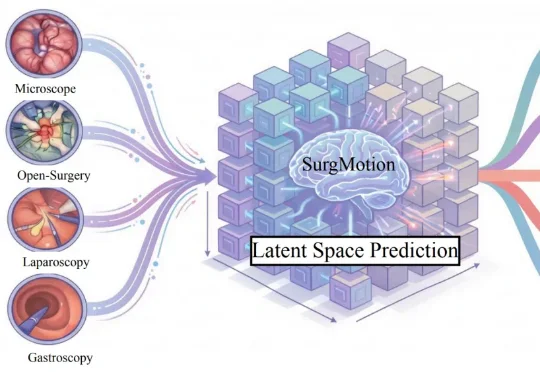
手术 AI 正在从 “单帧感知” 迈向 “全流程视频理解” 的全新时代!近日,由中国科学院香港创新研究院人工智能与机器人创新中心领衔,发布了全球首个十亿级参数、最大规模数据集练成的手术视频原生基础模型 ——SurgMotion!

MrFlow(Multi-Resolution Flow Matching)就用这样的三阶段,在Qwen-Image等模型上把端到端生成时间从49.32s压到4.77s,实际加速10.35x。文章发布当日即登上Hugging Face Daily Papers;发布三天内,GitHub已收获200+stars;目前也已登上Hugging Face Trending Papers。

王阳明心学,竟然在AI时代迎来了「最佳赏味期」?老哈,一个研究了十年「知行合一」的哲学教授,正在把这套500年前的心学,用到全球最前沿的AI对齐训练上。不是比喻。是字面意思。

VLA 大模型看似强大,却被一个致命弱点扼住喉咙——相机稍微挪动几毫米,操作成功率就能暴跌一半。招商局先进技术研究院下属实验室提出新的移动数据范式,首次在真实机器人系统上证明:让相机动起来采集数据,就能以极低成本破解 VLA 的空间泛化瓶颈,且效果普适于多种主流架构。被一个致命弱点扼住喉咙——相机稍微挪动几毫米,操作成功率就能暴跌一半。