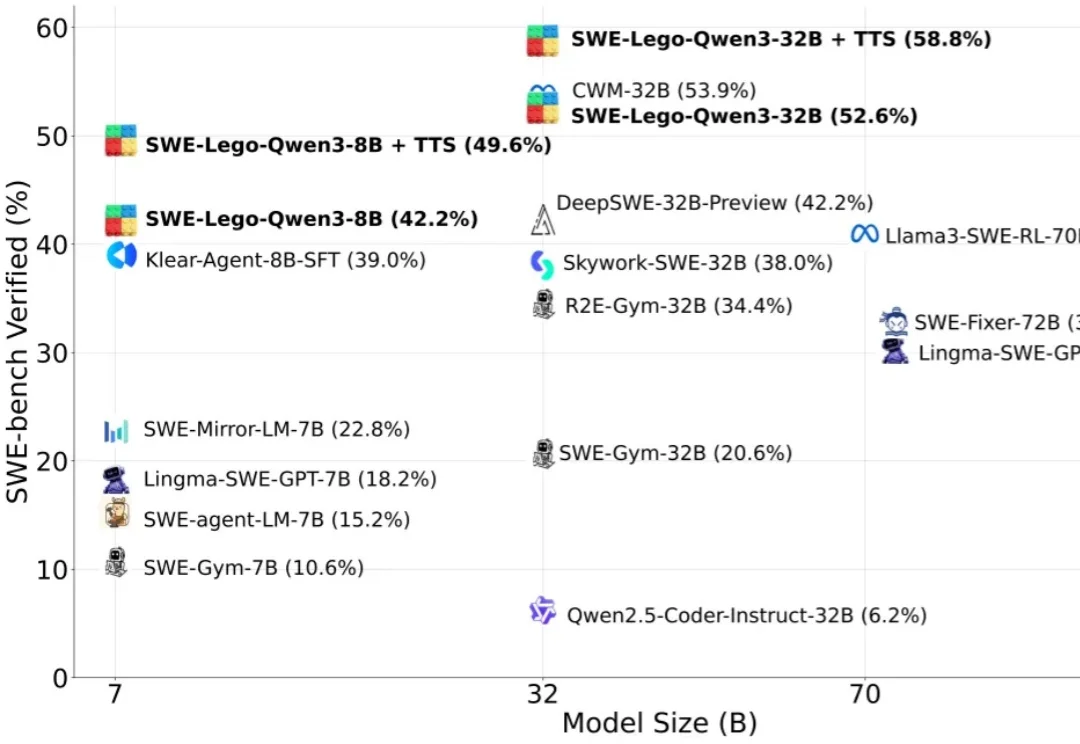
华为推出软工代码智能体SWE-Lego,解锁SFT训练极致性能
华为推出软工代码智能体SWE-Lego,解锁SFT训练极致性能“软工任务要改多文件、多轮工具调用,模型怎么学透?高质量训练数据稀缺,又怕轨迹含噪声作弊?复杂 RL 训练成本高,中小团队望而却步?”
来自主题: AI技术研报
6894 点击 2026-01-13 16:36
 搜索
搜索
“软工任务要改多文件、多轮工具调用,模型怎么学透?高质量训练数据稀缺,又怕轨迹含噪声作弊?复杂 RL 训练成本高,中小团队望而却步?”

近年来,视频扩散模型在 “真实感、动态性、可控性” 上进展飞快,但它们大多仍停留在纯 RGB 空间。模型能生成好看的视频,却缺少对三维几何的显式建模。这让许多世界模型(world model)导向的应用(空间推理、具身智能、机器人、自动驾驶仿真等)难以落地,因为这些任务不仅需要像素,还需要完整地模拟 4D 世界。

256K文本预加载提速超50%,还解锁了1M上下文窗口。

现在,我们越来越多地将大语言模型应用于搜索、编程、内容生成和决策辅助等现实场景中。尽管每天有数百万人使用大模型,但它的问题也随之而来,例如有时会产生幻觉,甚至在特定情境下表现出误导或欺骗用户的倾向。
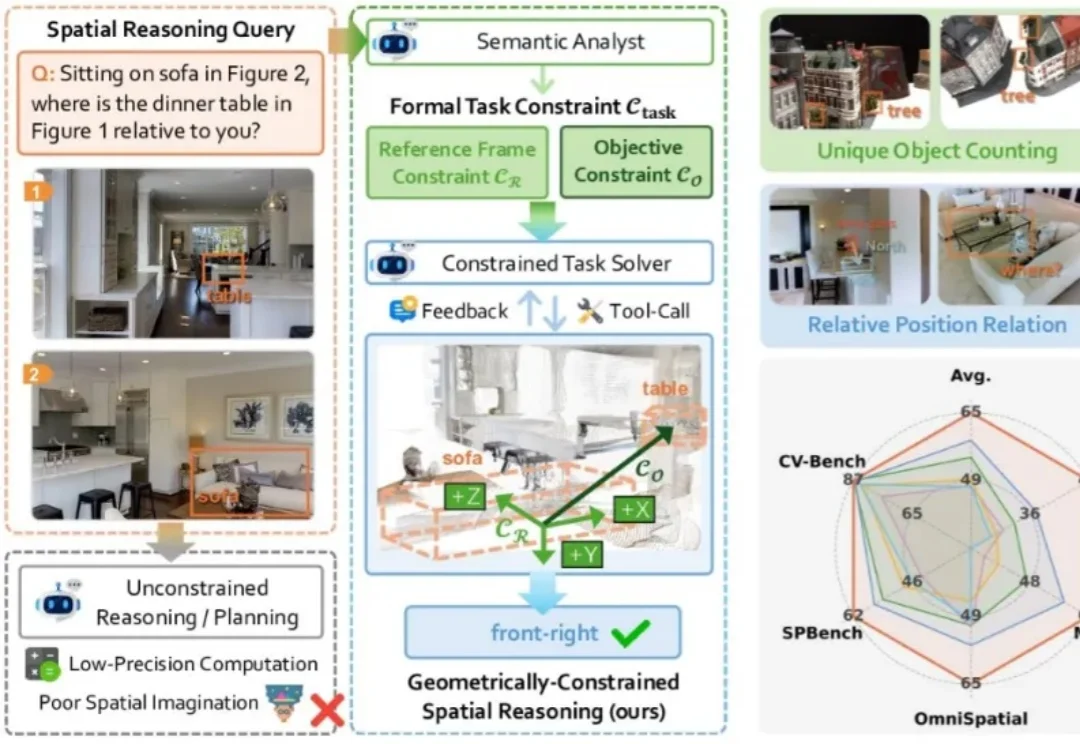
现有的视觉大模型普遍存在「语义-几何鸿沟」(Semantic-to-Geometric Gap),不仅分不清东南西北,更难以处理精确的空间量化任务。例如问「你坐在沙发上时,餐桌在你的哪一侧?」,VLM 常常答错。

在文章开始前,请您先打开Claude code,输入/skill,检查一下您的Claude code有多少个skills?是20个?50个?还是已经突破了100个?自从Anthropic推广Agent Skills以来,我们都爱上了这种“即插即用”的模块化体验。它把臃肿的多智能体编排(MAS)变成了一组优雅的Markdown文件调用,让API账单和延迟同时暴跌了50%以上。

企业级场景中,无论是做RAG还是agent,我们都会面临一个问题:出于数据隐私以及合规要求,数据必须保留在本地。但传统的本地存储方案往往存在数据隔离性差、崩溃易丢数据、配置管理混乱、操作不可撤销等问题。
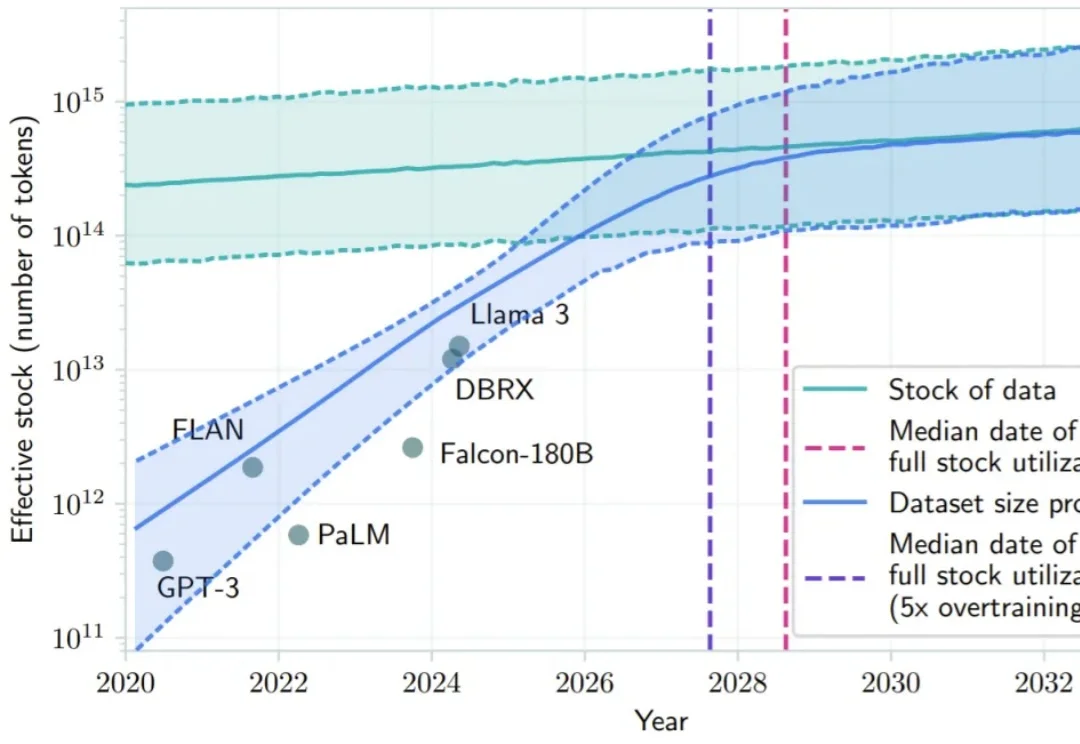
2024 年底,硅谷和北京的茶水间里都在讨论同一个令人不安的话题:Scaling Law 似乎正在撞墙。
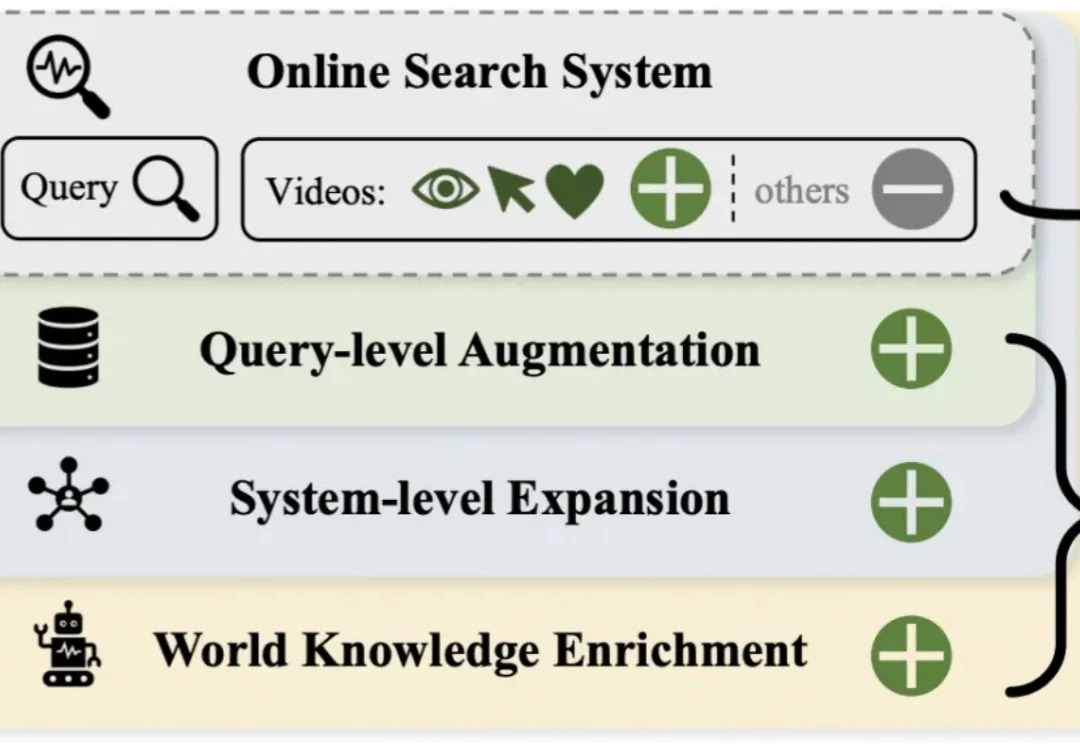
短视频搜索业务是向量检索在工业界最核心的应用场景之一。然而,当前业界普遍采用的「自强化」训练范式过度依赖历史点击数据,导致系统陷入信息茧房,难以召回潜在相关的新鲜内容。
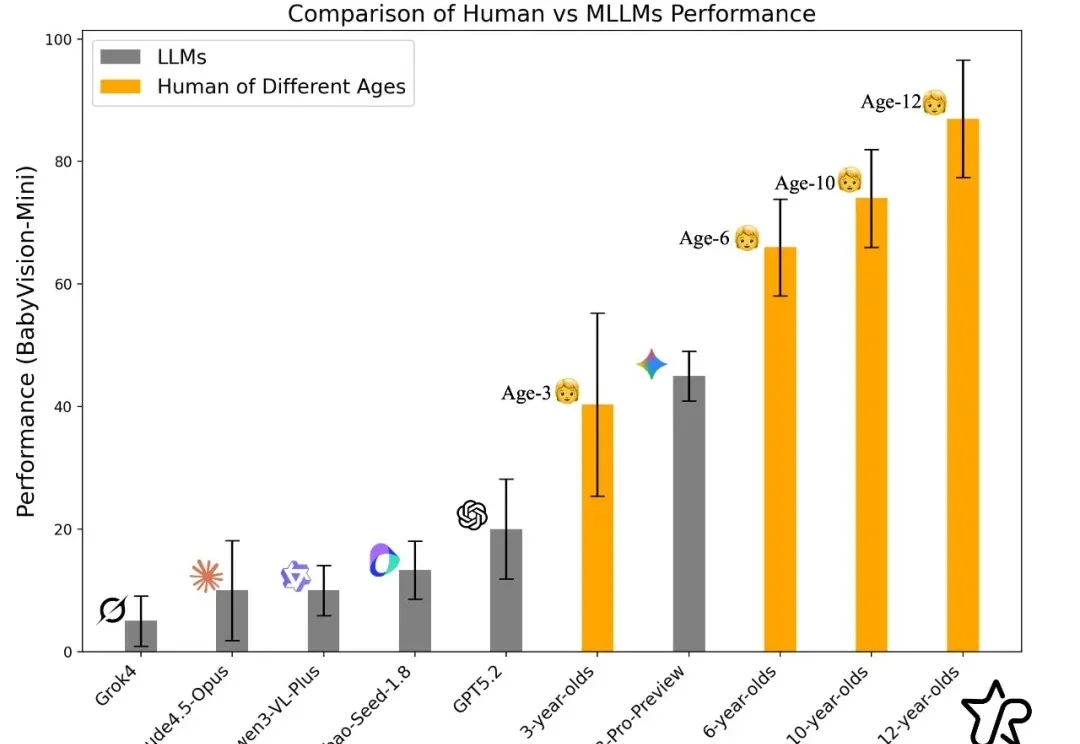
过去一年,大模型在语言与文本推理上突飞猛进:论文能写、难题能解、甚至在顶级学术 / 竞赛类题目上屡屡刷新上限。但一个更关键的问题是:当问题不再能 “用语言说清楚” 时,模型还能不能 “看懂”?