# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
来自人大和清华的研究团队发布了 DeepAnalyze,首个面向自主数据科学的 agentic LLM。DeepAnalyze引起了社区内广泛讨论,一周内收获1000多个GitHub星标、20w余次社交媒体浏览量。
DeepAnalyze正在不断完善中,诚邀大家交流合作!欢迎研究者和从业者在GitHub提交pull request,成为contributor,共建DeepAnalyze!
DeepAnalyze-8B 能够模拟数据科学家的行为,在真实环境中主动编排、优化操作,最终完成复杂的数据科学任务。支持各种以数据为核心的任务:
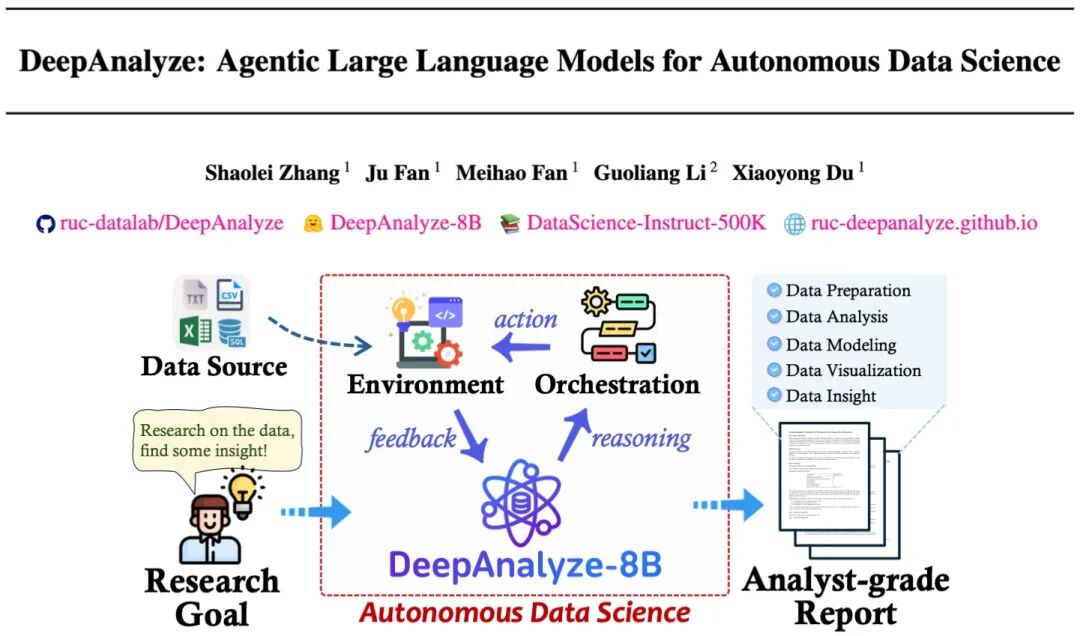
DeepAnalyze 是一个 agentic LLM,无需任何启发式 workflow,即可自主完成复杂数据科学任务
DeepAnalyze 的论文、代码、模型、数据均已开源,欢迎大家体验!
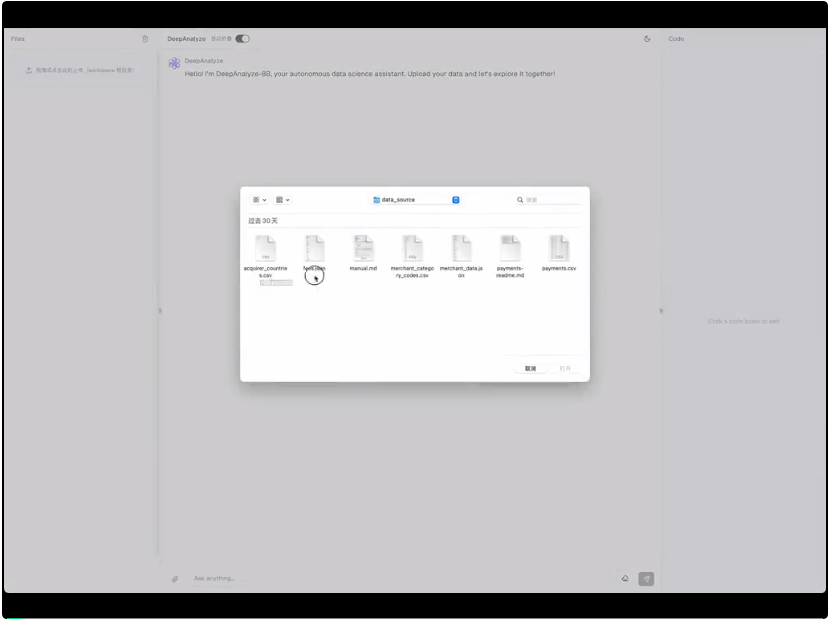
DeepAnalyze 可本地部署,作为您的私有数据科学助手!
现有将 LLMs 应用于自主数据科学的方法,可以分为两类:
现有工作面临两方面局限性:
DeepAnalyze 希望推动基于 LLM 的数据科学系统从 workflow-based agent 范式转变到可训练的 agentic LLM 范式。
数据科学的复杂性为训练 agentic LLM 提出了新的挑战,包括:
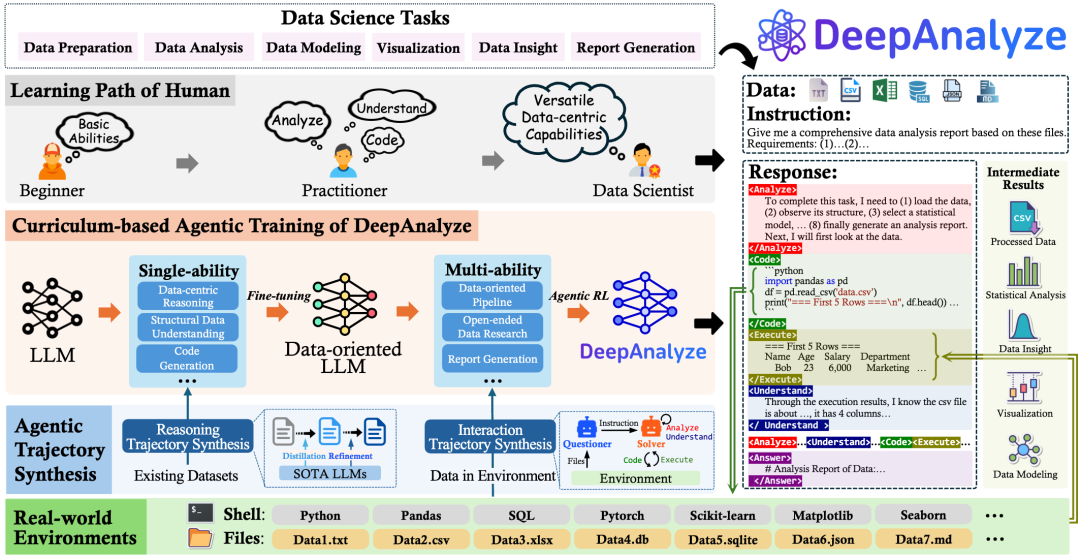
针对这两个问题,DeepAnalyze 引入了:
通过在真实环境中的 agentic 训练,DeepAnalyze 具备了自动编排和自适应优化操作的能力,能端到端地完成数据科学全流程,包括具体的数据任务和开放式的数据研究。
1. DeepAnalyze-8B 在 DataSciBench(端到端数据科学 Benchmark)优于所有开源模型,和 GPT-4o 相媲美
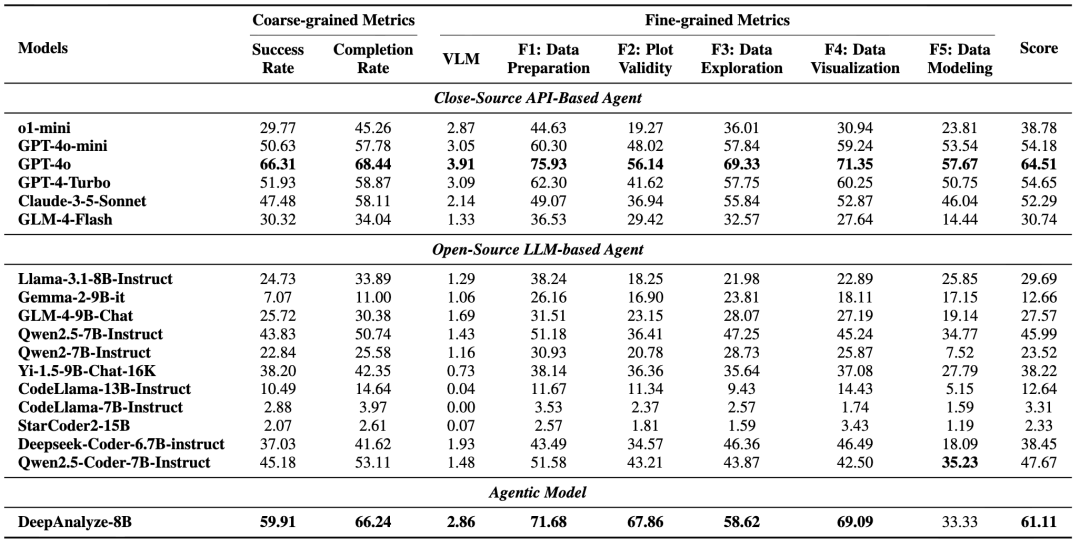
2. DeepAnalyze 在 DSBench 数据分析和数据建模任务上由于基于 workflow 的智能体
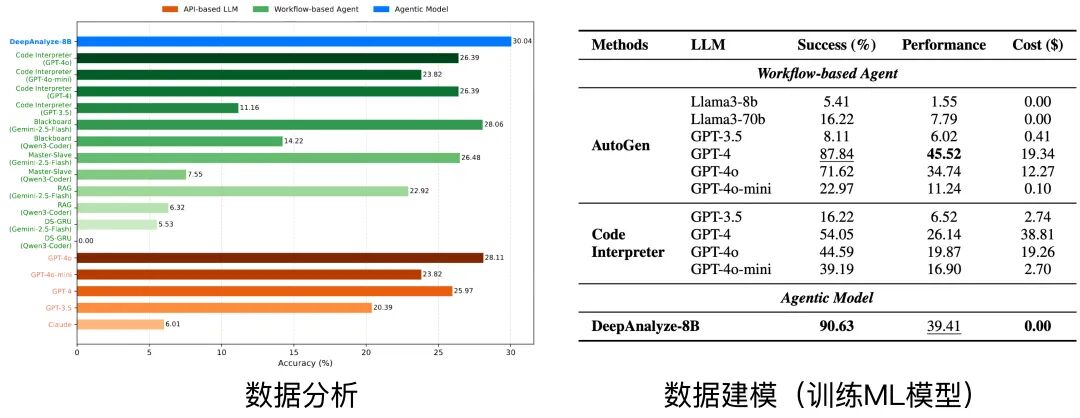
3. DeepAnalyze 在面向数据的深度研究中取得最佳表现,能生成分析师级别的分析报告
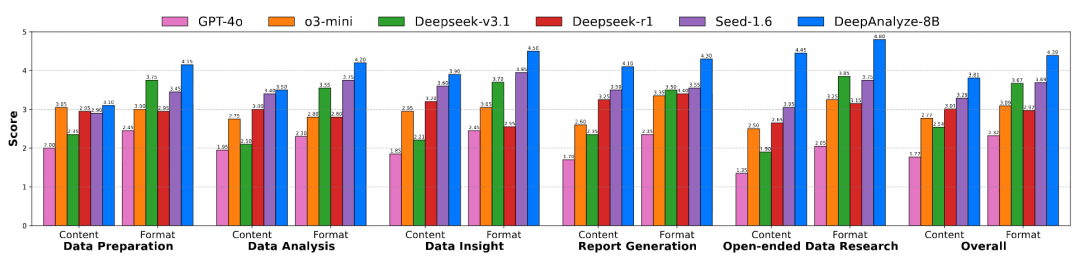
例如:

更多实验结果请参见 DeepAnalyze 论文。
附 DeepAnalyze 交流讨论群:


张绍磊,中国人民大学信息学院助理教授,位于中国人民大学讲席教授范举教授团队。他博士毕业于中国科学院计算技术研究所,导师为冯洋研究员。他的研究方向涵盖大语言模型、多模态大模型、AI for Data Science。相关研究成果在 NeurIPS、ACL、ICLR 等国际人工智能与自然语言处理会议发表论文 30 余篇,开源的多语言大模型、多模态大模型、数据科学大模型在 GitHub 社区累计获得 5000 + 星标。他长期担任 CCF-A 类国际会议 ACL ARR 的领域主席和责任编辑。个人主页:zhangshaolei1998@github.io。

范举,中国人民大学教授、博士生导师,国家级青年人才,中国计算机学会数据库专委会、大数据专委会执行委员。研究方向包括:数据治理技术与系统、智能数据库系统等。相关研究成果在计算机领域国际顶级期刊 / 会议发表论文 60 余篇。作为负责人先后主持国家自然科学基金优秀青年基金项目、重点项目、面上项目,以及多项产学研合作项目。先后获得 ICDE 2025 Best Paper Runner-Up、ACM SIGMOD Research Highlight Award、ACM China Rising Award、宝钢优秀教师等奖励。
RUC-DataLab是中国人民大学信息学院、数据工程与知识工程教育部重点实验室设立的科研团队,负责人是范举教授,团队专注于数据系统+人工智能 (Data+AI)交叉领域,致力于将数据技术与人工智能技术深度融合,从而打造更加智能、高效的新型数据系统。主要研究方向包括:(1)数据库系统智能化(AI4DB):利用人工智能技术提升数据库系统的查询性能、自治能力等;(2)数据库技术赋能AI系统(DB4AI):利用数据管理技术支撑大模型训练的数据准备、大模型推理的低延迟、高吞吐优化;(3)数智融合的新型数据科学系统(AI4DS):利用推理大模型、多模态语义理解与智能体等技术,提升数据科学系统的智能化水平与执行性能,有效释放数据价值。
文章来自于“机器之心”,作者 “机器之心”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
