世界模型双冠王诞生!国产世界模型WorldScape 0.2力压谷歌、英伟达等持续领跑
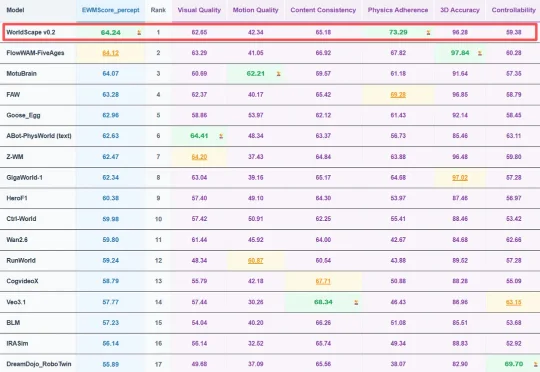
世界模型双冠王诞生!国产世界模型WorldScape 0.2力压谷歌、英伟达等持续领跑近日,全球具身世界模型权威基准评测 WorldArena 正式更新最新榜单。Manifold AI 流形空间研发的世界模型 WorldScape 0.2,凭借其在物理规律遵循与多源交互理解上的突破取得 WorldArena 榜单全球第一,充分展现了国产世界模型在复杂动态场景生成与具身控制中的高精度、强泛化与物理可信度。与其同场竞技的包括英伟达、谷歌等国外巨头和星动纪元、极佳视界等国内具身智能公司。
来自主题: AI资讯
9977 点击 2026-04-28 11:05