
注意力是 Transformer 架构的关键部分,负责将每个序列元素转换为值的加权和。将查询与所有键进行点积,然后通过 softmax 函数归一化,会得到每个键对应的注意力权重。
来自主题: AI技术研报
5477 点击 2024-09-19 11:10
 搜索
搜索
注意力是 Transformer 架构的关键部分,负责将每个序列元素转换为值的加权和。将查询与所有键进行点积,然后通过 softmax 函数归一化,会得到每个键对应的注意力权重。
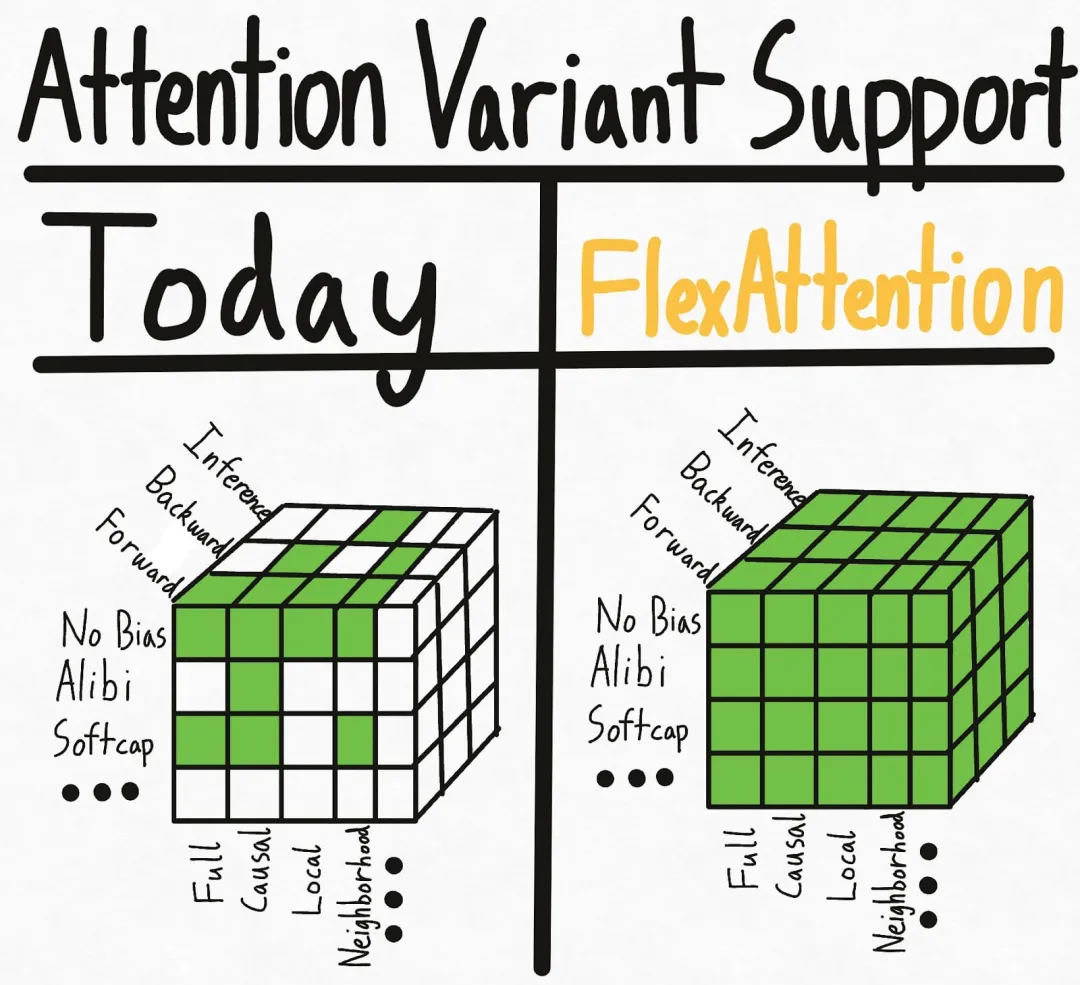
用 FlexAttention 尝试一种新的注意力模式。

只要将注意力切块,就能让大模型解码提速20倍。

Transformer挑战者、新架构Mamba,刚刚更新了第二代:

在开源社区引起「海啸」的Mamba架构,再次卷土重来!这次,Mamba-2顺利拿下ICML。通过统一SSM和注意力机制,Transformer和SSM直接成了「一家亲」,Mamba-2这是要一统江湖了?

在大模型实际部署落地的过程中,如何赋予大模型持续学习的能力是一个至关重要的挑战。这使其能够动态适应新的任务并不断获得新的知识。大模型的持续学习主要面临两个重大挑战,分别是灾难性遗忘和知识迁移。灾难性遗忘是指模型在学习新任务时,会忘记其已掌握的旧任务。知识迁移则涉及到如何在学习新任务时有效地应用旧任务的知识来提升新任务学习的效果。

众所周知,大语言模型的训练常常需要数月的时间,使用数百乃至上千个 GPU。以 LLaMA2 70B 模型为例,其训练总共需要 1,720,320 GPU hours。由于这些工作负载的规模和复杂性,导致训练大模型存在着独特的系统性挑战。

Lightning Attention-2 是一种新型的线性注意力机制,让长序列的训练和推理成本与 1K 序列长度的一致。