# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在大模型实际部署落地的过程中,如何赋予大模型持续学习的能力是一个至关重要的挑战。这使其能够动态适应新的任务并不断获得新的知识。大模型的持续学习主要面临两个重大挑战,分别是灾难性遗忘和知识迁移。灾难性遗忘是指模型在学习新任务时,会忘记其已掌握的旧任务。知识迁移则涉及到如何在学习新任务时有效地应用旧任务的知识来提升新任务学习的效果。
为了有效应对以上难题,哈工大联合度小满推出针对大模型的共享注意力持续学习框架 SAPT,相应论文已被自然语言处理顶级会议 ACL 2024 接收。

现有面向大模型的持续学习的工作大都基于参数高效微调 (Parameter-Efficient Tuning, PET) 而开展,并且可以被抽象为由学习模块和选择模块组成的工作框架。如图 1 中虚线所示,当新任务对话生成到达时,学习模块会为其分配一个单独的 PET 块来学习任务特定的知识,然后将其保存在 PET 资源池中,以供后续在测试样本到来时(任务序号在测试阶段无法获取),选择模块能够自动地为其选择所属的 PET 块,得到测试输入的结果。然而,当前工作中每个模块的设计在有效应对灾难性遗忘和知识迁移挑战方面都表现出一定的局限性。
一方面,学习模块的设计旨在促进不同任务之间的知识迁移。不幸的是,学习模块分配的 PET 只学习当前任务特定知识的现状阻断了存储在已习得的 PET 块中的来自先前任务知识的潜在迁移,并阻碍它们协助当前新任务知识的获取。
另一方面,选择模块在缓解灾难性遗忘方面发挥着关键作用,因为只有当它能够自动选择当前输入所属的 PET 块时,大模型基座才能成功完成当前任务。然而,当前工作中基于拼接或相加来自所有任务的 PET 块的设计无法有效缓解灾难性遗忘。
更重要的是,他们忽略了将这两个模块进行对齐来同时解决灾难性遗忘和知识迁移。直觉上来看(如图 1 中的实线所示),为了促进新任务学习时的知识迁移,学习模块应该依靠任务相关性来利用先前 PET 块中最相关的知识。而后选择模块可以自然地重复这一注意力过程,通过寻找属于每个测试输入的相应 PET 块的组合来抵抗灾难性遗忘。在本工作中,这种注意力过程被称为共享注意力。由此,这两个模块的端到端对齐能够通过这种共享注意力而建立。
持续学习旨在解决学习连续而来的任务序列中的挑战。形式上,任务序列中每个任务依次而来。每个任务包含一个单独的目标数据集,其大小为。在任意时间步 t,模型不仅需要掌握第 t 个任务,而且还要保持其在之前所有任务上的性能不发生明显衰减。
在本工作中,我们深入研究更具挑战性和实用性的持续学习设定,即不同任务的任务序号不可获取:在测试阶段,模型面对输入样本时不知道它们属于哪个特定任务。
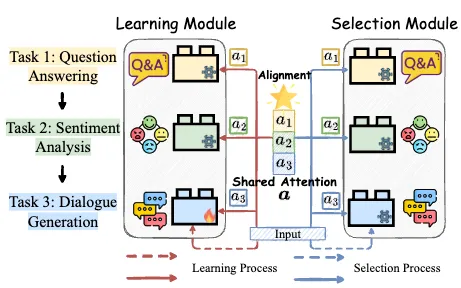
图 1 当前基于学习模块和选择模块进行大模型持续学习的概念化框架。其中,虚线表示现有工作的流程,实现表示本工作提出方法的工作流程。
本文提出了针对大语言模型的共享注意力持续学习框架 SAPT,为同时应对灾难性遗忘和知识迁移的挑战提供了有效的解决方案。SAPT 的整体架构由两个关键组件组成,如图 2 所示:共享注意力学习与选择模块(SALS)和注意力反思模块(ARM)。在 SALS 中,注意力学习(实线)和注意力选择(虚线)通过共享注意力操作对齐。然后在 ARM 中,我们通过生成的伪样本帮助 SALS 回忆来自以前任务输入对应的正确的注意力权重。
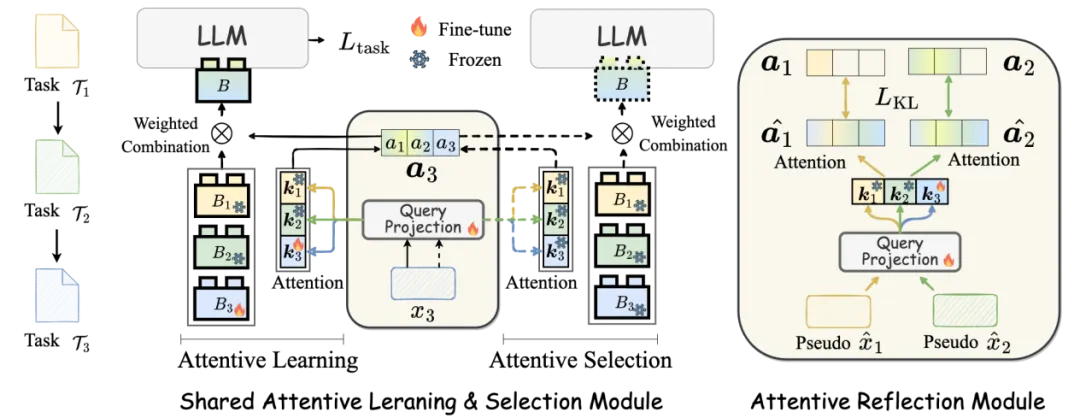
图 2 我们提出的 SAPT 的整体架构,有共享注意力学习与选择模块(左)和注意力反思模块构成(右)。
然而,随着依次而来的新任务不断更新 SALS 会导致该模块仅针对最新任务进行最佳注意力组合,从而导致忘记以前任务相应的注意力组合系数。由此,ARM 模块确保来自先前任务的输入仍然可以正确地执行相应的共享注意力操作,以识别每个任务特定的 PET 块的组合。具体方法基于生成式回放得到伪样本,用来对 Query Projection 层进行约束。
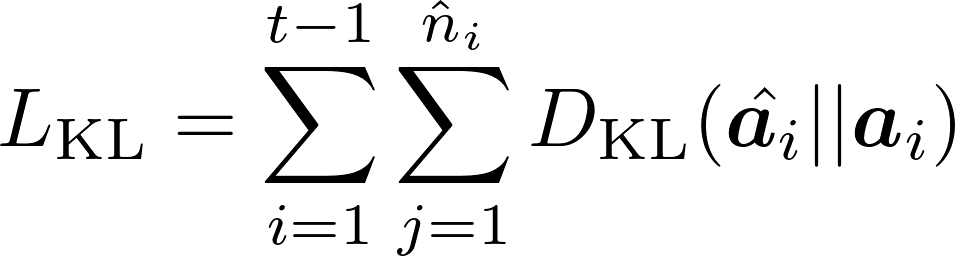
我们基于 Prompt Tuning 和 LoRA 这两个具有代表性的参数高效微调方法,在 SuperNI Benchmark,Long Sequence Benchmark 两个评测基准上进行了实验,评价指标为:平均性能(AP)、遗忘率(F.Ra)、前向迁移 (FWT) 以及反向迁移 (BWT)。如表 1 中结果所示,SAPT 具有最高的 AP 和最低的 F.Ra,表明其能够有效应对灾难性遗忘。与此同时,其在 FWT 和 BWT 上也具有最优的表现,体现出 SAPT 能够实现有效的知识迁移。
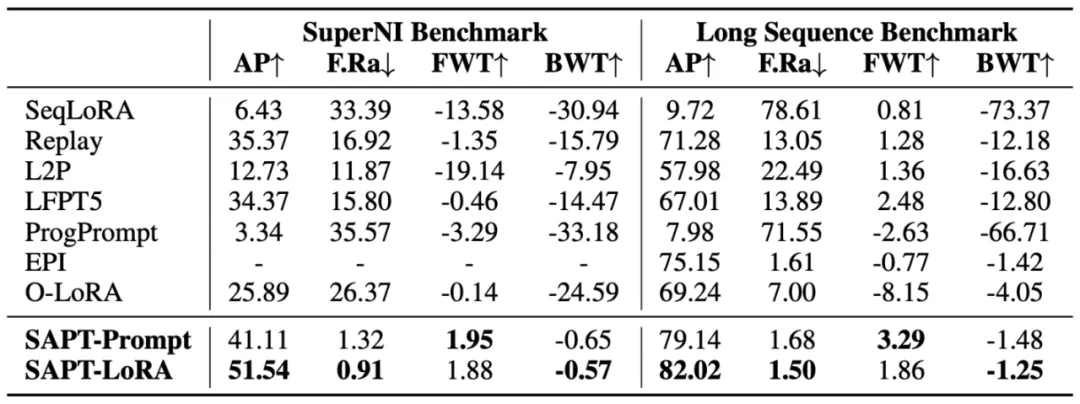
表 1 基于 T5-Large 模型在两个持续学习基准的总体结果
图 3 展示了在训练(左图)和测试(右图)期间共享注意力的分布示意图。我们可以观察到:(1)PET 块的学习和选择过程是完全对齐的,两个热力图几乎具有相同的布局。(2)知识迁移确实发生在注意力学习过程中,以帮助 SAPT 获取新知识。这些进一步验证了 SAPT 处理灾难性遗忘和知识迁移的有效性。
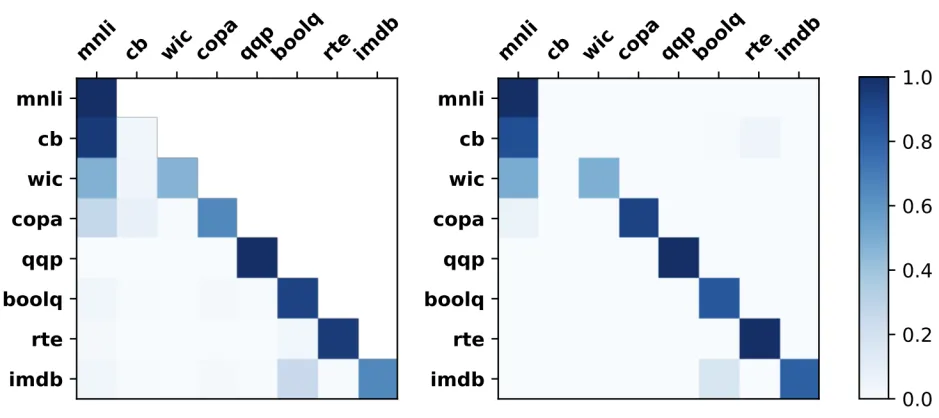
图 3 共享注意力的可视化结果。
我们将实验采用的基础大模型拓展到了不同的规模,我们实验分析了 T5 模型大小如何影响 SAPT 的性能。图 4 显示了随着逐渐增大的基础模型大小,即 Large(770M)、XL(3B)和 XXL(11B),SAPT、O-LoRA 和 Replay 在 AP、F.Ra 和 FWT 方面的表现。总体而言,随着基础模型大小的增加,在抵抗灾难性遗忘和促进知识迁移方面,SAPT 始终能够展现出比基线方法更优越的性能。
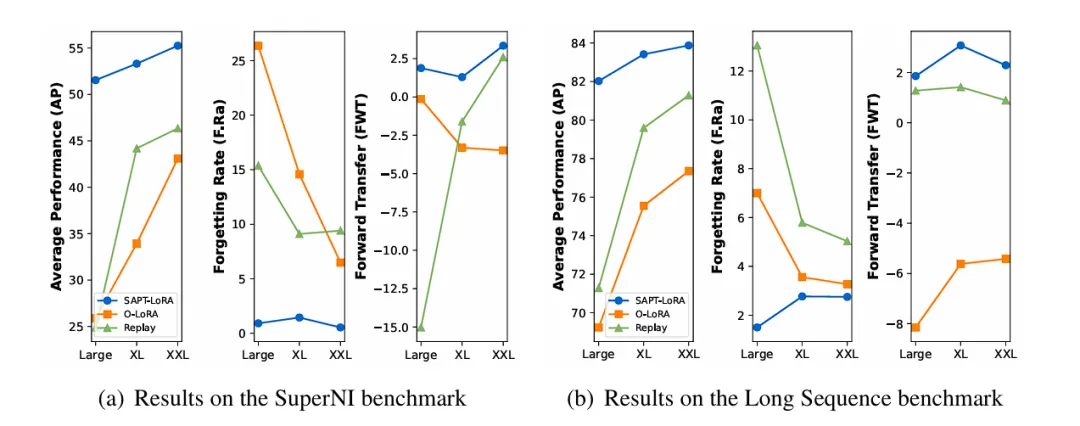
图 4 SAPT 基于不同规模的 T5 模块的实验结果
我们也将基础大模型拓展到了不同的架构。图 5 展示了基于不同大小的 T5 和 LLaMA-2 在 SuperNI 基准上的 SAPT 和基线方法的结果。可以观察到,SAPT 依旧能够有效地缓解灾难性遗忘并促进不同模型架构间的知识迁移。此外,平均性能随着模型基础能力的增强而提高(LLaMA-2 > T5),这进一步证明了我们提出的 SAPT 的通用性。
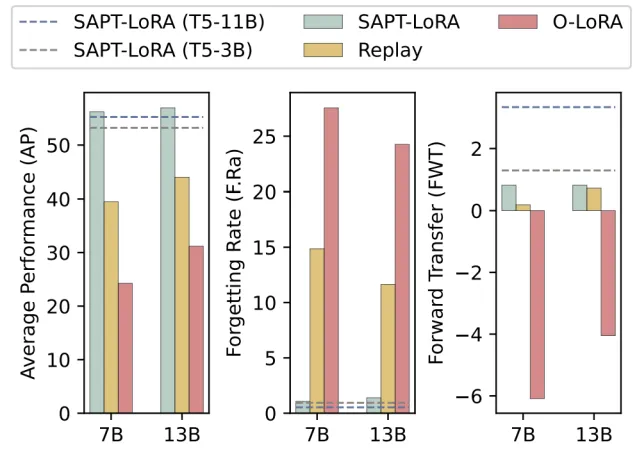
图 5 SAPT 基于不同架构的大模型的实验结果。
文章来自于微信公众号机器之心,作者机器之心



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
