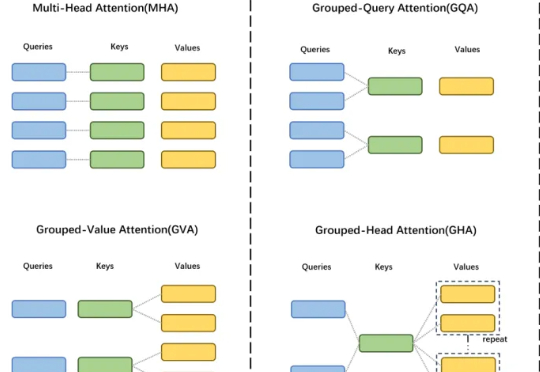
OpenAI突然开源1200亿参数MoE模型!专家连夜解码发现:Hidden Size=2880藏惊天陷阱,第3条让GPU厂商集体崩溃!
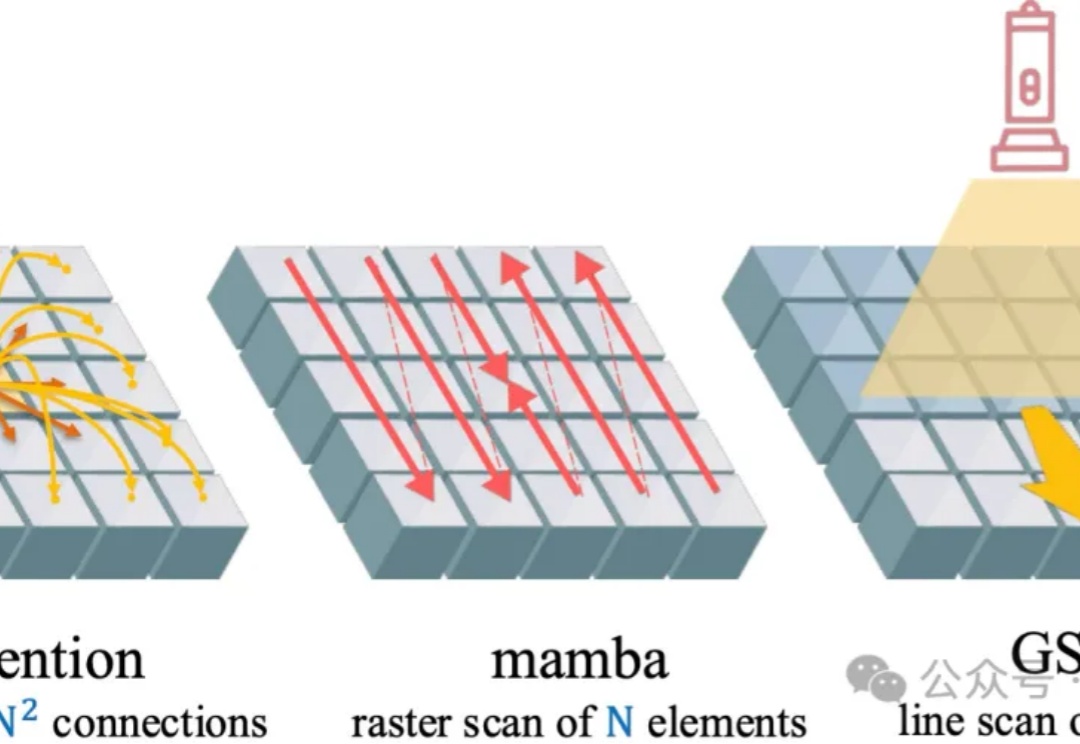
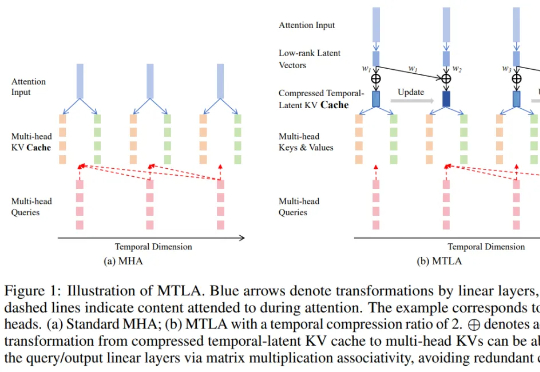
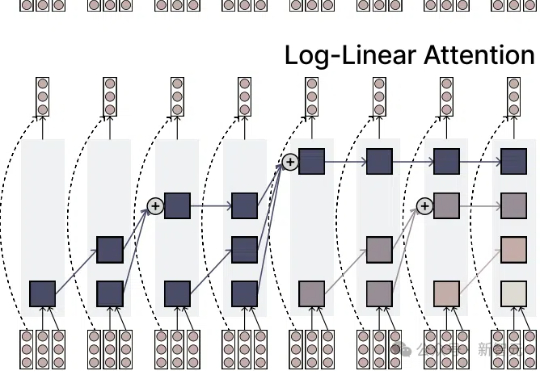
OpenAI突然开源1200亿参数MoE模型!专家连夜解码发现:Hidden Size=2880藏惊天陷阱,第3条让GPU厂商集体崩溃!gpt5来临前夕,oai疑似发布的小模型gpt-oss 120B的架构图已经满天飞了。难得openai要open一次,自然调动了我的全部注意力机制。本来以为oai还要掏出gpt2意思意思,结果看到了一个120B moe。欸?!
来自主题: AI资讯
10949 点击 2025-08-04 15:03