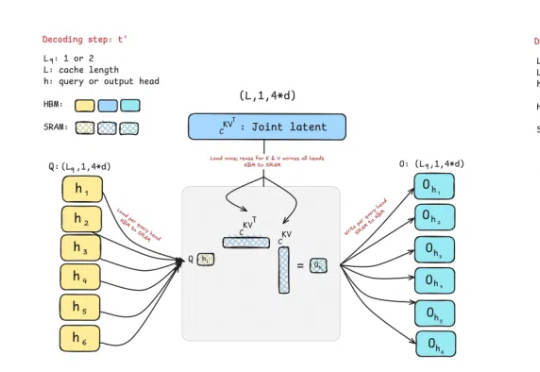
Mamba核心作者新作:取代DeepSeek在用的注意力机制,专为推理打造
Mamba核心作者新作:取代DeepSeek在用的注意力机制,专为推理打造曾撼动Transformer统治地位的Mamba作者之一Tri Dao,刚刚带来新作——提出两种专为推理“量身定制”的注意力机制。
来自主题: AI技术研报
9341 点击 2025-06-02 15:04
 搜索
搜索
曾撼动Transformer统治地位的Mamba作者之一Tri Dao,刚刚带来新作——提出两种专为推理“量身定制”的注意力机制。

研究者针对 few-shot 图像编辑提出一个新的自回归模型结构 ——InstaManip,并创新性地提出分组自注意力机制(group self-attention),在此任务上取得了优异的效果。

北大DeepSeek联合发布的NSA论文,目前已被ACL 2025录用并获得了极高评分,甚至有望冲击最佳论文奖。该技术颠覆传统注意力机制,实现算力效率飞跃,被誉为长文本处理的革命性突破。

最近,人们对AI谈得最多的是deepseek(简称DS)。这匹来自中国本土的黑马,闯入全球视野,一度扰乱美国股市,在 AI 领域掀起了一场轩然大波。
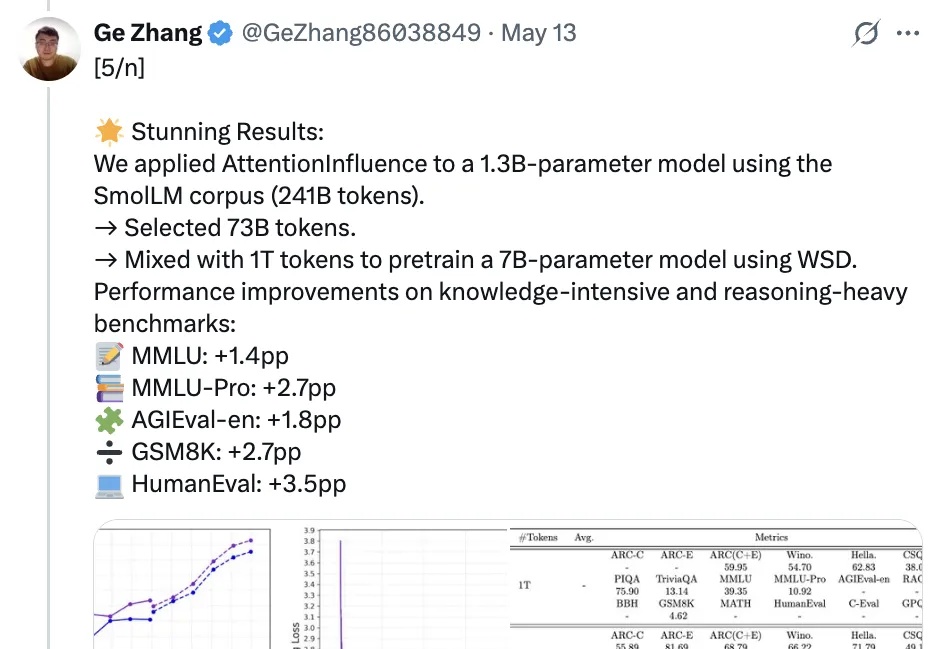
和人工标记数据说拜拜,利用预训练语言模型中的注意力机制就能选择可激发推理能力的训练数据!

大型语言模型(LLMs)在上下文知识理解方面取得了令人瞩目的成功。
ICLR 2025时间检验奖重磅揭晓!Yoshua Bengio与华人科学家Jimmy Ba分别领衔的两篇十年前论文摘得冠军与亚军。一个是Adam优化器,另一个注意力机制,彻底重塑深度学习的未来。
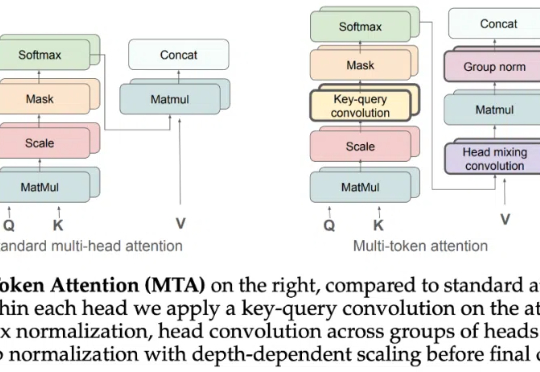
Attention 还在卷自己。

简单的任务,传统的Transformer却错误率极高。Meta FAIR团队重磅推出多token注意力机制(MTA),精准捕捉复杂信息,带来模型性能飞升!

大模型同样的上下文窗口,只需一半内存就能实现,而且精度无损? 前苹果ASIC架构师Nils Graef,和一名UC伯克利在读本科生一起提出了新的注意力机制Slim Attention。