
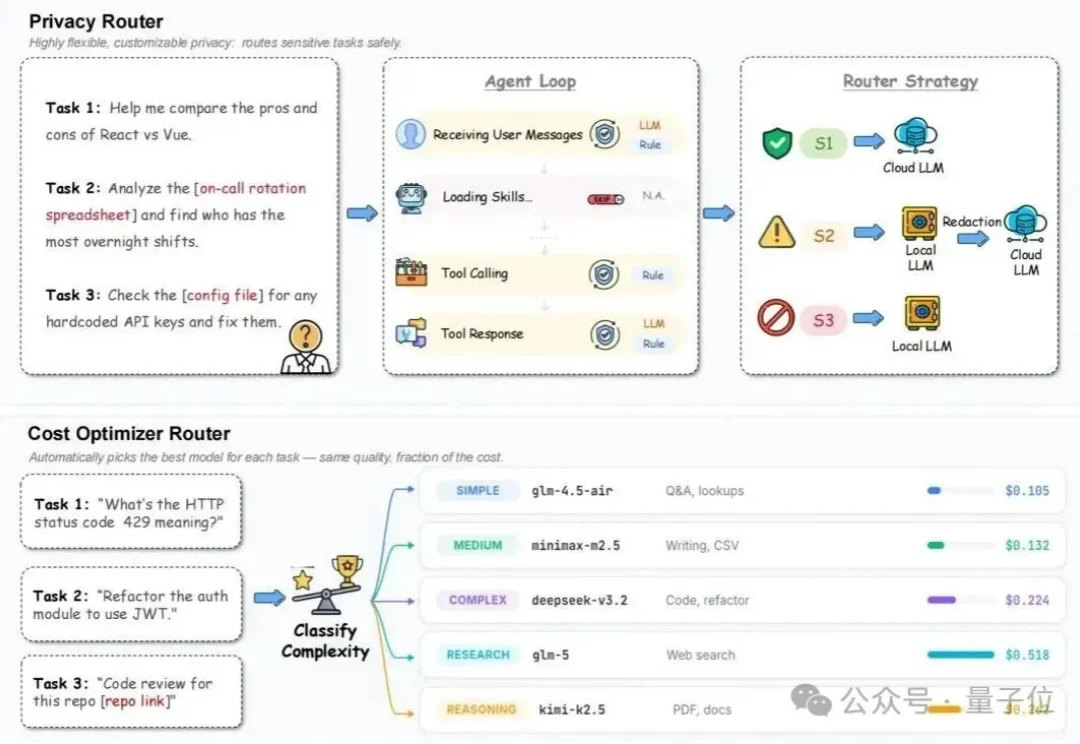
龙虾成本狂降58%!清华人大面壁等最新开源“智能调度员”
龙虾成本狂降58%!清华人大面壁等最新开源“智能调度员”把Agent接入工作流,本该是件提效的乐事。
来自主题: AI技术研报
6534 点击 2026-04-01 17:03
把Agent接入工作流,本该是件提效的乐事。
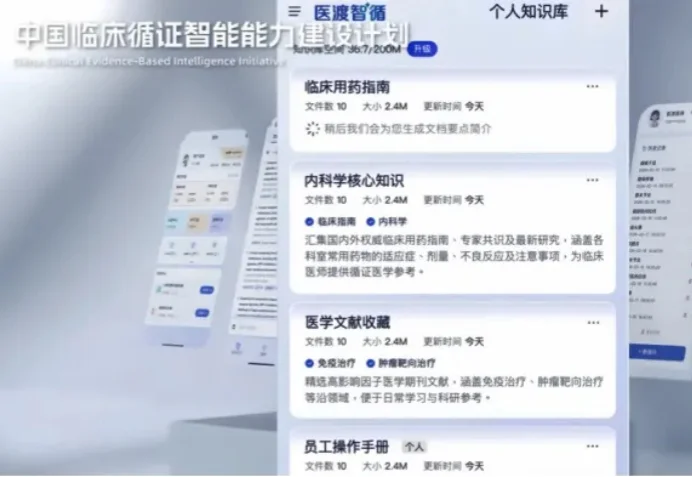
2026中关村论坛上,清华大学附属北京清华长庚医院等多家顶级医疗机构,联合发起国内首个聚焦循证医学与AI深度融合的行业级举措——“中国临床循证智能能力建设计划”。

具身数据层的全球竞赛正在迅速升温。NVIDIA Research在2026年发布EgoScale数据与训练框架,在Ego-centric人类操作视频上训练VLA模型,用 20,854小时带动作标注的第一人称人类视频,观察到数据规模和验证损失之间接近对数线性的scaling law。1X收集人类第一视角及家庭行为数据,通过 Sunday项目采集百万小时级家庭场景视频。
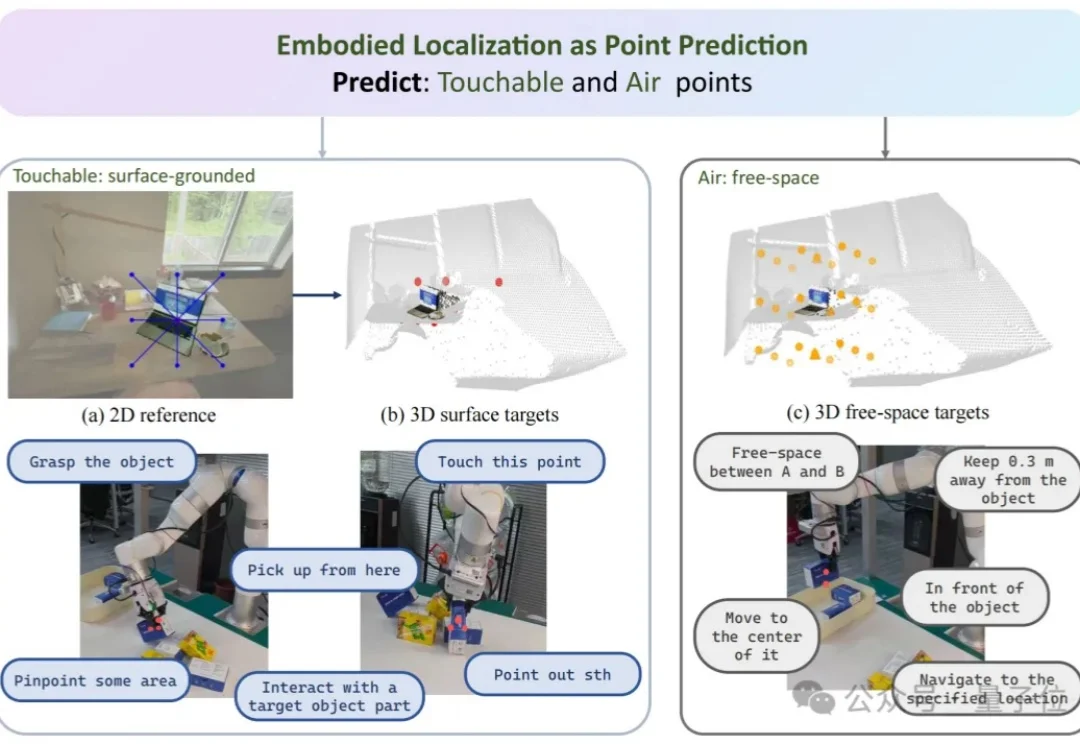
机器人能认出杯子,却看不懂杯口朝哪、离自己多远、该抓哪里。

中关村论坛年会上,医渡科技与清华长庚医院等头部医院共同启动了「中国临床循证智能能力建设计划」,与此同时,作为计划核心技术载体与落地产品的「医渡智循」发布了 APP 版本——一款定位为医生「超级助手、第二大脑、多学科智能体专家顾问团」的临床循证决策系统。
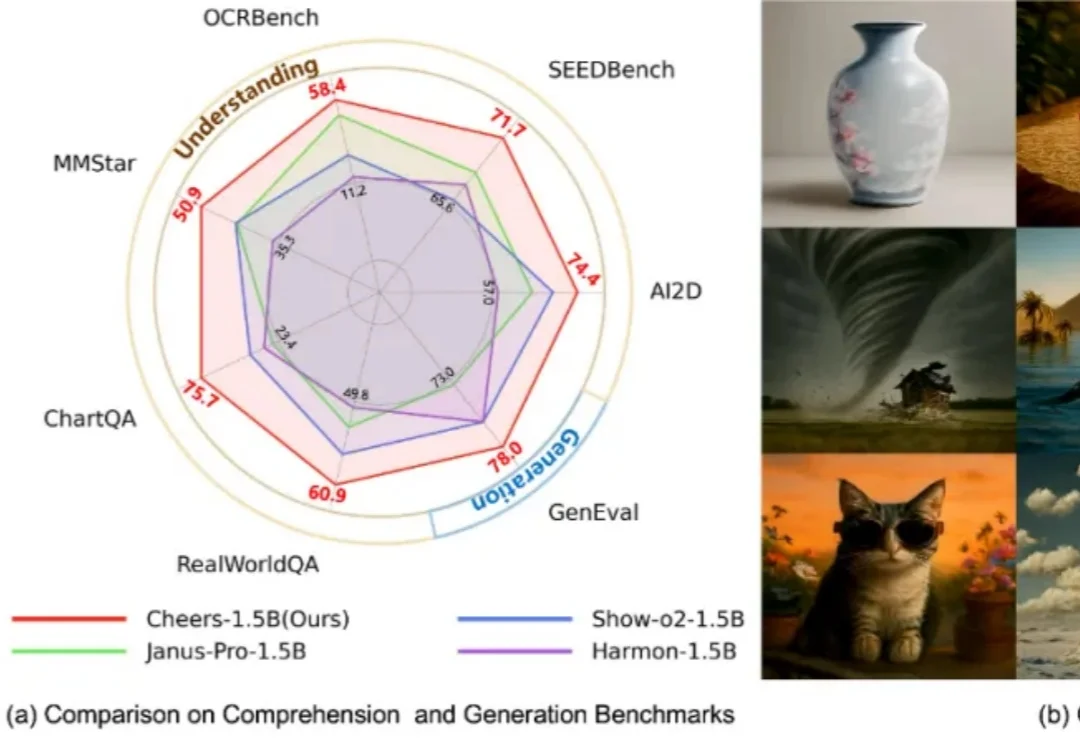
过去几年,多模态模型在理解任务上快速演进,图像问答、OCR、视觉推理、跨模态对话等能力不断提升;与此同时,图像生成模型也在视觉质量、指令遵循和细节表达上持续突破。下一步一个自然的问题是:能否用同一个模型,同时做好理解与生成?这正是统一多模态模型(Unified Multimodal Models, UMMs)正在回答的问题。

想象一下这样的生活片段:你拿起手机 30 秒,屏幕立刻跳出提醒,“当前心率 78,压力中等,建议深呼吸”;家里的智能摄像头静静看着午睡的宝宝,突然通过 App 提醒你:“宝宝心率偏快,呼吸略显急促,建议进屋查看”;养老院里,巡检机器人通过一次擦身而过的对视,便能感知到老人今天情绪低落,且血氧饱和度略低于往常......

近期,围绕「世界模型」这一方向,有两项工作受到较多关注。
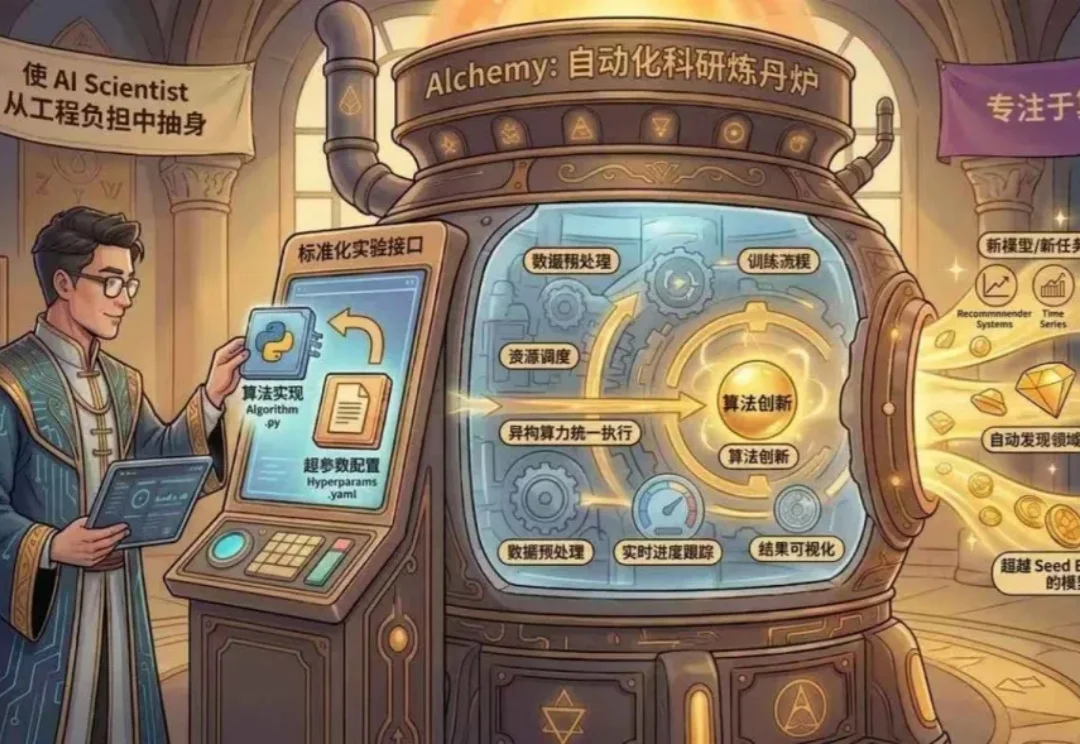
AI 驱动的自动化科研正从概念走向真实系统。近期受到广泛关注的 FARS,以及 Karpathy 开源的 autoresearch,都在不同程度上展示了 AI Scientist 自动进行 AI 领域研究的可行性。
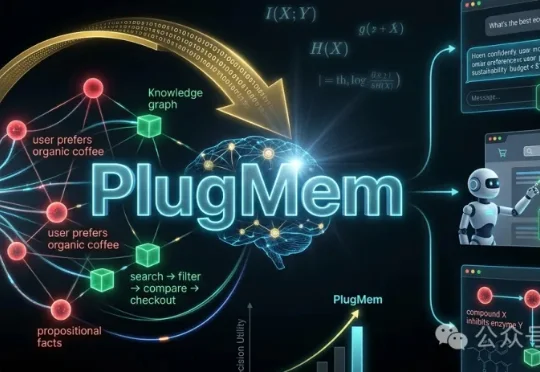
现在的AI agent往往把长交互历史直接存起来,但很难高效复用。最朴素的方法直接从「原始记忆」里检索,但常常把模型淹没在冗长、低价值的上下文里。PlugMem把经验转化为结构化、可复用的知识,并提出一个任务无关(task-agnostic)的统一记忆模块,在多种Agent基准上提升性能,同时消耗更少。