
万字综述遥感AI智能体!六大应用场景全面爆发,地理空间智能从「眼睛」变「大脑」
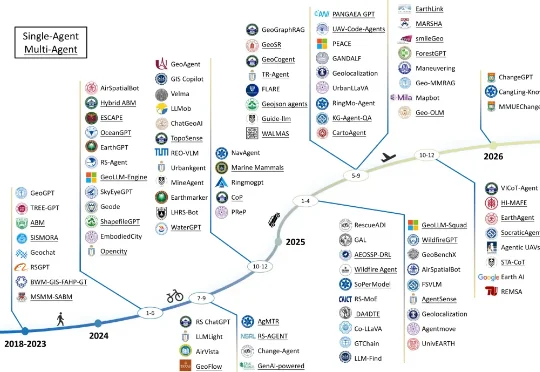
万字综述遥感AI智能体!六大应用场景全面爆发,地理空间智能从「眼睛」变「大脑」如今,一场由 AI 智能体驱动的变革正在发生。近日,来自香港科技大学、西北工业大学、清华大学等多家高校及研究机构的学者联合发布了遥感 AI 智能体领域系统综述。全文逾万字,首次为「遥感智能体」给出了严格定义,系统梳理了其架构、应用、数据集与未来方向。
来自主题: AI技术研报
8135 点击 2026-03-21 09:28
如今,一场由 AI 智能体驱动的变革正在发生。近日,来自香港科技大学、西北工业大学、清华大学等多家高校及研究机构的学者联合发布了遥感 AI 智能体领域系统综述。全文逾万字,首次为「遥感智能体」给出了严格定义,系统梳理了其架构、应用、数据集与未来方向。

「龙虾」实火!最近,清华沈阳教授团队发布了两份最新报告,对OpenClaw做了深度且全面的解读。

中国教育界的OpenClaw来了!刚刚,清华教育学院、计算机系联合团队正式开源多智能体AI课堂OpenMAIC:AI老师语音授课,AI同学举手讨论,交互式课程一键生成。

最近科技圈最火的话题,非「养龙虾」莫属。
一支来自清华、哈佛的团队坐不住了。他们觉得:AI越强,理应越可控,而不是越难伺候。他们搞出了全球首个可操控AI平台MorphMind,直接把AI从一个黑箱对话框,改造成了一套可以被人随时干预的工作系统。比起简单快速拿到一个答案,在这里你直接稳拿顶级霸总剧本,运筹帷幄,操盘整支AI专家团,与他们并肩作战。

空间 Agentic AI 公司 Fullive.AI,成立1个月内连续完成种子轮、种子+轮融资,由高瓴创投、慕华科创、智元机器人、北大苏南研究院与多家产业加持方共同投资,多维资本担任本轮融资财务顾问。本轮资金将用于 Bio-OS 空间 AI Agent的迭代、首款睡眠空间 AI 硬件的研发,以及 AI 生态建设。

随着大语言模型 Agent 开始在对话、问答与复杂交互环境中长期运行,“记忆该如何设计” 正在成为一个绕不开的核心问题。
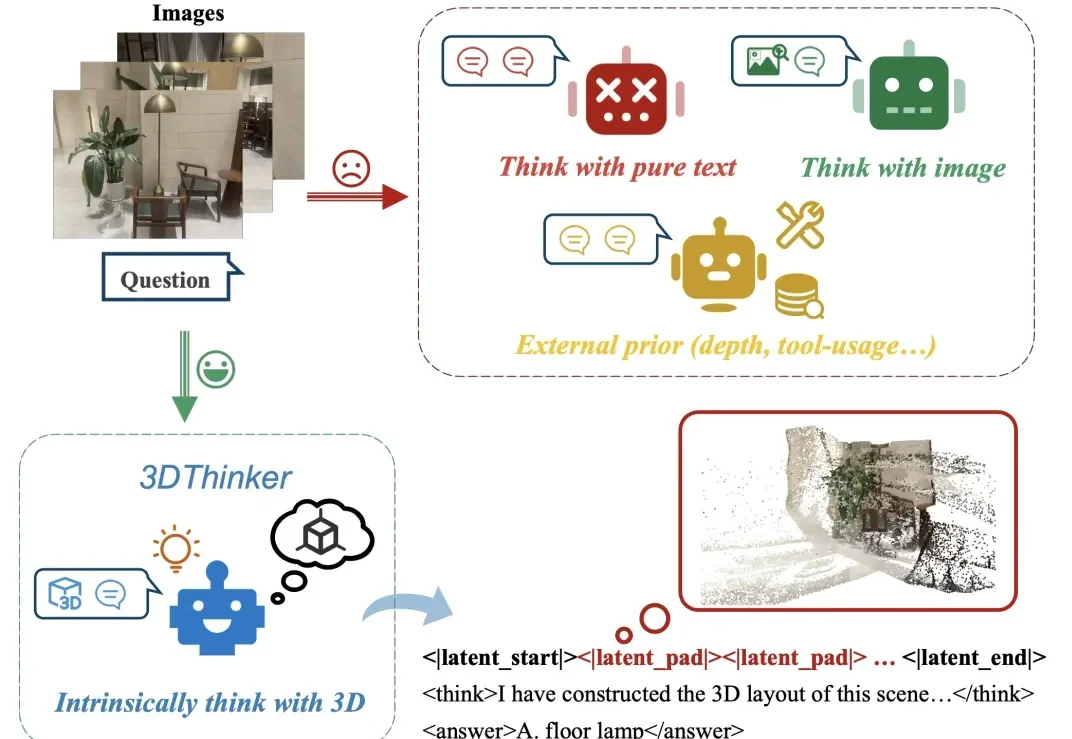
大家是否有这样的感觉?给定几张场景中拍摄的图片,往往能够在脑海中想象出这个场景的三维布局,然而当前的多模态大模型还停留于纯文本或者 2D 视觉的推理表示,限制了图像中隐含几何结构的表达能力。

是不是经常纠结于 VLA(视觉 - 语言 - 动作)模型的训练技巧?面对层出不穷的 VLA 算法,是不是常常感到眼花缭乱,不知道哪种数据模态、训练策略最有效? 别急,丰田研究院(TRI)和清华大学刚刚

AI 本质不是工具升级,而是生产关系的重塑。