
清华万引教授:万倍加速催化剂设计,AI突破DFT瓶颈!
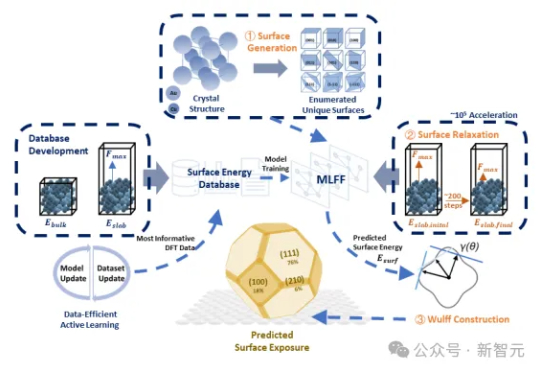
清华万引教授:万倍加速催化剂设计,AI突破DFT瓶颈!传统DFT计算太慢?SurFF来了!这个基础模型通过晶面生成、快速弛豫和Wulff构型,精准评估晶面可合成性与暴露度。SurFF相较于DFT实现了10⁵倍的加速,多源实验与文献验证一致率达73.1%。
来自主题: AI技术研报
7724 点击 2025-10-12 10:43
传统DFT计算太慢?SurFF来了!这个基础模型通过晶面生成、快速弛豫和Wulff构型,精准评估晶面可合成性与暴露度。SurFF相较于DFT实现了10⁵倍的加速,多源实验与文献验证一致率达73.1%。
清华物理系传奇特奖得主姚顺宇离职Anthropic,正式加盟谷歌DeepMind!他在Anthropic仅工作一年,离职原因中约40%与公司「价值观」不合。他指出现阶段AI研究如同17世纪热力学探索:虽缺乏完整理论,却充满规律发现的契机。
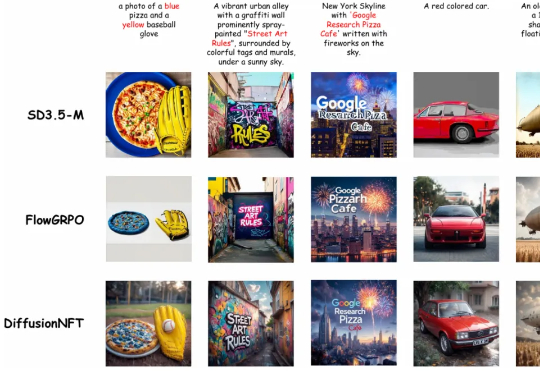
清华大学朱军教授团队,NVIDIA Deep Imagination 研究组与斯坦福 Stefano Ermon 团队联合提出了一种全新的扩散模型强化学习(RL)范式 ——Diffusion Negative-aware FineTuning (DiffusionNFT)。该方法首次突破现有 RL 对扩散模型的基本假设,直接在前向加噪过程(forward process)上进行优化
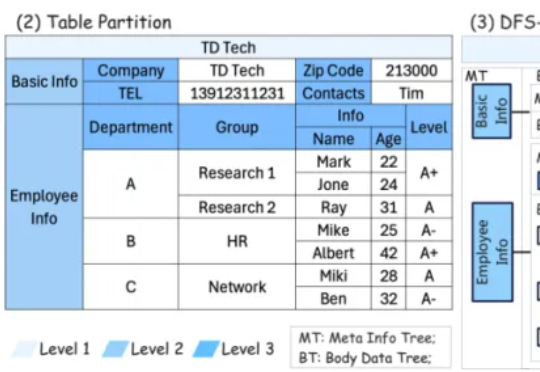
来自上海交通大学计算机学院、西蒙菲莎大学、清华大学、中国人民大学的合作团队,带来基于树形框架的智能表格问答系统(ST-Raptor),其不仅能精准捕捉表格中的复杂布局,还能自动生成表格操作指令,并一步步执行这些操作流程,最终准确回答用户提出的问题 —— 就像给 Excel 装上了一个会思考的 “AI 大脑”。

一个月前,我们曾报道过清华姚班校友、普林斯顿教授陈丹琦似乎加入 Thinking Machines Lab 的消息。有些爆料认为她在休假一年后,会离开普林斯顿,全职加入 Thinking Machines Lab。
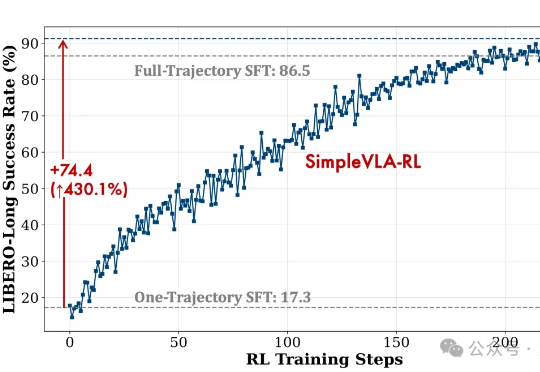
视觉-语言-动作模型是实现机器人在复杂环境中灵活操作的关键因素。然而,现有训练范式存在一些核心瓶颈,比如数据采集成本高、泛化能力不足等。

清华互联网产品研究协会(五道口产品观察)联合特工宇宙,从现状痛点到落地实践,再到职业进化路径,万字白皮书拆解 AI 与产品工作的适配方式,助力突破 AI 使用困局。
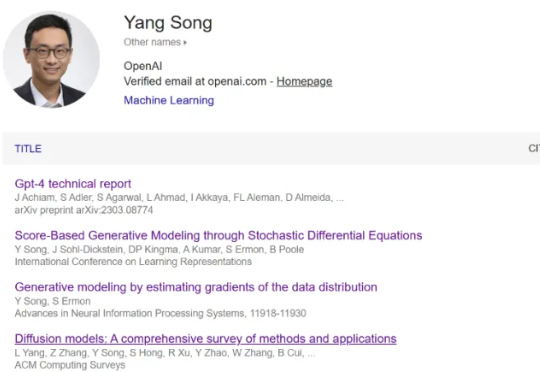
扎克伯格又从 OpenAI 挖走了一位华人科学家,而且这位称得上是「超级大脑」。本周四午间传来消息,原 OpenAI 战略探索团队负责人宋飏(Yang Song)加入 Meta,他成为了新成立的 Meta 超级智能实验室(MSL)研究负责人。

医学研究迎来“零人工”时代了?!清华大学自动化系索津莉课题组,发布首个专为医疗信息学设计的全自主AI研究框架——OpenLens AI。首次实现从文献挖掘→实验设计→数据分析→代码生成→可投稿论文的全链条自动化闭环。
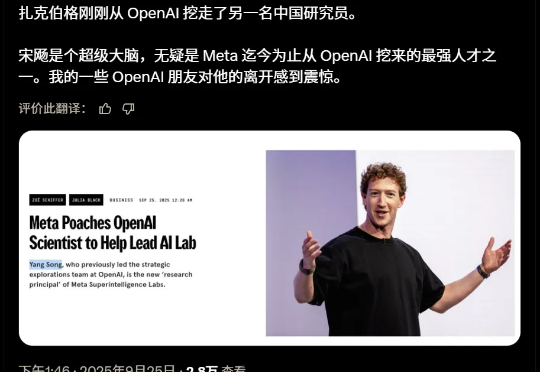
刚刚,Meta又从OpenAI挖来一员猛将——宋飏,扩散模型领域的核心人物,DALL·E 2技术路径的早期奠基者。他已正式加入Meta Superintelligence Labs,担任研究负责人,直接向他的师兄赵晟佳汇报。