

让具身智能体拥有「空间感」!清华、北航联合提出类脑空间认知框架,导航、推理、做早餐样样精通
让具身智能体拥有「空间感」!清华、北航联合提出类脑空间认知框架,导航、推理、做早餐样样精通这并非科幻片中的桥段,而是来自清华大学与北京航空航天大学团队的最新成果——BSC-Nav 的真实演示。通过模仿生物大脑构建、维护空间记忆的原理,研究团队让智能体拥有了前所未有的「空间感」。
来自主题: AI技术研报
8319 点击 2025-09-05 11:31
这并非科幻片中的桥段,而是来自清华大学与北京航空航天大学团队的最新成果——BSC-Nav 的真实演示。通过模仿生物大脑构建、维护空间记忆的原理,研究团队让智能体拥有了前所未有的「空间感」。
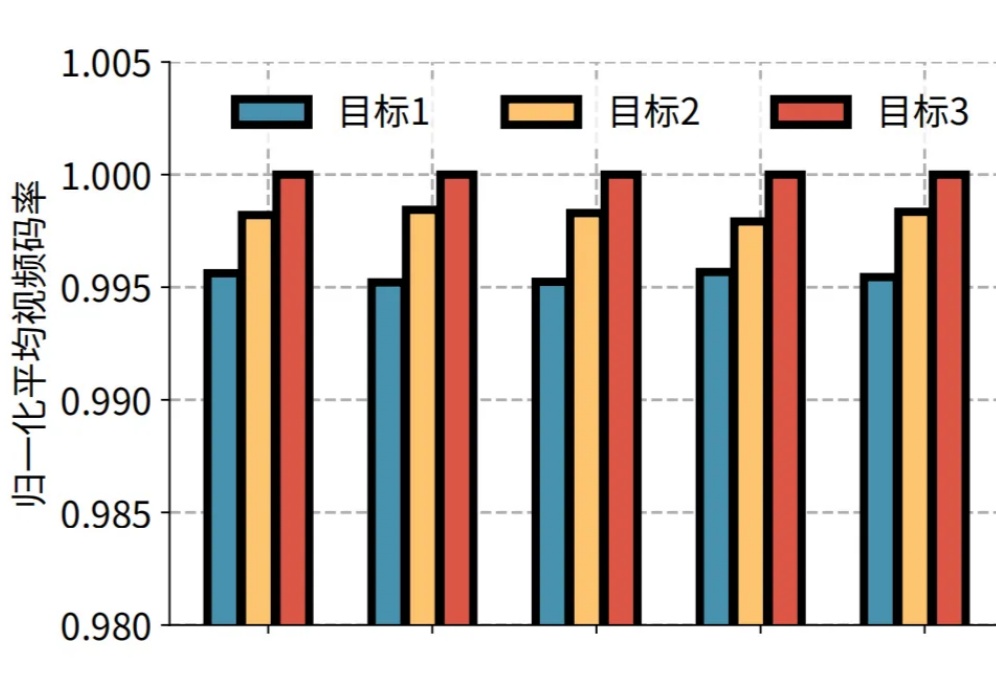
近日,快手与清华大学孙立峰团队联合发表论文《Towards User-level QoE: Large-scale Practice in Personalized Optimization of Adaptive Video Streaming》,被计算机网络领域的国际顶尖学术会议 ACM SIGCOMM 2025 录用。
清华大学、北京中关村学院、无问芯穹联合北大、伯克利等机构重磅开源RLinf:首个面向具身智能的“渲训推一体化”大规模强化学习框架。

这位乒乓球场上的机器人高手,出自清华姚班本科生苏智(师从吴翼教授)的最新论文——《HITTER: A HumanoId Table TEnnis Robot via Hierarchical Planning and Learning》。
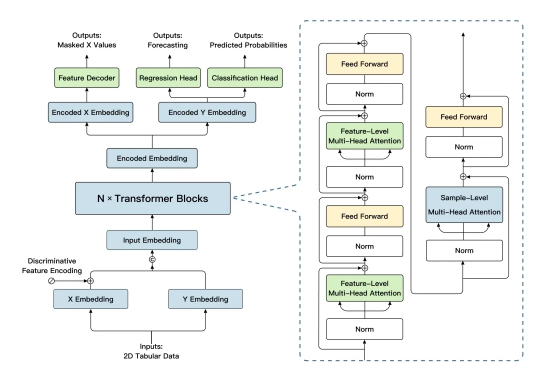
2025 年 8 月 29 日,由清华大学计算机系崔鹏教授团队联合稳准智能共同研发的结构化数据通用大模型「极数」(LimiX)正式宣布开源。
又一个AI学术大佬,有工业界身份了。 清华姚班校友、普林斯顿教授陈丹琦,跟Thinking Machines划上了关联。
AI加速走向落地,企业「超级大脑」却在关键时刻断片?行业亟需一套能够持续进化、越用越聪明的系统框架,实现多智能体协同作战,通过自优化、自反馈瞬间激活知识库。清华系黑马已将其塞进AI原生引擎,率先在能源、军工等硬核场景中规模化落地,为产业智能升级提供了可靠路径。
如果我们的教科书里包含大量的污言秽语,那么我们能学好语言吗?这种荒唐的问题却出现在最先进 ChatGPT 系列模型的学习过程中。

姚班、伯克利、OpenAI、清华……年仅 30 多岁的吴翼身上已经聚集了众多亮眼的标签。

AI作画、生视频,可以「自己救自己」了?! 当大家还在为CFG(无分类器引导)的参数搞到头秃,却依然得到一堆“塑料感”废片而发愁时,来自清华大学、阿里巴巴AMAP(高德地图)、中国科学院自动化研究所的研究团队,推出全新方法S²-Guidance (Stochastic Self-Guidance)。