
用 SurveyGO,像清华团队一样无痛做科研!
用 SurveyGO,像清华团队一样无痛做科研!写论文是许多学生面临的共同难题,尤其是在文献的收集与高效利用上。
来自主题: AI技术研报
8080 点击 2025-04-23 15:19
写论文是许多学生面临的共同难题,尤其是在文献的收集与高效利用上。
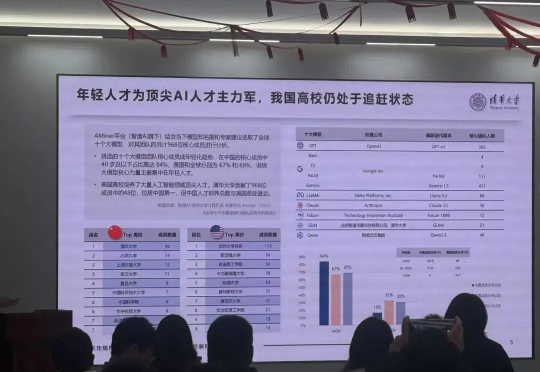
为什么不能这样
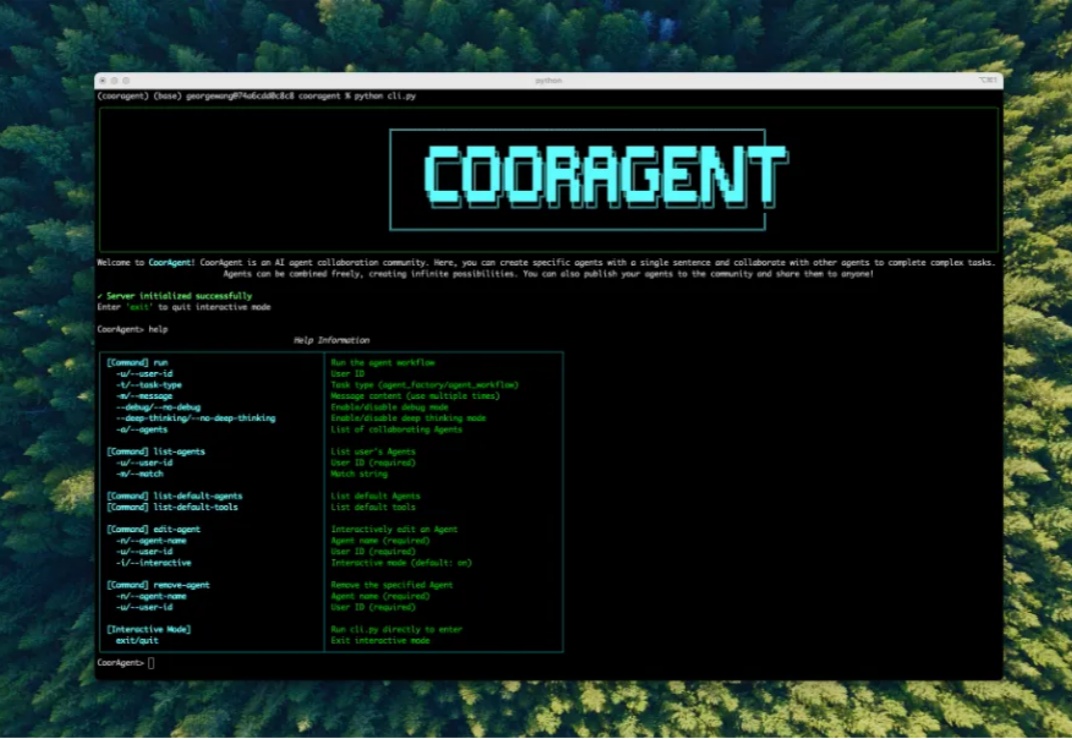
刚刚,清华大模型团队 LeapLab 发布了一款面向 Agent 协作的开源框架:Cooragent。

Adam优化器是深度学习中常用的优化算法,但其性能背后的理论解释一直不完善。近日,来自清华大学的团队提出了RAD优化器,扩展了Adam的理论基础,提升了训练稳定性。实验显示RAD在多种强化学习任务中表现优于Adam。
新国产AI视频生成模型横空出世,一夜间全网刷屏。Magi-1,首个实现顶级画质输出的自回归视频生成模型,模型权重、代码100%开源。整整61页的技术报告中还详细介绍了创新的注意力改进和推理基础设施设计,给人一种视频版DeepSeek的感觉。

Hyper-RAG利用超图同时捕捉原始数据中的低阶和高阶关联信息,最大限度地减少知识结构化带来的信息丢失,从而减少大型语言模型(LLM)的幻觉。

北京时间4月16日,据彭博社报道,英伟达周二在监管文件中表示,美国政府已于周一通知公司,H20芯片未来在出口至中国时需要“无限期”申请许可证。

港中文和清华团队推出Video-R1模型,首次将强化学习的R1范式应用于视频推理领域。通过升级的T-GRPO算法和混合图像视频数据集,Video-R1在视频空间推理测试中超越了GPT-4o,展现了强大的推理能力,并且全部代码和数据集均已开源。
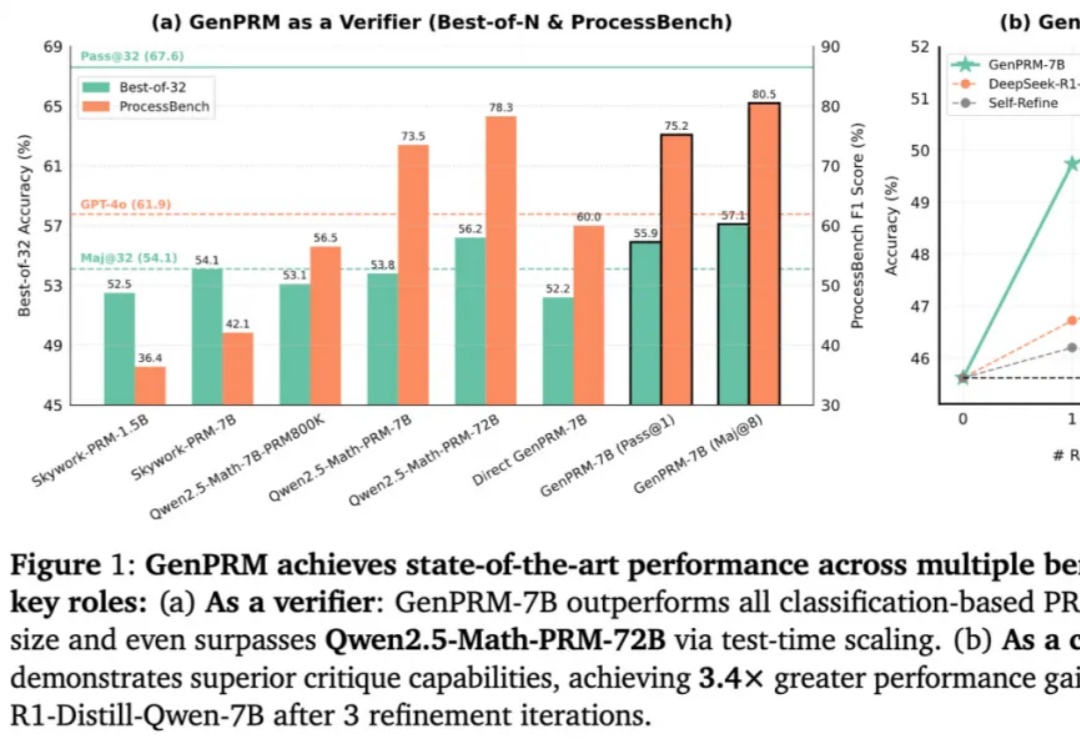
随着 OpenAI o1 和 DeepSeek R1 的爆火,大语言模型(LLM)的推理能力增强和测试时扩展(TTS)受到广泛关注。然而,在复杂推理问题中,如何精准评估模型每一步回答的质量,仍然是一个亟待解决的难题。传统的过程奖励模型(PRM)虽能验证推理步骤,但受限于标量评分机制,难以捕捉深层逻辑错误,且其判别式建模方式限制了测试时的拓展能力。

在大模型争霸的时代,算力与效率的平衡成为决定胜负的关键。