

SOTA自动绑骨开源框架来了!3D版DeepSeek-UniRig开源月大礼包持续开箱ing
SOTA自动绑骨开源框架来了!3D版DeepSeek-UniRig开源月大礼包持续开箱ing面向3D生成,来自VAST和清华大学的自动绑骨框架开源了!3D内容创作领域正经历前所未有的爆发,无论是成熟的传统工作流,还是以VAST(Tripo)为代表的AI驱动生成工具的飞速发展,都体现了市场对高质量3D资产需求的日益激增
来自主题: AI资讯
9450 点击 2025-04-12 10:47
面向3D生成,来自VAST和清华大学的自动绑骨框架开源了!3D内容创作领域正经历前所未有的爆发,无论是成熟的传统工作流,还是以VAST(Tripo)为代表的AI驱动生成工具的飞速发展,都体现了市场对高质量3D资产需求的日益激增

港中文、清华等高校提出SICOG框架,通过预训练、推理优化和后训练协同,引入自生成数据闭环和结构化感知推理机制,实现模型自我进化,为大模型发展提供新思路。

随着 VR/AR、游戏娱乐、自动驾驶等领域对 3D 场景生成的需求不断攀升,从稀疏视角重建 3D 场景已成为一大热点课题。

2025 CSRankings新鲜出炉了!CMU稳坐全球第一,中国高校强势崛起,清华摘得第2,上交大与浙大并列第3,北大位居第5。中国在AI领域表现尤为抢眼,上交大、清华、北大、浙大包揽前四,中国科学院与哈工大也跻身全球前十。
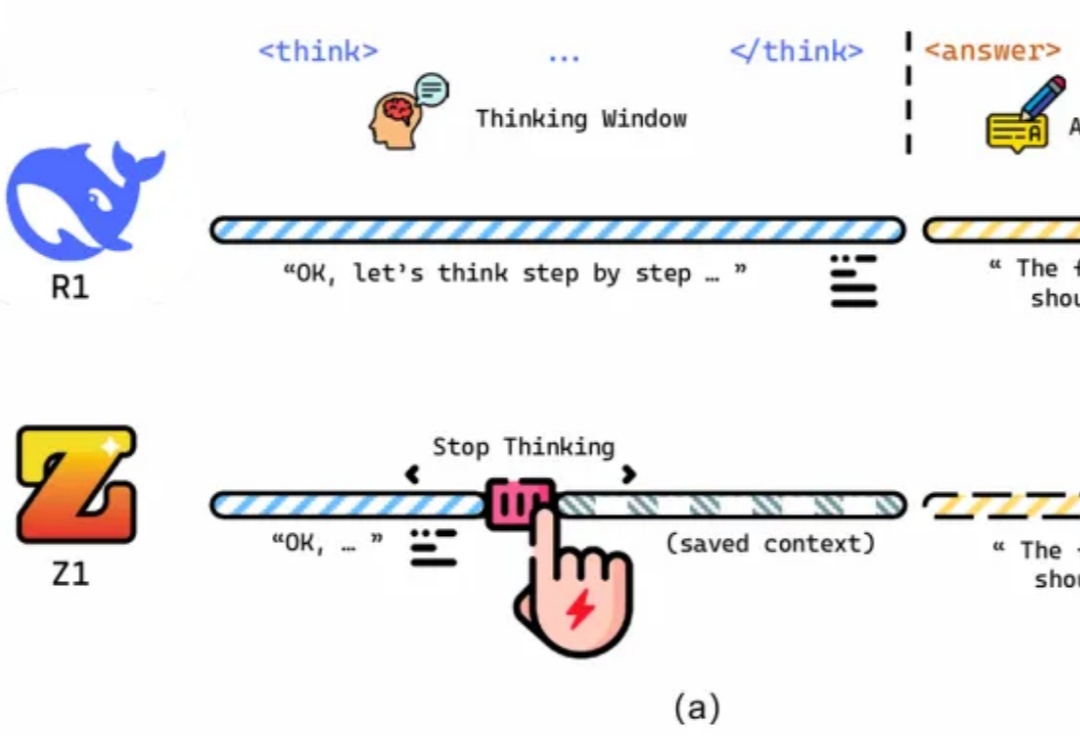
推理性能提升的同时,还大大减少Token消耗!

DeepSeek新论文来了!在清华研究者共同发布的研究中,他们发现了奖励模型推理时Scaling的全新方法。DeepSeek R2,果然近了。

2025中关村论坛人工智能主题日,高能不断。清华系团队全新Vidu Q1视频生成可控性再创新高,炫目demo惊艳全场。图灵奖得主Joseph Sifakis、清华朱军、百度王海峰等大咖演讲,更是将论坛推向专业的巅峰。

4D LangSplat通过结合多模态大语言模型和动态三维高斯泼溅技术,成功构建了动态语义场,能够高效且精准地完成动态场景下的开放文本查询任务。该方法利用多模态大模型生成物体级的语言描述,并通过状态变化网络实现语义特征的平滑建模,显著提升了动态语义场的建模能力。
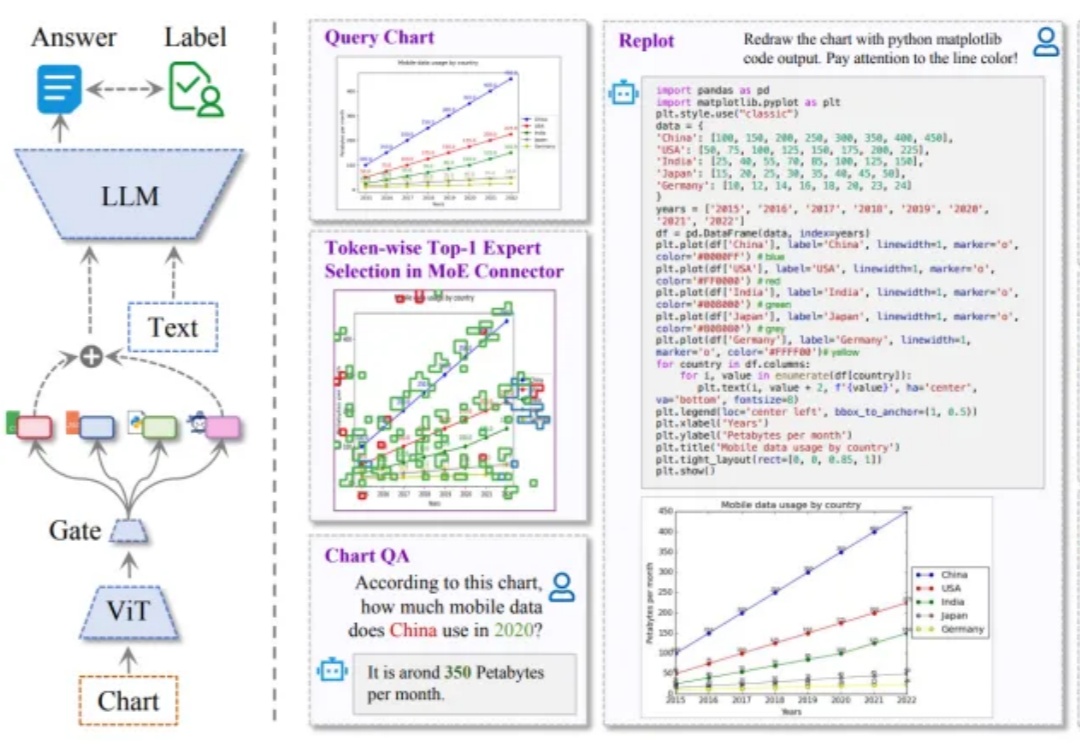
最近,全球 AI 和机器学习顶会 ICLR 2025 公布了论文录取结果:由 IDEA、清华大学、北京大学、香港科技大学(广州)联合团队提出的 ChartMoE 成功入选 Oral (口头报告) 论文。据了解,本届大会共收到 11672 篇论文,被选中做 Oral Presentation(口头报告)的比例约为 1.8%
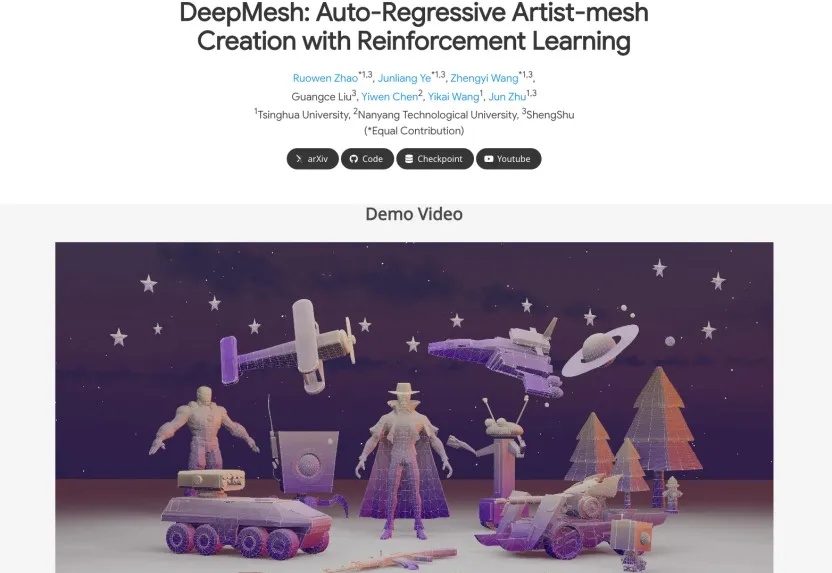
在三维数字内容生产领域,三角形网格作为核心的几何表示形式,其质量直接影响虚拟资产在影视、游戏和工业设计等应用场景中的表现与效率。