200美金,人人可手搓QwQ,清华、蚂蚁开源极速RL框架AReaL-boba
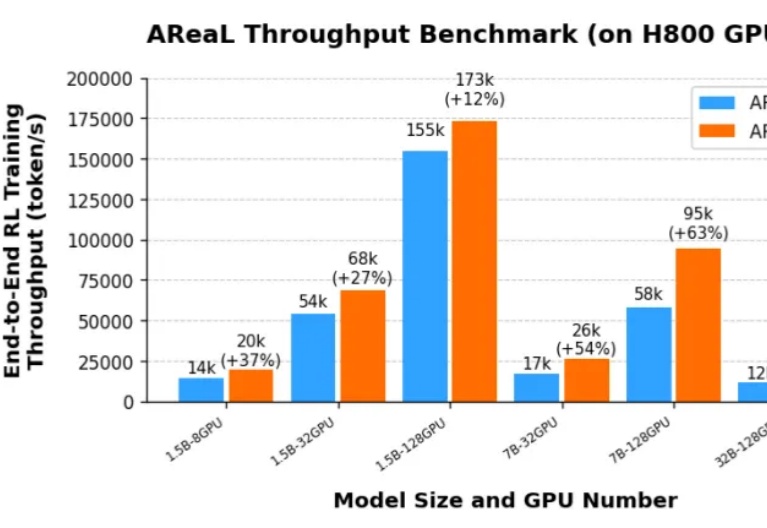
200美金,人人可手搓QwQ,清华、蚂蚁开源极速RL框架AReaL-boba由于 DeepSeek R1 和 OpenAI o1 等推理模型(LRM,Large Reasoning Model)带来了新的 post-training scaling law,强化学习(RL,Reinforcement Learning)成为了大语言模型能力提升的新引擎。然而,针对大语言模型的大规模强化学习训练门槛一直很高:
来自主题: AI技术研报
11460 点击 2025-03-31 15:07