
张涛首次回应争议,Manus 为什么没有被替代?
张涛首次回应争议,Manus 为什么没有被替代?11 月 30 日,真格举办了一场关于 AI 创业的分享活动。真格管理合伙人戴雨森与 Kimi 总裁张予彤、与爱为舞创始人张怀亭、Manus 联合创始人张涛一同走进清华大学,带来了一场关于创新与未来的深度对谈
来自主题: AI资讯
9264 点击 2025-12-14 10:46
11 月 30 日,真格举办了一场关于 AI 创业的分享活动。真格管理合伙人戴雨森与 Kimi 总裁张予彤、与爱为舞创始人张怀亭、Manus 联合创始人张涛一同走进清华大学,带来了一场关于创新与未来的深度对谈
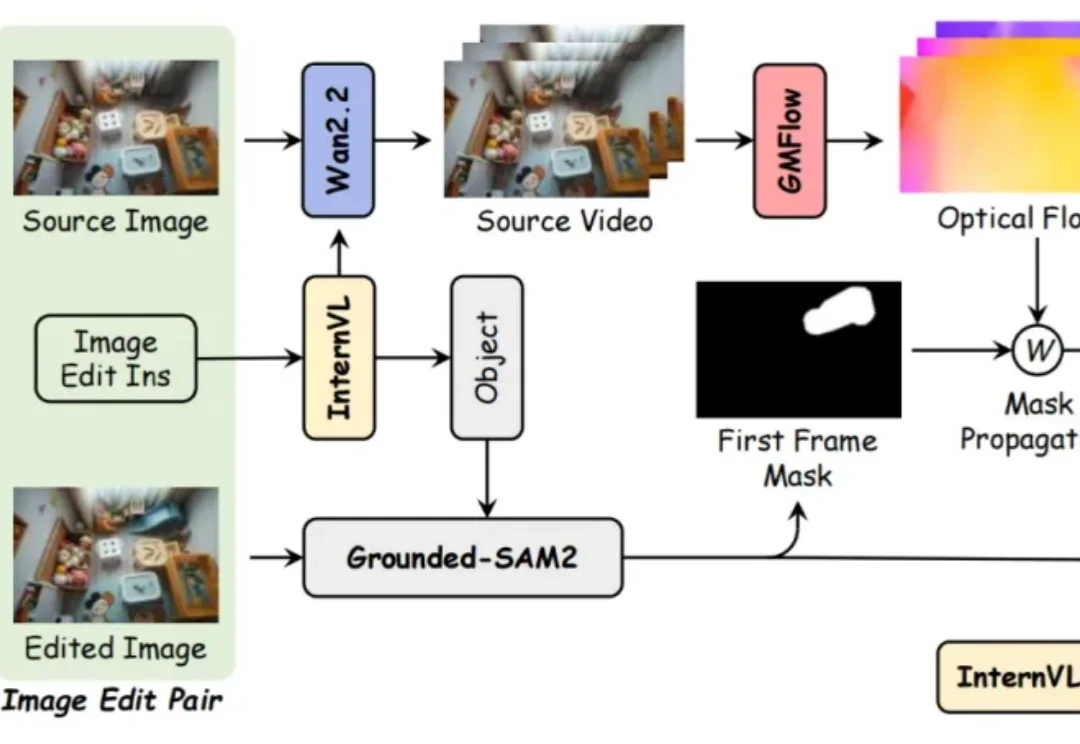
近年来,基于扩散的视频生成模型的最新进展极大地提高了视频编辑的真实感和可控性。然而,文字驱动的视频对象移除添加依然面临巨大挑战:

NeurIPS 2025见证了历史性的分流:清华大学以微弱差距逼近谷歌,中国AI完成了从数量堆叠向底层架构创新的「质变」突围。在圣地亚哥与墨西哥城的双会场之间,签证壁垒切割了物理空间。这是一场关于算力、人才与技术定义权的「双城记」。

近日,张予彤意外出现在清华大学的一场交流会上。投资界从接近Kimi人士了解到,张予彤已经出任月之暗面总裁一职,“负责公司的整体战略与商业化,包括融资,也会参与一些新产品的开发。”
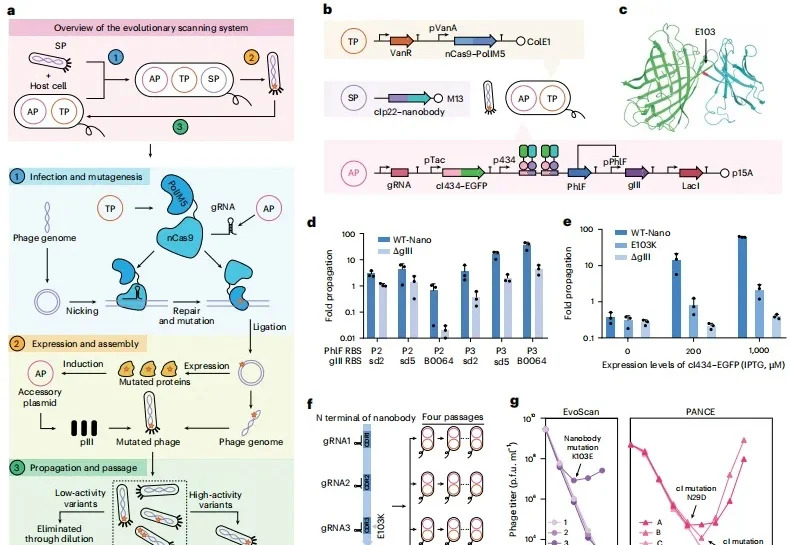
从去年到今年,清华大学教授张数一和团队连着两个冬天做出两个“AI+蛋白质”成果,它们分别是极速压缩与智能重建蛋白质序列空间的 EvoAI,以及能够 24 小时昼夜不停、全自动进化蛋白质的 iAutoEvoLab 工厂。相关论文分别发表于 Nature Methods 和 Nature Chemical Engineering。
关于如何避免让大语言模型产生幻觉,一直以来的相关研究都非常多。

来自中国的初创团队词元无限给出了自己的答案。由清华姚班校友带队设计开发的编码智能体 InfCode,在 SWE-Bench Verified 和 Multi-SWE-bench-CPP 两项非常权威的 AI Coding 基准中双双登顶,力压一众编程智能体。
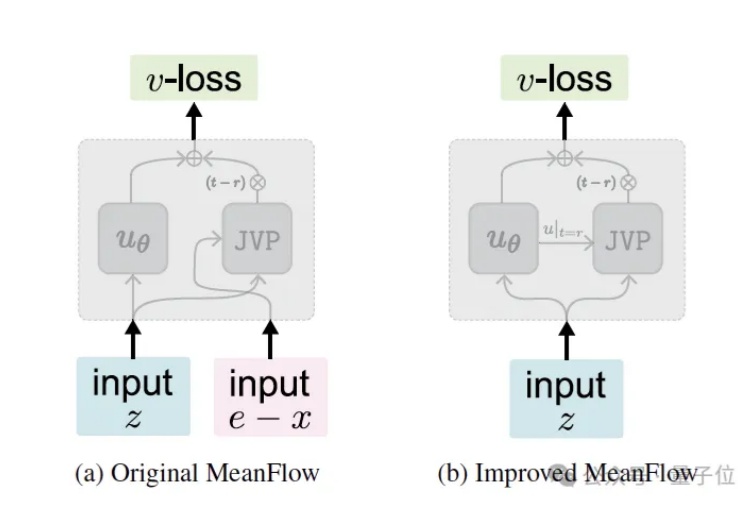
继今年5月提出MeanFlow (MF) 之后,何恺明团队于近日推出了最新的改进版本—— Improved MeanFlow (iMF),iMF成功解决了原始MF在训练稳定性、指导灵活性和架构效率上的三大核心问题。

叶问蹲、跳舞、跑步,一个策略全搞定!

近日,清华大学深圳国际研究生院的机器人博士团队创办的「知有无界」获得卓源亚洲领投、力合科创跟投的种子轮融资。「知有无界」诞生在清华大学王学谦教授的智能机器人实验室,实现了全球首个船舶具身通用大模型,本轮融资后,「知有无界」将会进一步加快在船坞的商业化落地,并持续进行多代产品的研发。