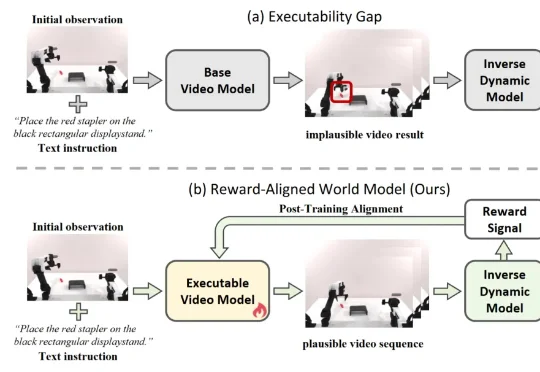
Z Tech|师从何恺明,专访 MIT 博士生邓明扬:从 IMO 金牌、IOI 满分的竞赛少年到生成模型研究者
Z Tech|师从何恺明,专访 MIT 博士生邓明扬:从 IMO 金牌、IOI 满分的竞赛少年到生成模型研究者邓明扬现为 MIT 博士生,师从何恺明,主要研究生成模型。本科期间,他在 MIT 学习数学与计算机科学,也曾在 DeepMind 和 Meta 实习。更早之前,他曾获得 IMO 金牌和 IOI 金牌。2026 年,他以第一作者发表了 Drifting Models,尝试探索一种不同于传统路径的生成建模思路。
来自主题: AI资讯
8232 点击 2026-04-21 16:52