小云雀短剧Agent升级2.0,我花200元就做了一部AI版的《给阿嬷的情书》
小云雀短剧Agent升级2.0,我花200元就做了一部AI版的《给阿嬷的情书》近日,字节旗下AI视频创作工具小云雀的短剧Agent正式更新到2.0版本。自Seedance 2.0这一视频生成模型横空出世以来,小云雀一直是其原生支持的平台。由于整体使用门槛相对较低,小云雀也逐渐积累起一批AI短剧和AI短片创作者。
来自主题: AI资讯
12106 点击 2026-05-29 15:28
 搜索
搜索
近日,字节旗下AI视频创作工具小云雀的短剧Agent正式更新到2.0版本。自Seedance 2.0这一视频生成模型横空出世以来,小云雀一直是其原生支持的平台。由于整体使用门槛相对较低,小云雀也逐渐积累起一批AI短剧和AI短片创作者。

当下视频生成模型正在快速逼近真实世界的画面质感,但一个现实瓶颈也越来越突出—— 那就是分辨率越高,生成所需要的时间就越长。

VeRL-Omni 是一个面向多模态生成模型的通用 RL 后训练框架,由 VeRL-Omni 团队在 verl 与 vllm-omni 之上构建。覆盖扩散 transformer(Qwen-Image)、混合 AR-DiT(Qwen-Omni)、统一理解 + 生成(BAGEL、HunyuanImage-3.0)等架构。
就在今天,美团龙猫大模型团队突然开源了商用级数字人视频生成模型 LongCat-Video-Avatar 1.5。在权威评测中,它的用户偏好胜率全面超越 Kling Avatar 2.0、OmniHuman-1.5 和 HeyGen 这三个头部玩家,并且直接以 MIT 协议开放,连商用限制都懒得设。
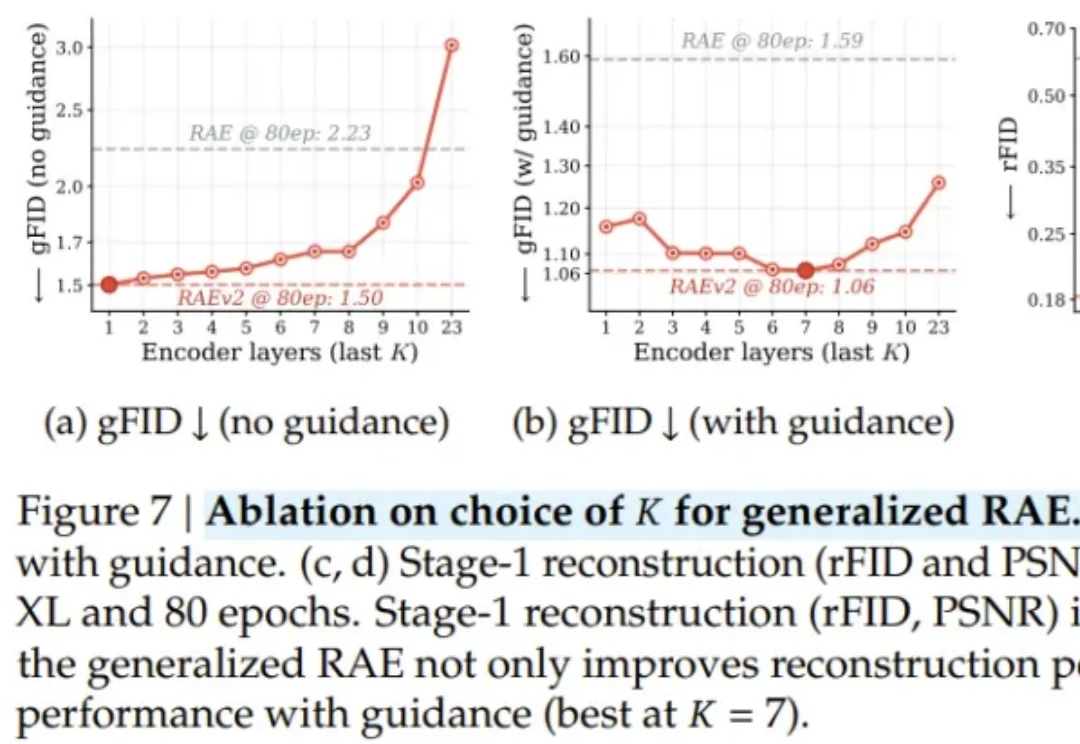
AI 图像生成通常遵循「能力越强、代价越高」的铁律;与此同时,学界却在悄悄质疑另一个更根本的浪费:传统 VAE 对图像语义几乎一无所知,而 DINOv2、SigLIP 等视觉编码器早已从数亿张图片中习得了丰富的视觉常识。图像生成模型,真的需要从零开始「发明」对图像的理解吗?
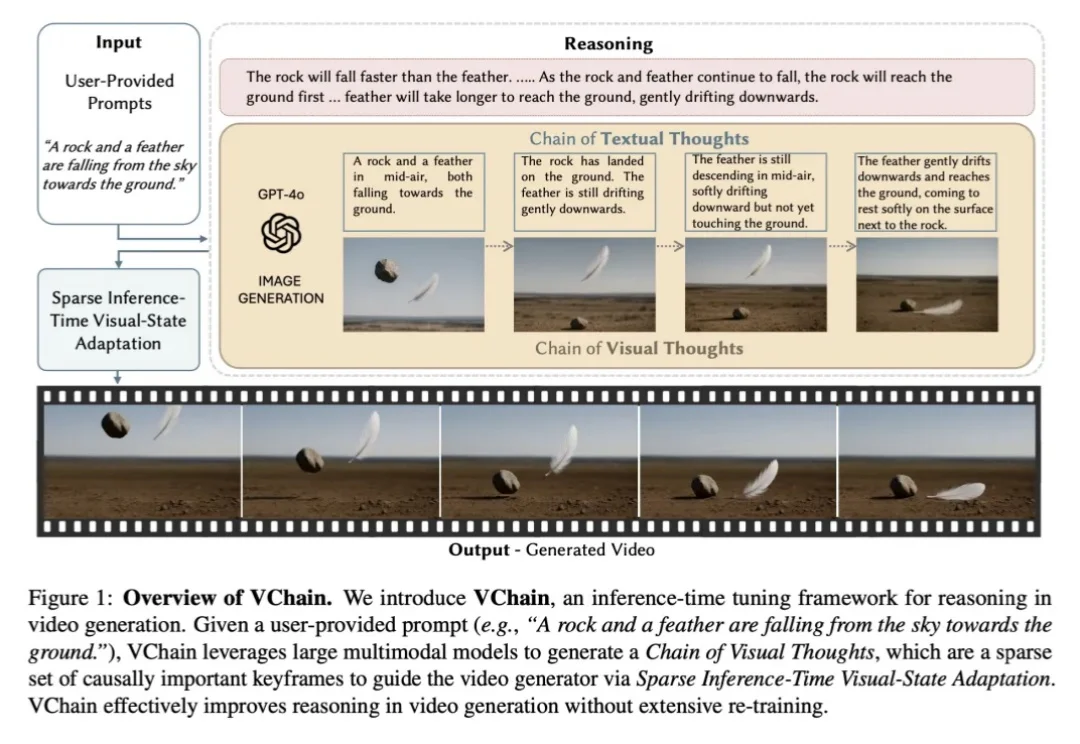
当视频生成模型在视觉保真度上不断突破时,一个核心瓶颈正变得愈发清晰:模型是否真正理解了真实世界?能否推理出合理的演变过程?
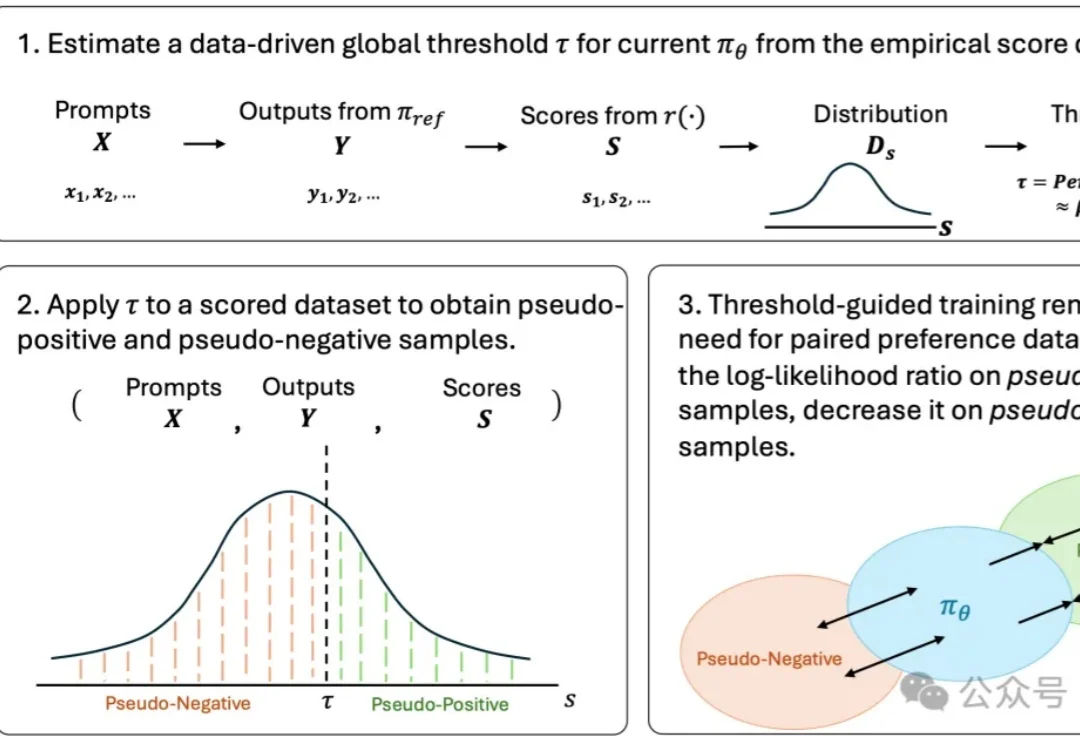
生成模型的偏好对齐,可能正在进入一个新的阶段。

浙大联合微软亚洲研究院最新提出的World-R1,不改架构、不要3D数据,纯靠强化学习就让视频生成模型学会了“理解”三维世界。World-R1 的出发点很简单:预训练的视频模型里面已经有 3D 知识了,只是“沉睡”着。用强化学习把它叫醒就行。
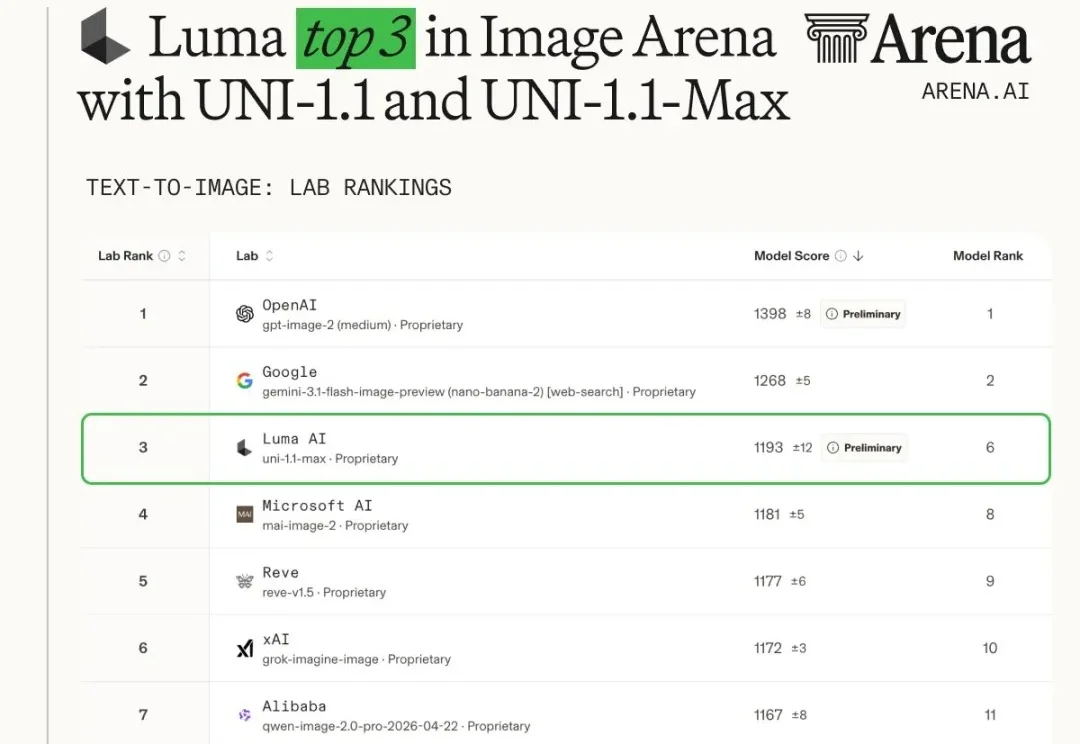
今年以来,图像生成模型的迭代节奏明显加快。
做过 AI 视频的都懂,除了 Seedance 2.0 本身的高定价,废片所烧掉的 token 算力也是一笔不小的开支。但在 Topview 平台,直接把这笔最大试错成本给重新定义了!热门视频生成模型 Seedance 2.0,加上最新的图片生成模型 Image 2,订阅 Ultra Plan,可不限量使用。