ICLR 2026 | ESC — 解构一步生成,厘清细节,探寻本质
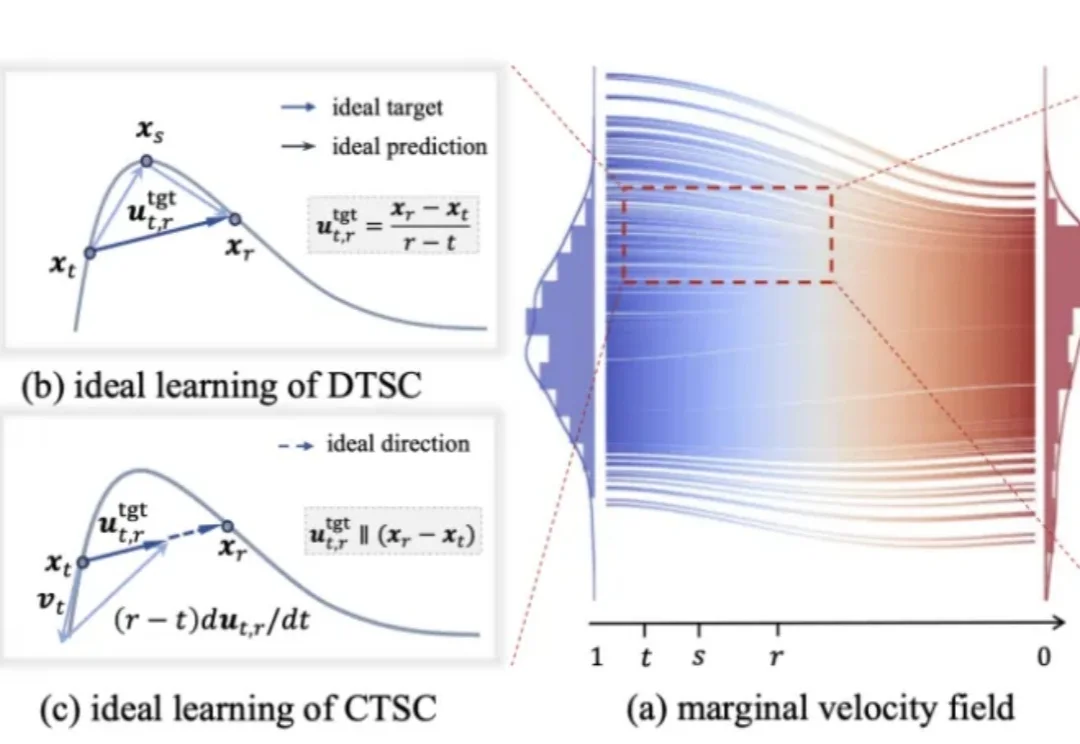
ICLR 2026 | ESC — 解构一步生成,厘清细节,探寻本质近期,基于捷径化概率流路径(shortcut probability flow trajectory)并从头训练的一步扩散生成模型,展现出强大的实证有效性。然而,这类方法的提出通常建立在较为复杂的理论推导之上,并且往往与具体实现细节高度耦合。这带来一个直接的问题:究竟哪些设计是方法成立的本质要素,哪些又只是可以灵活替换的实现组件。
来自主题: AI技术研报
7763 点击 2026-03-24 17:19