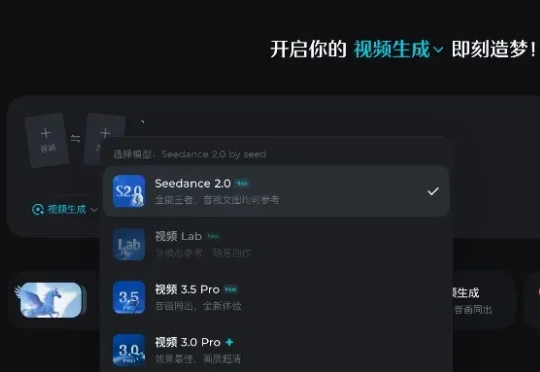
“强到可怕!”字节Seedance2.0灰度测试爆火,黑悟空老板:AIGC的童年结束了
“强到可怕!”字节Seedance2.0灰度测试爆火,黑悟空老板:AIGC的童年结束了2月7日,字节跳动AI视频生成模型Seedance2.0开启灰度测试,该模型支持文本、图片、视频、音频素材输入,可以完成自分镜和自运镜,镜头移动后人物特征能够保持一致。
来自主题: AI资讯
10907 点击 2026-02-09 20:02
 搜索
搜索
2月7日,字节跳动AI视频生成模型Seedance2.0开启灰度测试,该模型支持文本、图片、视频、音频素材输入,可以完成自分镜和自运镜,镜头移动后人物特征能够保持一致。
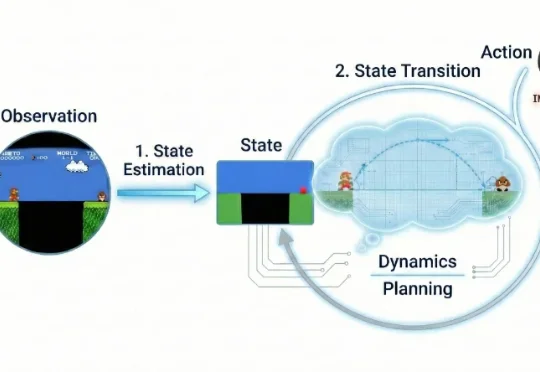
近年来,视频生成(Video Generation)与世界模型(World Models)已跃升为人工智能领域最炙手可热的焦点。从 Sora 到可灵(Kling),视频生成模型在运动连续性、物体交互与部分物理先验上逐渐表现出更强的「世界一致性」,让人们开始认真讨论:能否把视频生成从「逼真短片」推进到可用于推理、规划与控制的「通用世界模拟器」。
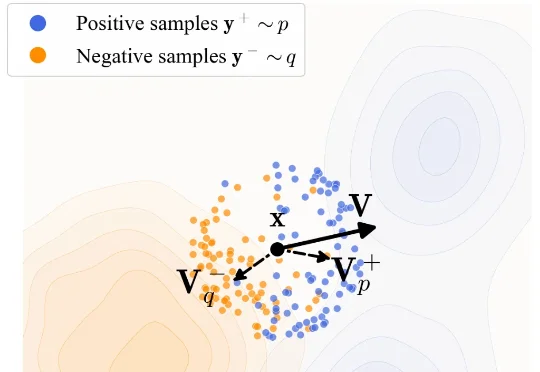
训练一个生成模型是很复杂的一件事儿。 从底层逻辑上来看,生成模型是一个逐步拟合的过程。与常见的判别类模型不同,判别类模型通常关注的是将单个样本映射到对应标签,而生成模型则关注从一个分布映射到另一个分布。

刚刚,何恺明团队提出全新生成模型范式漂移模型(Drifting Models)。

xAI“迄今为止最强大的视频音频生成模型”Grok Imagine 1.0版本,正式全面上线。
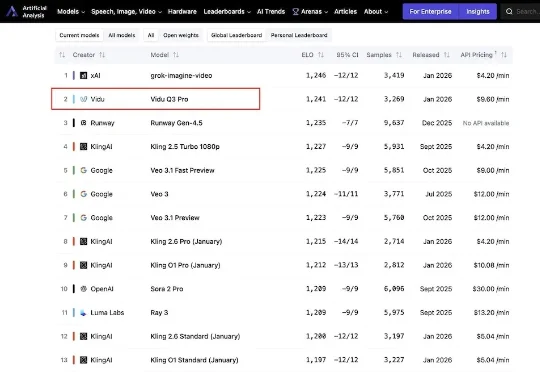
今日,来自生数科技的AI视频模型Vidu Q3 Pro登上国际权威AI基准平台Artificial Analysis榜单,位列中国第一,全球第二。这是最新榜单内,首个打入国际第一梯队的国产视频生成模型。
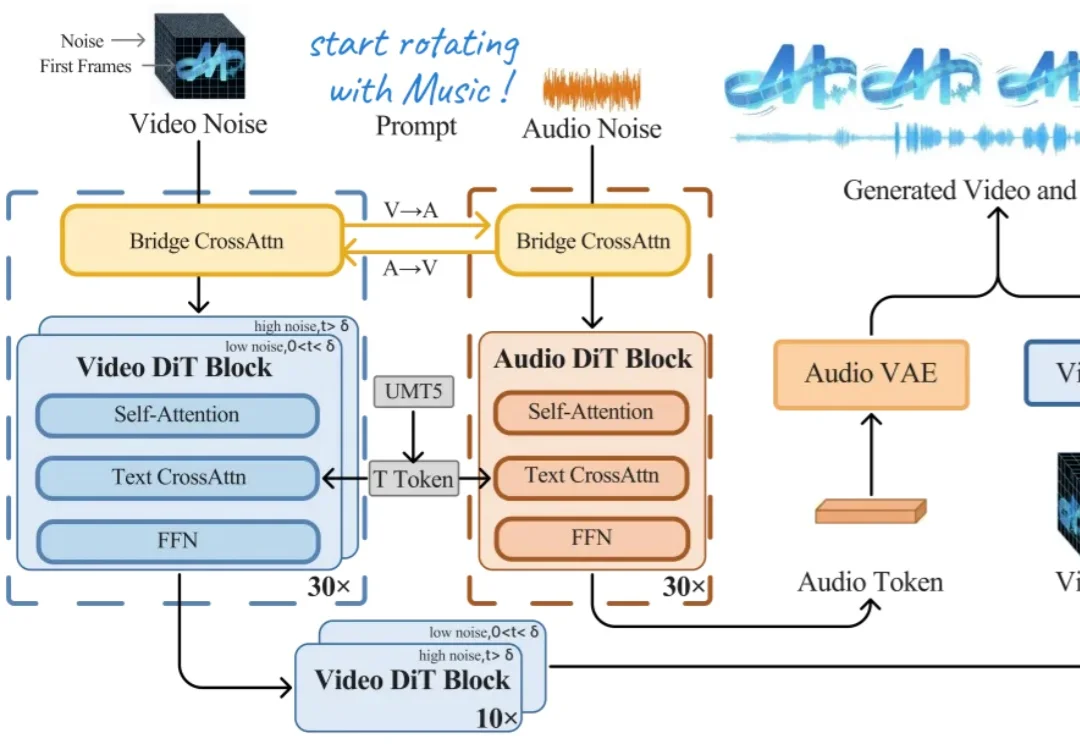
今天上午,上海创智学院 OpenMOSS 团队联合初创公司模思智能(MOSI),正式发布了端到端音视频生成模型 —— MOVA(MOSS-Video-and-Audio)。
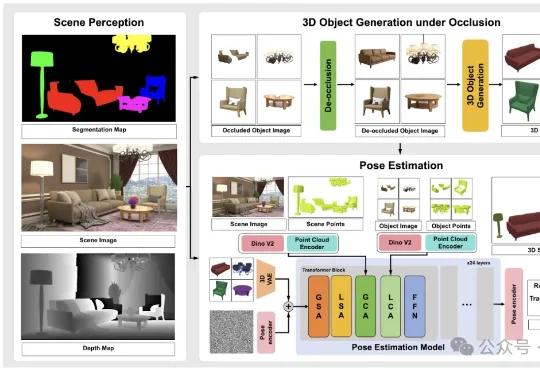
IDEA研究院张磊团队与香港科技大学谭平团队联合推出SceneMaker框架,有望攻克这一问题。 它以视启未来的万物检测模型DINO-X与光影焕像的万物3D生成模型Triverse为基础,实现了从任意开放世界图像(室内/室外/合成图等)到带Mesh的3D场景的完整重建。
今天,首个在国产芯片上完成全程训练的SOTA(最佳水平)多模态模型开源。这是智谱联合华为开源的图像生成模型GLM-Image。从数据到训练的全流程,该模型完全基于昇腾Atlas 800T A2设备和昇思MindSpore AI框架完成构建。
昨晚夜里快12点,AI视频公司PixVerse毫无预兆的发了一个项目。PixVerse R1,下一代实时世界生成模型。这玩意你看文字,可能不是很好理解,我直接放一个官方的demo视频,大家的感觉应该会强一些。