
今天,我决定把「卡兹克风格创作.skill」开源了。
今天,我决定把「卡兹克风格创作.skill」开源了。故事是这样的。 最近各种把同事、把前任、把各种知识蒸馏成Skill的东西特别火。
来自主题: AI资讯
9865 点击 2026-04-07 14:58
故事是这样的。 最近各种把同事、把前任、把各种知识蒸馏成Skill的东西特别火。

目前,最先进的对齐方法是使用知识蒸馏(Knowledge Distillation, KD)在所有 token 上最小化 KL 散度。然而,最小化全局 KL 散度并不意味着 token 的接受率最大化。由于小模型容量受限,草稿模型往往难以完整吸收目标模型的知识,导致直接使用蒸馏方法的性能提升受限。在极限场景下,草稿模型和目标模型的巨大尺寸差异甚至可能导致训练不收敛。
通过蒙特卡洛树搜索筛选高难度样本,ThinkLite-VL仅用少量数据就能显著提升视觉语言模型的推理能力,无需知识蒸馏,为高效训练提供了新思路。
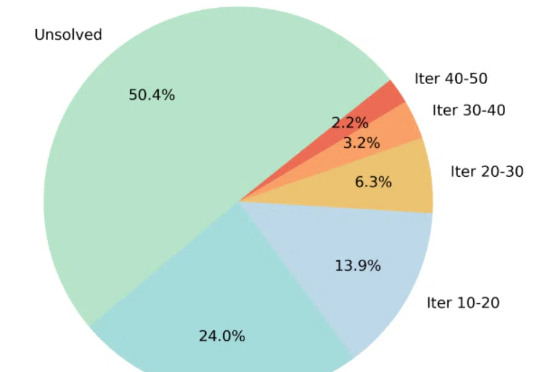
通过蒙特卡洛树搜索筛选高难度样本,ThinkLite-VL仅用少量数据就能显著提升视觉语言模型的推理能力,无需知识蒸馏,为高效训练提供了新思路。

张林峰于2019年提出了自蒸馏算法,是知识蒸馏领域的代表性工作之一。DeepSeek出现后,知识蒸馏领域再次获得了极大的关注。

TimeDistill通过知识蒸馏,将复杂模型(如Transformer和CNN)的预测能力迁移到轻量级的MLP模型中,专注于提取多尺度和多周期模式,显著提升MLP的预测精度,同时保持高效计算能力,为时序预测提供了一种高效且精准的解决方案。

自然语言 token 代表的意思通常是表层的(例如 the 或 a 这样的功能性词汇),需要模型进行大量训练才能获得高级推理和对概念的理解能力,
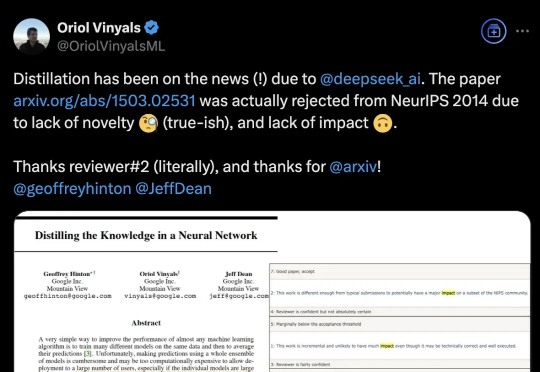
DeepSeek带火知识蒸馏,原作者现身爆料:原来一开始就不受待见。称得上是“蒸馏圣经”、由Hinton、Oriol Vinyals、Jeff Dean三位大佬合写的《Distilling the Knowledge in a Neural Network》,当年被NeurIPS 2014拒收。
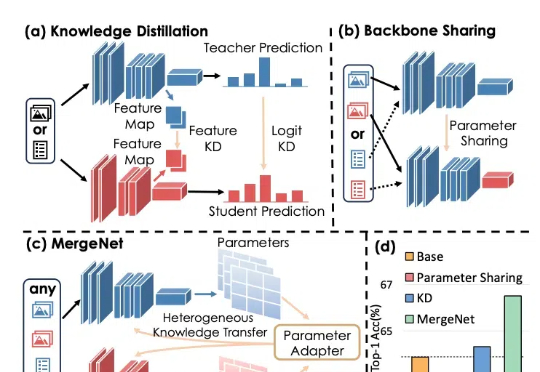
知识蒸馏通过训练一个紧凑的学生模型来模仿教师模型的 Logits 或 Feature Map,提高学生模型的准确性。迁移学习则通常通过预训练和微调,将预训练阶段在大规模数据集上学到的知识通过骨干网络共享应用于下游任务。

大连理工大学的研究人员提出了一种基于Wasserstein距离的知识蒸馏方法,克服了传统KL散度在Logit和Feature知识迁移中的局限性,在图像分类和目标检测任务上表现更好。