# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
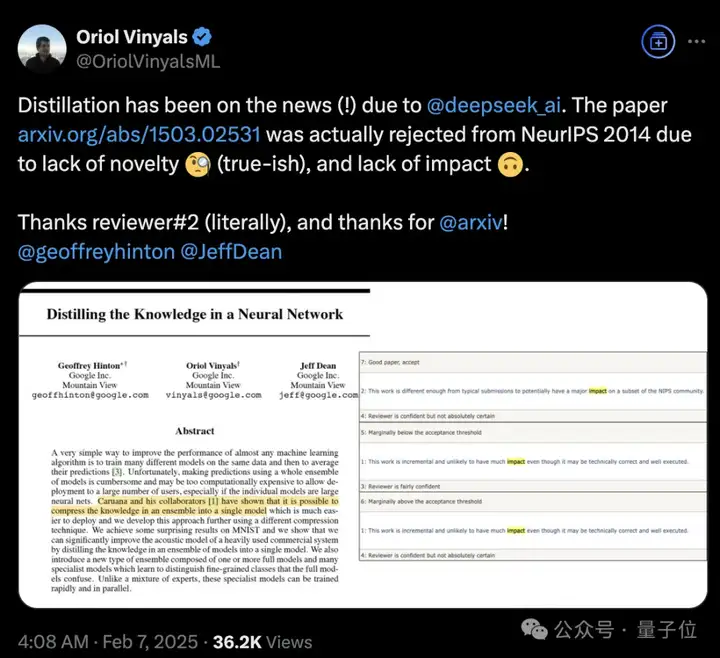
DeepSeek带火知识蒸馏,原作者现身爆料:原来一开始就不受待见。
称得上是“蒸馏圣经”、由Hinton、Oriol Vinyals、Jeff Dean三位大佬合写的《Distilling the Knowledge in a Neural Network》,当年被NeurIPS 2014拒收。
如何评价这篇论文的含金量?
它提出了知识蒸馏这一概念,能在保证准确率接近的情况下,大幅压缩模型参数量,让模型能够部署在各种资源受限的环境。
比如Siri能够出现在手机上,就是用知识蒸馏压缩语音模型。
自它之后,大模型用各种方法提高性能上限,再蒸馏到小模型上已经成为一种行业标配。

再来看它的主创阵容。
Hinton,深度学习之父,如今已是诺奖得主。
Oriol Vinyals,Google DeepMind研究科学家,参与开发的明星项目包括TensorFlow、AlphaFold、Seq2Seq、AlphaStar等。
Jeff Dean,Google DeepMind首席科学家、从2018年开始全面领导谷歌AI。大模型浪潮里,推动了PaLM、Gemini的发展。
不过,那又怎样?
主创之一Oriol Vinyals表示,因为缺乏创新和影响力,这篇论文被拒啦。谢谢审稿人(字面意思),谢谢arxiv!
简单粗暴总结,《Distilling the Knowledge in a Neural Network》是一篇更偏工程性改进的文章,但是带来的效果提升非常显著。
Caruana等人在2006年提出了将集成知识压缩到单模型的可能性,论文中也明确提到了这一点。
Hinton等人的工作是提出了一种简单有效的知识迁移框架,相较于Caruana团队的方法更加通用。
方法看上去非常简单:
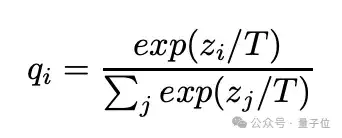
他们认为此前人们习惯性地将模型中的知识与模型的具体参数绑定在一起,因此很难想到该如何在改变模型结构的同时仍旧保留这些知识。
如果把知识看作是输入向量到输出向量的一个抽象映射,而不是某种固定的参数实现,就能更容易理解如何将知识从一个模型转移到另一个模型。
知识蒸馏的关键就是让小模型模仿大模型的“理解方式”,如果大模型是多个模型的集成,表现出很强的泛化能力,那就通过蒸馏训练小模型去学习这种泛化方式,这种方法能让小模型集成大模型的知识精髓,同时更适合实际应用部署。
怎么将泛化能力转移?
让大模型生成类别概率作为软目标,以此训练小模型。
在这个转移阶段,使用与原始训练相同的数据集,或者单独准备一个“迁移”数据集。
如果大模型是由多个模型集成,那就取它们的预测平均值。
软目标的特点是,它具有高熵时(即预测的概率分布更平滑),每个训练样本中包含的信息量比硬目标要多得多,训练样本之间的梯度变化也更小。
因此,用软目标训练小模型时,往往可以使用比原始模型更少的数据,并且可以采用更高的学习率。
小模型可以用无标签数据或原始训练。如果用原始训练数据,可以让小模型同时学习来自大模型的软目标和真实标签,这样效果会更加好。
具体方法是使用软目标的交叉熵损失、真实标签的交叉熵损失两个目标函数加权平均。如果真实标签的交叉熵损失权重较小时,往往能获得最佳效果。
此外,他们还发现软目标的梯度大小随着T²缩放,同时使用真实标签和软目标时,比如将软目标的梯度乘以T²,这样可以确保在调整蒸馏温度这一超参数时,硬目标和软目标的相对贡献保持大致不变。
实验结果显示,在MINIST数字时延中,教师模型(1200层)的错误案例为67个,学生模型(800层)使用蒸馏后的错误案例为74个。
在JFT数据集上,基准模型的错误率为27.4%,集成模型的错误率为25%。蒸馏模型错误率为25.6%,效果接近集成模型但计算量大幅减少。
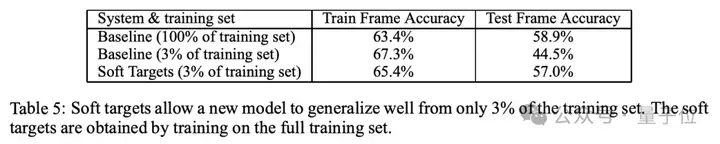
语音识别实验上,蒸馏模型也达到了与集成模型相同的性能,但是仅使用了3%的训练数据。
值得一提的是,Vinyals还表示,提出了LSTM的Jürgen Schmidhuber在1991年发表的一篇文章,这可能与现在火热的长上下文息息相关。
他提到的应该是《Learning complex, extended sequences using the principle of history compression》这篇论文。其核心内容是利用历史压缩的原则,即通过模型结构和算法将序列的历史信息有效地编码和存储,从而减少处理长序列时的计算开销,同时保留关键的信息。
有人就说,不妨设置一个时间检验奖颁给那些未被接收的论文吧。

同时也有人在这个话题下想到了DeepSeek。
曾在苹果、谷歌工作过的Matt Henderson表示,DeepSeek做的蒸馏只是基于教师模型输出的微调,并没有用到软目标(因为模型的分词方式不同)。

Vinyals回应说,那看来我们取蒸馏这个名字真的不错~
参考链接:
[1]https://x.com/OriolVinyalsML/status/1887594344183701814
[2]https://arxiv.org/abs/1503.02531
文章来自微信公众号 “ 量子位 “,作者 小明




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
