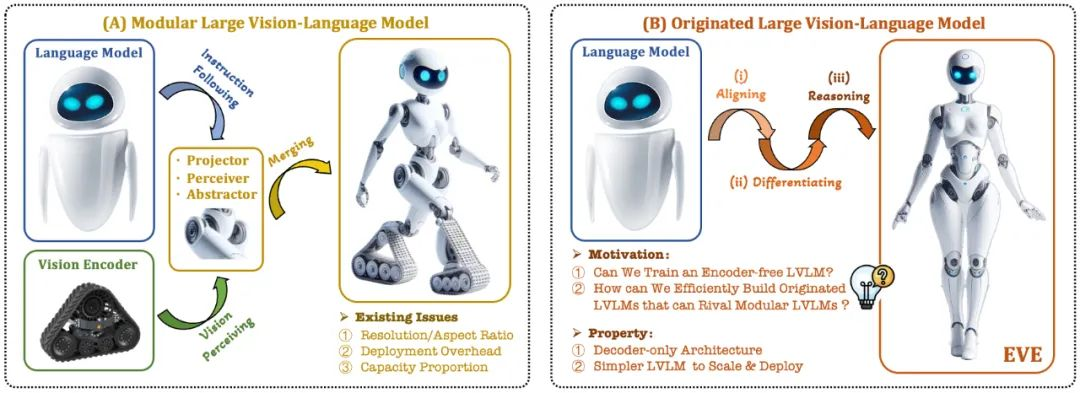
抛弃视觉编码器,这个「原生版」多模态大模型也能媲美主流方法
抛弃视觉编码器,这个「原生版」多模态大模型也能媲美主流方法近期,关于多模态大模型的研究如火如荼,工业界对此的投入也越来越多。
来自主题: AI技术研报
10517 点击 2024-07-16 19:57
 搜索
搜索
近期,关于多模态大模型的研究如火如荼,工业界对此的投入也越来越多。

由深度学习巨头、图灵奖获得者 Yoshua Bengio 和 Yann LeCun 在 2013 年牵头举办的 ICLR 会议,在走过第一个十年后,终于迎来了首届时间检验奖。

首届ICLR时间检验奖,颁向变分自编码器VAE
视觉语言模型屡屡出现新突破,但ViT仍是图像编码器的首选网络结构。

谷歌团队推出「通用视觉编码器」VideoPrism,在3600万高质量视频字幕对和5.82亿个视频剪辑的数据集上完成了训练,性能刷新30项SOTA。

药物与靶标之间的结合亲和力的预测对于药物发现至关重要。然而,现有方法的准确性仍需提高。另一方面,大多数深度学习方法只关注非共价(非键合)结合分子系统的预测,而忽略了在药物开发领域越来越受到关注的共价结合的情况。

FoleyGen利用现成的神经音频编解码器在波形和离散标记之间进行双向转换。音频标记的生成由单个变换器模型完成,该模型以从视觉编码器中提取的视觉特征为条件。