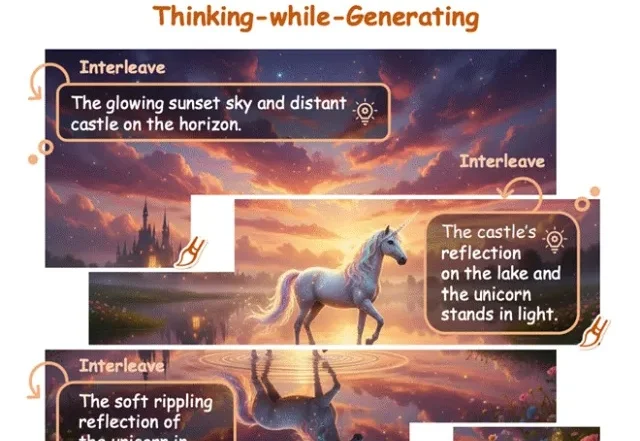
让AI像人类画家一样边画边想,港中文&美团让模型「走一步看一步」
让AI像人类画家一样边画边想,港中文&美团让模型「走一步看一步」在文生图(Text-to-Image)和视频生成领域,以FLUX.1、Emu3为代表的扩散模型与自回归模型已经能生成极其逼真的画面。
来自主题: AI技术研报
11360 点击 2025-12-22 16:05
 搜索
搜索
在文生图(Text-to-Image)和视频生成领域,以FLUX.1、Emu3为代表的扩散模型与自回归模型已经能生成极其逼真的画面。
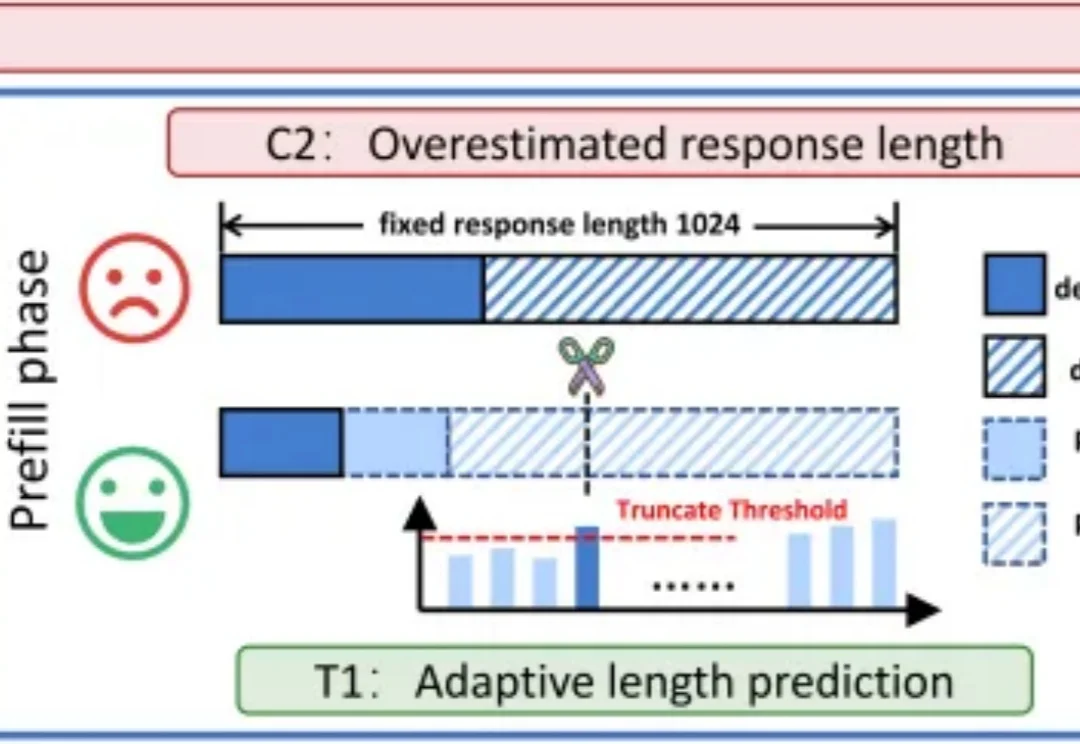
基于扩散的大语言模型 (dLLM) 凭借全局解码和双向注意力机制解锁了原生的并行解码和受控生成的潜力,最近吸引了广泛的关注。例如 Fast-dLLM 的现有推理框架通过分块半自回归解码进一步实现了 dLLM 对 KV cache 的支持,挑战了传统自回归 LLMs 的统治地位。

一篇入围顶会NeurIPS’25 Oral的论文,狠狠反击了一把DiT(Diffusion Transformer)。这篇来自字节跳动商业化技术团队的论文,则是提出了一个名叫InfinityStar的方法,一举兼得了视频生成的质量和效率,为视频生成方法探索更多可能的路径。

刚刚,文心5.0正式发布了!全新一代主打原生全模态,最开始就把语言/图像/视频/音频放在同一套自回归统一架构里,做统一的理解与生成训练。所以,最终模型能够做到支持全模态输入(文字/图片/音频/视频)+全模态输出(文字/图片/音频/视频),创意写作、指令遵循、智能体规划方面也更强了。

众所周知,大型语言模型(LLM)的根本运作方式是预测下一个 token(词元),能够保证生成的连贯性和逻辑性,但这既是 LLM 强大能力的「灵魂」所在,也是其枷锁,将导致高昂的计算成本和响应延迟。 可
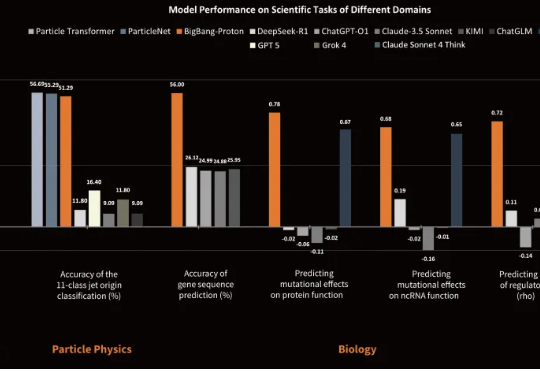
近日,专注于研发物质世界基座模型的公司超越对称(上海)技术有限公司(超对称)发布了新版基座模型 BigBang-Proton,成功实现多个真实世界的专业学科问题与 LLM 的统一预训练和推理,挑战了 Sam Altman 和主流的 AGI 技术路线。

大模型一个token一个token生成,效率太低怎么办?

谷歌遗珠与IBM预言:一文点醒Karpathy,扩散模型或成LLM下一步。
在多模态生成领域,由视频生成音频(Video-to-Audio,V2A)的任务要求模型理解视频语义,还要在时间维度上精准对齐声音与动态。早期的 V2A 方法采用自回归(Auto-Regressive)的方式将视频特征作为前缀来逐个生成音频 token,或者以掩码预测(Mask-Prediction)的方式并行地预测音频 token,逐步生成完整音频。
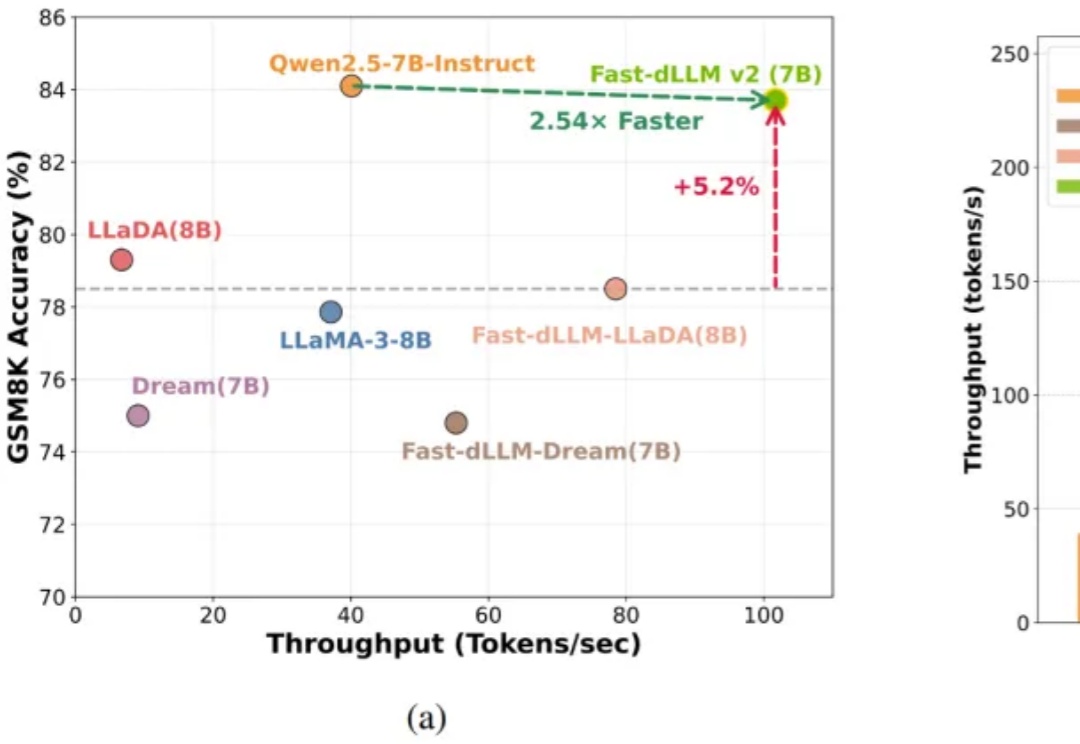
自回归(AR)大语言模型逐 token 顺序解码的范式限制了推理效率;扩散 LLM(dLLM)以并行生成见长,但过去难以稳定跑赢自回归(AR)模型,尤其是在 KV Cache 复用、和 可变长度 支持上仍存挑战。