
马斯克买了新厂房上GPU,2GW供电规模,“巨硬”更更硬了
马斯克买了新厂房上GPU,2GW供电规模,“巨硬”更更硬了马斯克“巨硬计划”新消息,第三栋专属厂房已经买下来了,代号MACROHARDRR。果然更硬核,老马透露,其将具备2GW供电规模。若参照此前曝光的(200MW支持11万台GB200)的功耗密度与架构效率推算,可支持约110万台英伟达GB200 NVL72 GPU。
来自主题: AI资讯
11541 点击 2025-12-31 15:12
 搜索
搜索
马斯克“巨硬计划”新消息,第三栋专属厂房已经买下来了,代号MACROHARDRR。果然更硬核,老马透露,其将具备2GW供电规模。若参照此前曝光的(200MW支持11万台GB200)的功耗密度与架构效率推算,可支持约110万台英伟达GB200 NVL72 GPU。
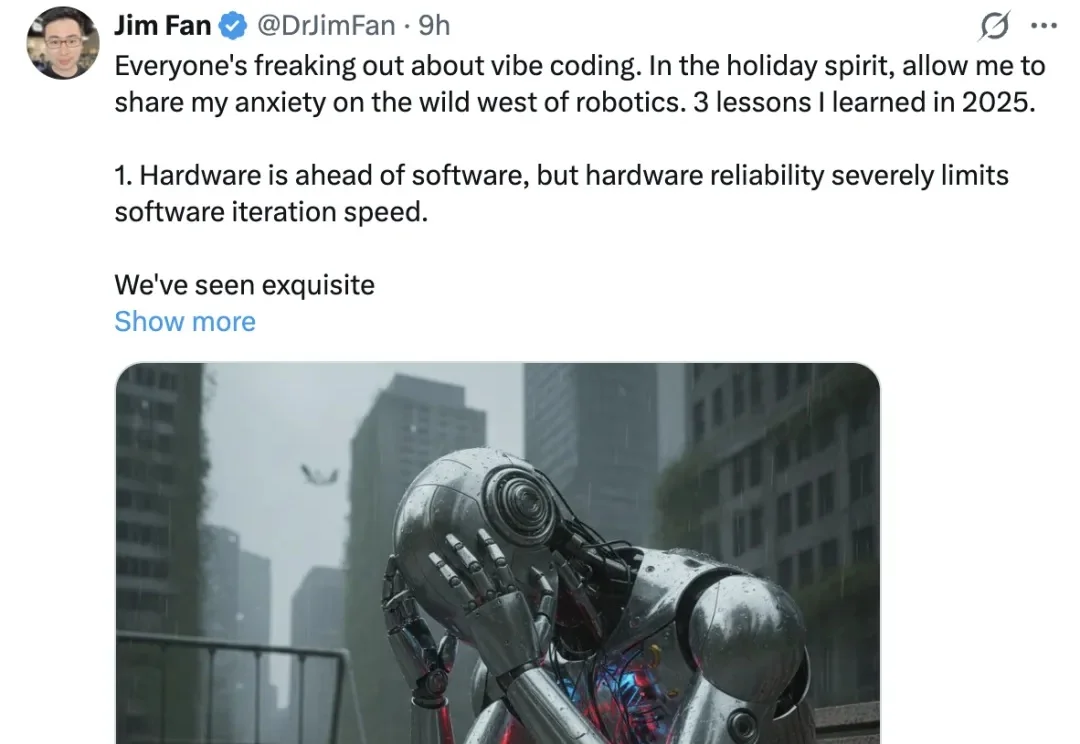
“机器人领域仍处于蛮荒时代。”

AI算力焦虑可能搞错方向了?黄仁勋直指能效才是上限。

更多英伟达收购「TPU之父」创业公司Groq的细节曝光了—— 主打一个黄仁勋BOSS直聘。

Metronome成立于2019年的旧金山,专注于为AI与软件公司提供实时计费基础设施,解决从传统按Seat收费转向按用量、Token等复杂定价的工程难题。目前其融资总额达1.28亿美元,已服务OpenAI、NVIDIA、Databricks等头部企业,终端用户超1.5亿,成为AI时代“按价值收费”的关键基础设施。

老黄稳准狠,谷歌的TPU威胁刚至,就钞能力回应了。
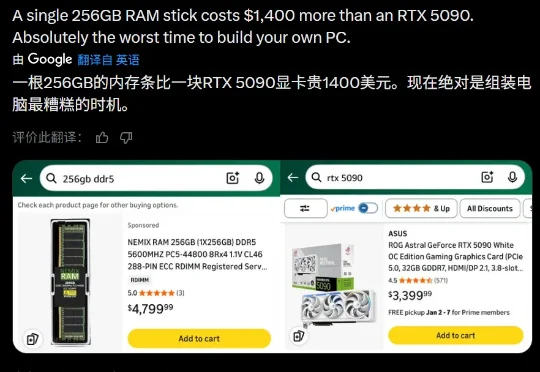
英伟达的顶配 GPU RTX 5090 官方起售价为 1999 美元(经过市场溢价可能达到了 3000 美元以上),而一根单条 256GB 的 DDR5 内存如今的市场价却也飙升到了 3500-5000 美元之间。

英伟达在开源模型上玩的很激进: “最高效的开放模型家族”Nemotron 3,混合Mamba-Transformer MoE架构、NVFP4低精度训练全用上。而且开放得很彻底:

2名员工、0芯片业务、营收为负,股价却狂飙550倍,这场印度的「AI造富神话」,堪称是对当下全球科技泡沫最辛辣的讽刺。

英伟达让AI仅靠「看直播」就学会了通用游戏操作。虚拟世界已成为物理智能的黑客帝国,看4万小时直播学会几乎所有游戏!