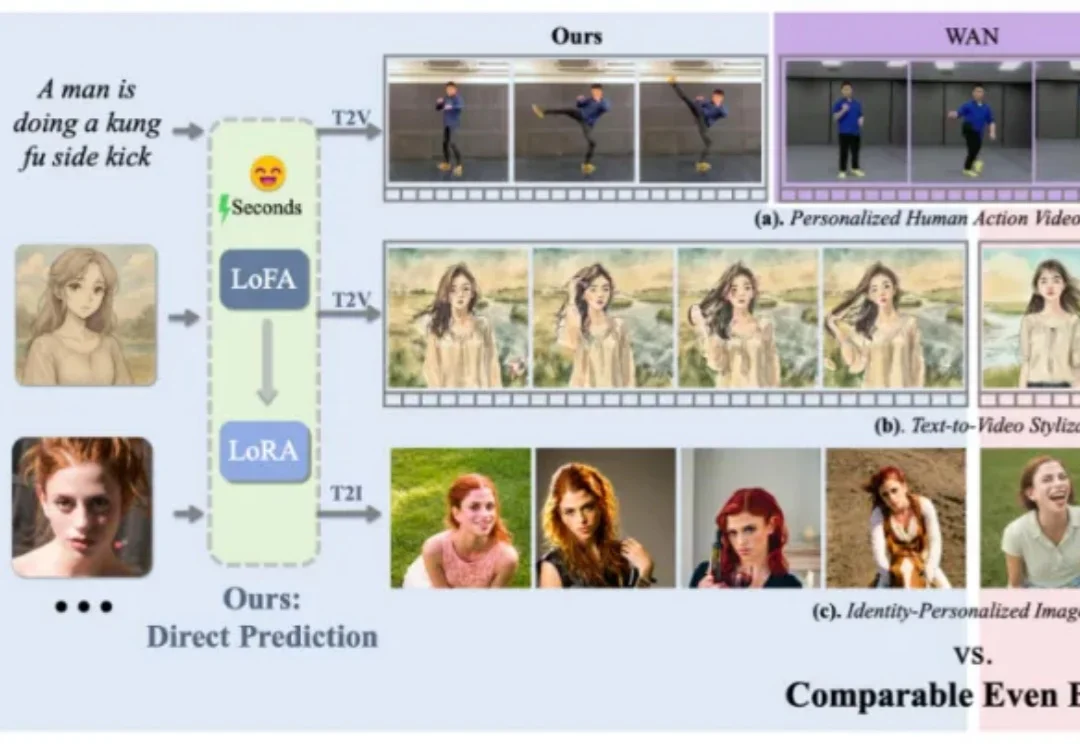
比LoRA更快更强,全新框架LoFA上线,秒级适配大模型
比LoRA更快更强,全新框架LoFA上线,秒级适配大模型在个性化视觉生成的实际应用中,通用视觉基础模型的表现往往难以满足精准需求。为实现高度定制化的生成效果,通常需对大模型进行针对性的自适应微调,但当前以 LoRA 为代表的主流方法,仍受限于定制化数据收集与冗长的优化流程,耗时耗力,难以在真实场景中广泛应用。
来自主题: AI技术研报
7082 点击 2025-12-18 09:12
 搜索
搜索
在个性化视觉生成的实际应用中,通用视觉基础模型的表现往往难以满足精准需求。为实现高度定制化的生成效果,通常需对大模型进行针对性的自适应微调,但当前以 LoRA 为代表的主流方法,仍受限于定制化数据收集与冗长的优化流程,耗时耗力,难以在真实场景中广泛应用。
6月30日,上海交通大学医学院附属瑞金医院宣布,RuiPath病理大模型的视觉基础模型正式开源。
咱就是说啊,视觉基础模型这块儿,国产AI真就是上了个大分——Glint-MVT,来自格灵深瞳的最新成果。Glint-MVT,来自格灵深瞳的最新成果先来看下成绩——线性探测(LinearProbing):
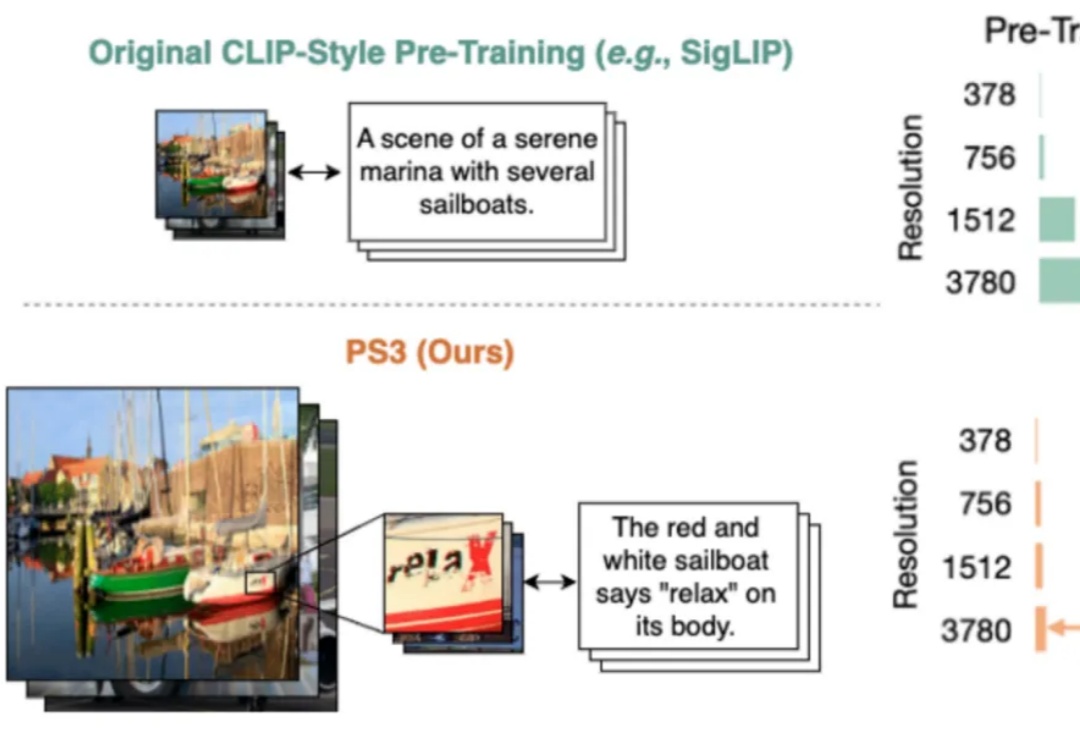
当前,所有主流的视觉基础模型(如 SigLIP、DINOv2 等)都仍然在低分辨率(如 384 * 384 分辨率)下进行预训练。对比人类视觉系统可以轻松达到 10K 等效分辨率,这种低分辨率预训练极大地限制了视觉模型对于高清细节的理解能力。

你是否注意过人类观察世界的独特方式?
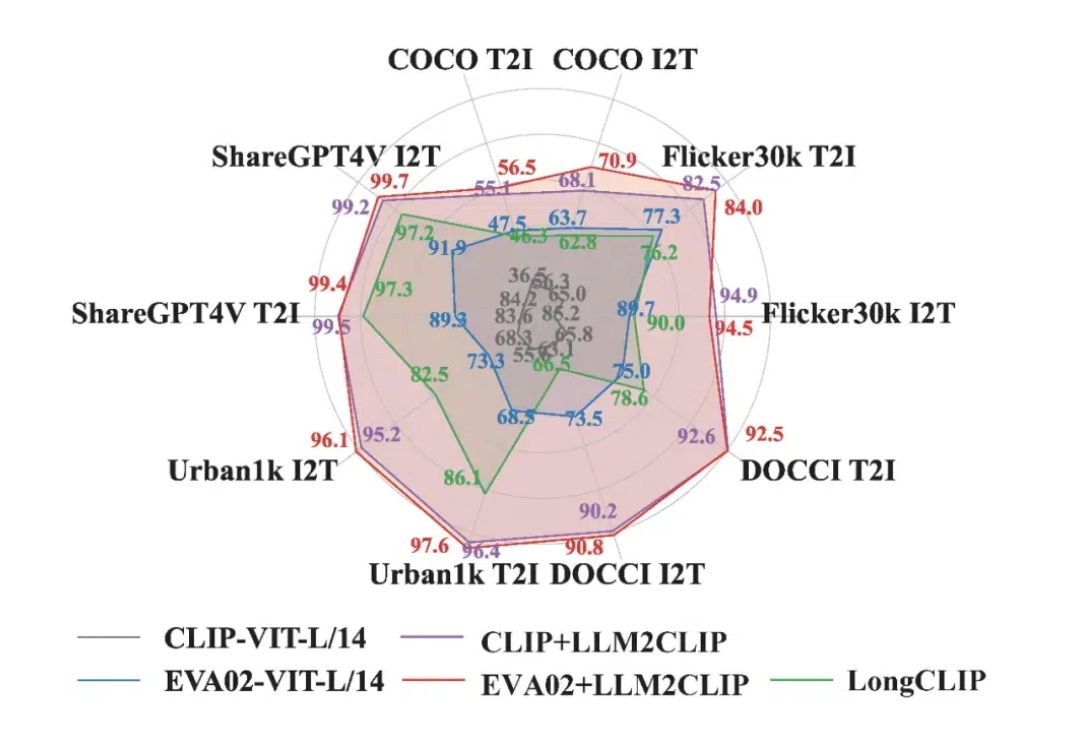
在当今多模态领域,CLIP 模型凭借其卓越的视觉与文本对齐能力,推动了视觉基础模型的发展。CLIP 通过对大规模图文对的对比学习,将视觉与语言信号嵌入到同一特征空间中,受到了广泛应用。

DeepMind最近的研究提出了一种新框架AligNet,通过模拟人类判断来训练教师模型,并将类人结构迁移到预训练的视觉基础模型中,从而提高模型在多种任务上的表现,增强了模型的泛化性和鲁棒性,为实现更类人的人工智能系统铺平了道路。

等了半年,微软视觉基础模型Florence-2终于开源了。它能够根据提示,完成字幕、对象检测、分割等各种计算机视觉和语言的任务。网友们实测后,堪称「游戏规则改变者」。
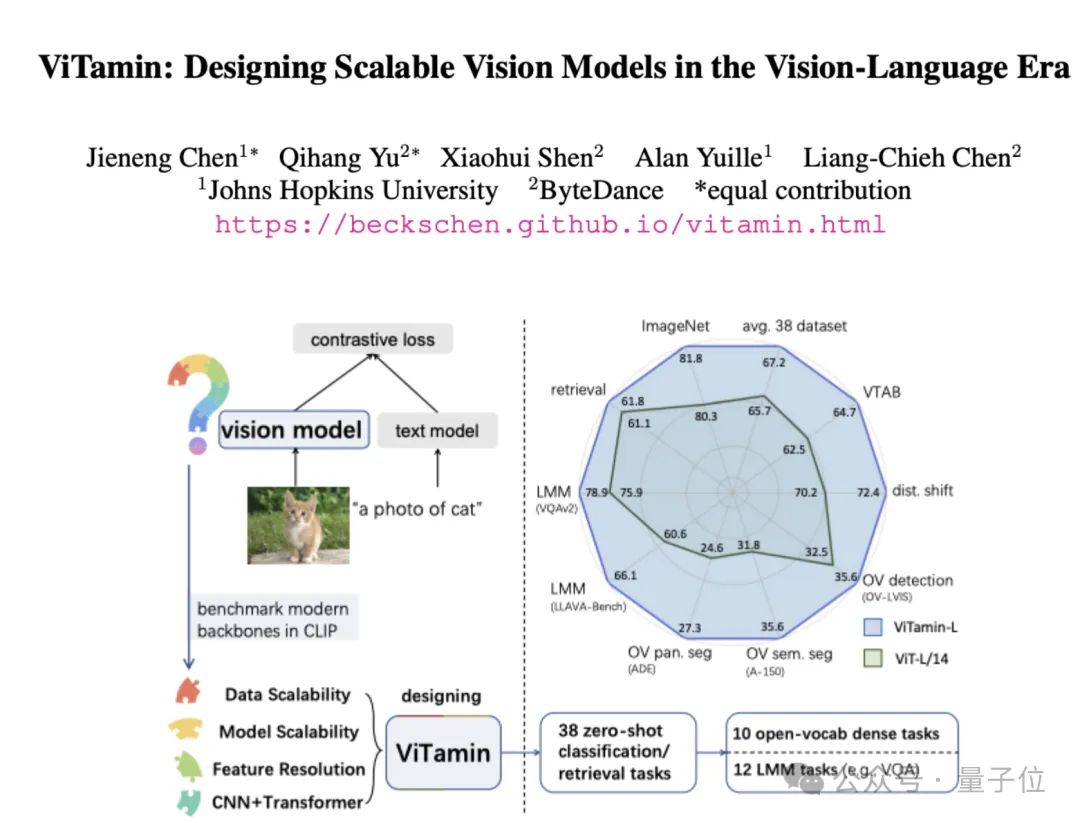
视觉语言模型屡屡出现新突破,但ViT仍是图像编码器的首选网络结构。

近年来,LLM 已经一统所有文本任务,展现了基础模型的强大潜力。一些视觉基础模型如 CLIP 在多模态理解任务上同样展现出了强大的泛化能力,其统一的视觉语言空间带动了一系列多模态理解、生成、开放词表等任务的发展。然而针对更细粒度的目标级别的感知任务,目前依然缺乏一个强大的基础模型。