# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近年来,深度学习在人工智能领域,如自然语言处理和计算机视觉方面取得了快速进展,但即便是最强大的模型,也经常会在那些,对于人类说非常简单的case上折戟。
人类感知对环境变化具有鲁棒性,并能在不同的视觉设置中泛化,相比之下,对于深度学习模型来说,如果训练和测试数据集之间的分布发生偏移,其性能往往会急剧下降。
人类在判断视觉相似性时往往能够很好地校准自己的判断,即人类对某个问题的确定性往往与预测准确率成正比,而AI系统则过于自信,即使在预测错误时也表现出高度的确定性。
所以说,在真正实现通用人工智能之前,深度学习模型和人类之间仍然存在诸多差异需要调和、对齐。
值得思考的是,神经网络训练和人类学习在根本上有所不同,其无法像人类一样稳健地泛化,是否是因为其底层表征的相似性的问题?现代学习系统要表现出更像人类的行为,还缺少什么?深度学习模型在概念层次结构的各个层次上缺乏这种全局组织,是否可能导致了这些模型的前述弱点?
最近,DeepMind等机构的研究人员联合发布了一篇长达50页的论文,提出了一个可能导致AI模型与人类表现存在差异的原因:人类概念知识是从精细到粗尺度进行分层组织的,而深度学习模型表征无法捕捉到人类感知的多层次概念结构。

论文链接:https://arxiv.org/pdf/2409.06509
虽然说模型表征在一定程度上可以对局部视觉和语义特征(例如,不同犬种的纹理或颜色)进行编码,共享实体之间的人类感知相似性结构,但对于在视觉和语义上更为不同的概念之间的全局关系(例如,狗和鱼都是有生命的,但在视觉上根本不相似)的建模则远没有那么系统化。
然而,人类的神经表示是由全局特征(如生命性)组织起来的,并且在多个更细的尺度上捕捉微妙的语义关系。
为了解决这种不一致问题,研究人员提出了一个新的框架,通过模拟大量类似人类的相似性判断数据集,来提高模型与人类的对齐度。
首先训练一个教师模型来模仿人类的判断,然后将这种类人的结构(human-link structure)表征迁移到预训练后的视觉基础模型中,从而使这些与人类对齐的模型在包括一个新的跨越多个语义抽象层次的人类判断数据集在内的一系列相似性任务中,更准确地近似人类的行为和不确定性。
结果显示,该模型在各种机器学习任务上表现更好,提高了泛化性和分布外的鲁棒性,此外,将额外的人类知识注入神经网络后,学习到的表征更符合人类认知,也更实用,为更强大、可解释和类人的AI系统铺平了道路。
此外,文中还提供了一套开源的视觉模型,通过软对齐编码了分层的人类知识,其普遍意义在于使科学、医学和工业能够使用更类人和鲁棒的视觉模型进行下游应用,任何研究人员或从业者都可以无限制地使用。
总的来说,这项工作不仅有助于更好地理解人工智能与人类智能之间的主要差异,而且还提出了一种可能对实现类似人类智能的人工智能至关重要的原则,即关注人类知识中的多分辨率关系结构。
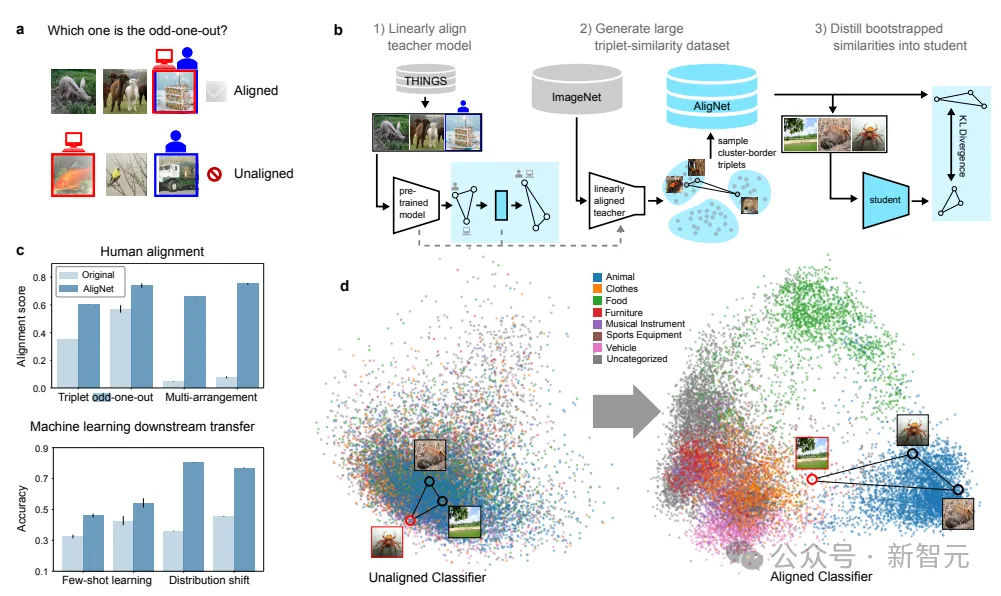
研究人员首先使用仿射变换来对齐神经网络模型表示与人类在三元组异类任务中的语义判断,利用THINGS数据集开发了一个人类判断的教师模型;
与此同时,通过保持模型的局部表征结构来规范对齐过程,并额外利用人类恢复的不确定性度量来改善模型校准。
然后将该模型应用于ImageNet,将其潜在表示聚类到语义上有意义的类别,从而能够生成大量的语义相似性三元组,研究人员将该数据集称为AligNet。
为了将这种精心构造的类人相似性结构信息迁移到预训练的神经网络基础模型中,研究人员引入了一种基于Kullback-Leibler散度的新目标函数,将语义信息蒸馏到一个学生视觉基础模型(VFM)中。
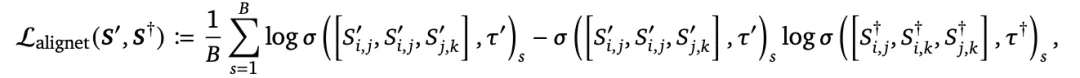
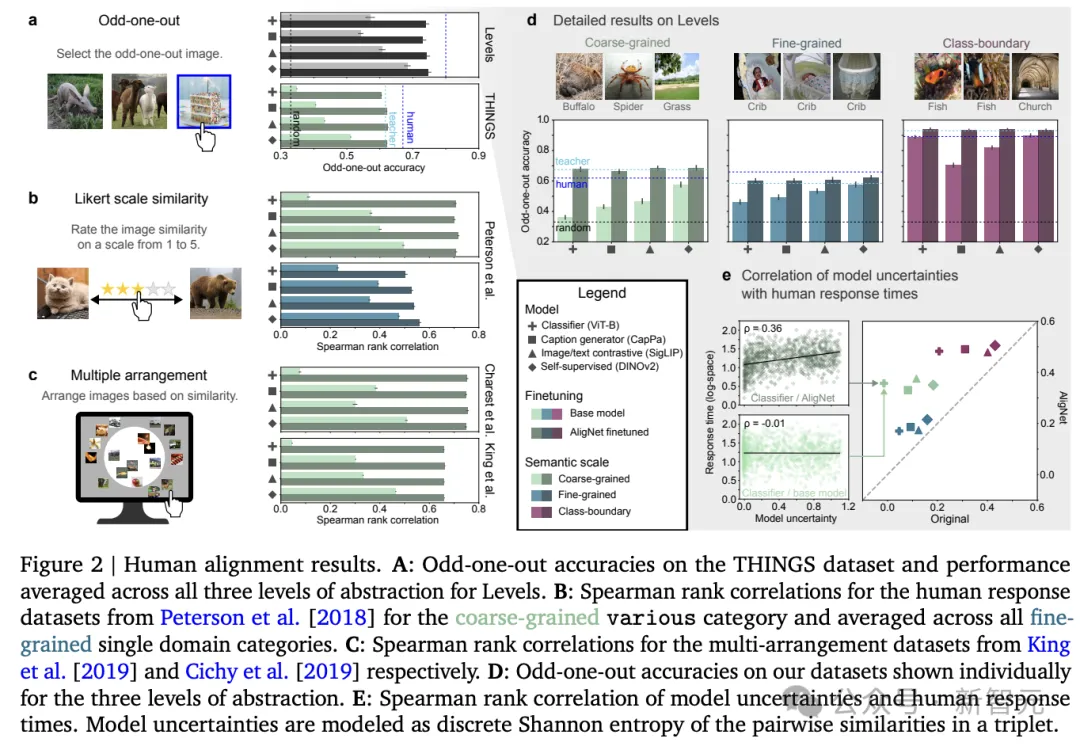
为了验证AligNet框架的有效性,即是否有助于提高模型与人类之间的对齐度,研究人员验证了模型在THINGS三元组异类(triplet odd-one-out )数据上的表现接近人类噪声上限的66.67%。在对教师模型表示应用不确定性蒸馏优化后,可以观察到在THINGS数据中的所有三元组中,三元组异类响应与人类响应的一致性达到了61.7%
此外,研究人员还发现,在模型生成的三元组异类响应数据上微调视觉基础模型后,所有模型的表现都有了显著的提升,无论预训练任务和用于训练基础模型的目标函数是什么,或是其他认知相似性任务和相似性度量方式,软对齐技术都能够提高模型在特定任务上的表现,使模型的行为更加接近人类的思维方式。
为了验证软对齐技术是否能够使模型的内部表示更好地反映人类概念知识的层次结构,研究人员利用众包方式收集了一个全新的人类语义判断评估数据集Levels,设计了三种不同难度级别的三元组异类任务,包括需要在大类别间判断异类的全局粗粒度语义任务,需要在相同类别内识别微妙差异的局部细粒度语义任务,以及测试识别不同类别边界的能力的类别边界任务。
实验结果正如预期,研究人员发现模型在预测涉及视觉或语义重叠较少的实体之间关系(即更抽象的)时表现最差。
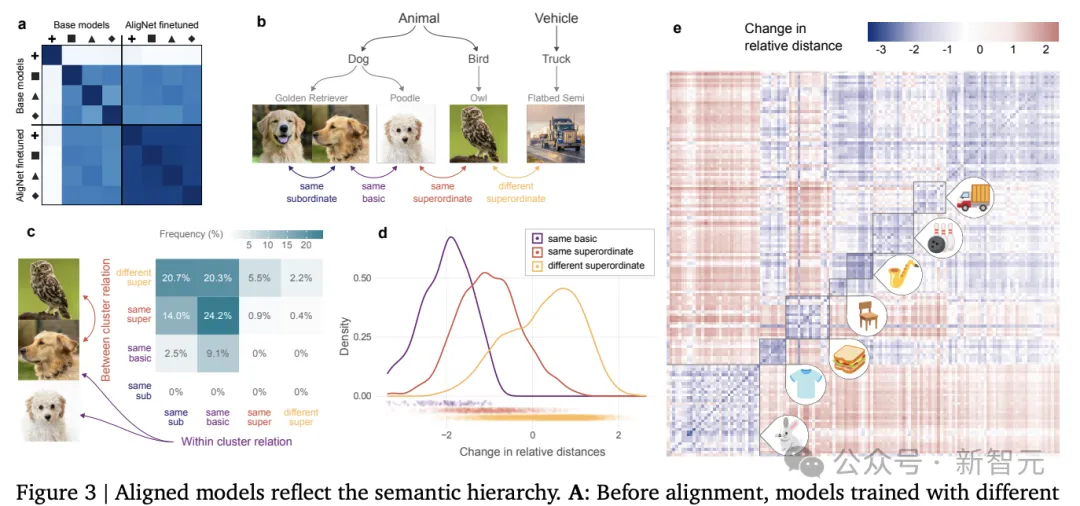
软对齐技术也能显著改变了模型的内部表示,使其在对齐后更加相似,更好地反映了人类对语义类别层次结构的理解。
这种变化的原因在于两个主要因素:首先,模型在对齐过程中生成的标签更贴近人类的判断和不确定性,尤其是在处理更抽象的类别层次时;其次,用于生成三元组的聚类过程也考虑了这种层次结构,倾向于将来自相同下位或基本级别类别的图像配对,而将来自不同基本级别或上位类别的图像作为异类项。
因此,软对齐不仅在聚类过程中,也在标记过程中,以多种方式嵌入了全局结构,从而提高了模型的一致性和类人行为。
研究人员还探讨了软对齐技术如何影响模型在机器学习任务中的泛化能力和面对未知分布数据时的鲁棒性。
为了评估模型表示的质量,首先固定神经网络模型的权重,并在这些固定权重之上训练一个线性分类器,而不是对整个模型进行训练或微调,从而可以更直接地评估模型的内部表示,而不受模型其他部分的影响。
研究者们特别关注了模型在以下三个方面的表现:单次分类任务,考验了模型在只有极少量样本的情况下对新类别的识别能力;分布偏移,即模型在面对与训练数据分布不同的数据时的表现;以及分布外鲁棒性,即模型在面对完全未知类型的数据时的稳定性和鲁棒性。
结果显示,将人类和神经网络模型的表示对齐有助于更好地泛化、转移到新任务和数据上,并增强了模型的鲁棒性,即对齐对于实际改善深度学习是非常有帮助的。
总之,该工作有助于更好地理解人工与自然智能之间的关键差异,实验结果也展示了对齐模型和人类的原则,即专注于人类知识的多分辨率关系结构,可能对于解决实现类人AI的更一般问题至关重要。
文章来源于“新智元”,作者“新智元”




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
