
Z Potentials|CVPR 现场对话苏度科技团队:没有遥控器,没有隔离带,只有真实世界随机的考卷
Z Potentials|CVPR 现场对话苏度科技团队:没有遥控器,没有隔离带,只有真实世界随机的考卷2026 年 6 月的科罗拉多州丹佛市,全球计算机视觉与模式识别领域的顶级学术盛会 CVPR 正在召开,最前沿的视觉模型、机器人技术、下一代智能系统全都在同一个舞台上被反复讨论和辩证。
来自主题: AI资讯
9665 点击 2026-06-08 09:48
 搜索
搜索
2026 年 6 月的科罗拉多州丹佛市,全球计算机视觉与模式识别领域的顶级学术盛会 CVPR 正在召开,最前沿的视觉模型、机器人技术、下一代智能系统全都在同一个舞台上被反复讨论和辩证。
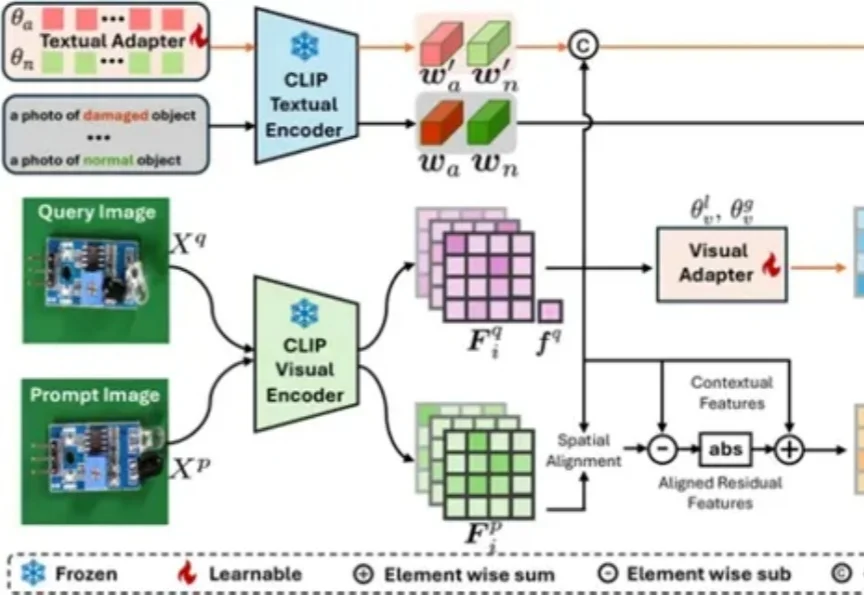
视觉模型用于工业“缺陷检测”等领域已经相对成熟,但当前普遍使用的传统模型在训练时对数据要求较高,需要大量的经过精细标注的数据才能训练出理想效果。
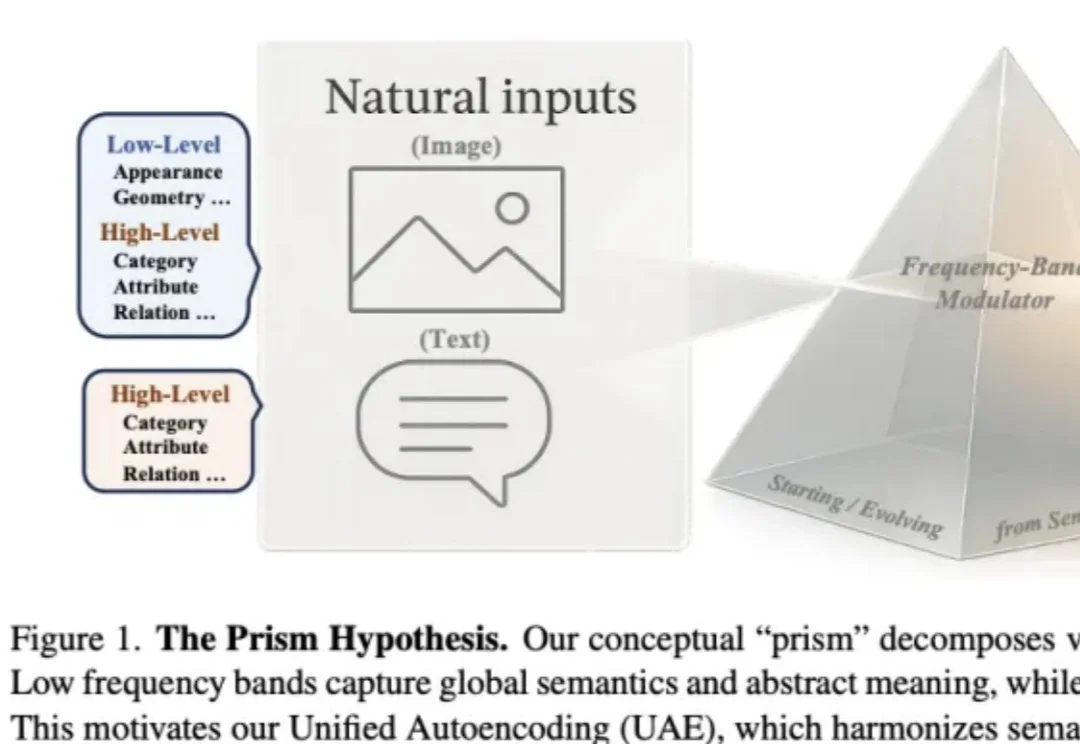
作者来自 Nanyang Technological University(MMLab) 与 SenseTime Research,提出 Prism Hypothesis(棱镜假说) 与 Unified Autoencoding(UAE),尝试用 “频率谱” 的统一视角,把语义编码器与像素编码器的表示冲突真正 “合并解决”。
为了抢回头把交椅,OpenAI 今天正式推出了最新图像视觉模型 GPT-Image-1.5。这也是继 GPT-5.2 之后,OpenAI 红色警报计划中又一记重拳。
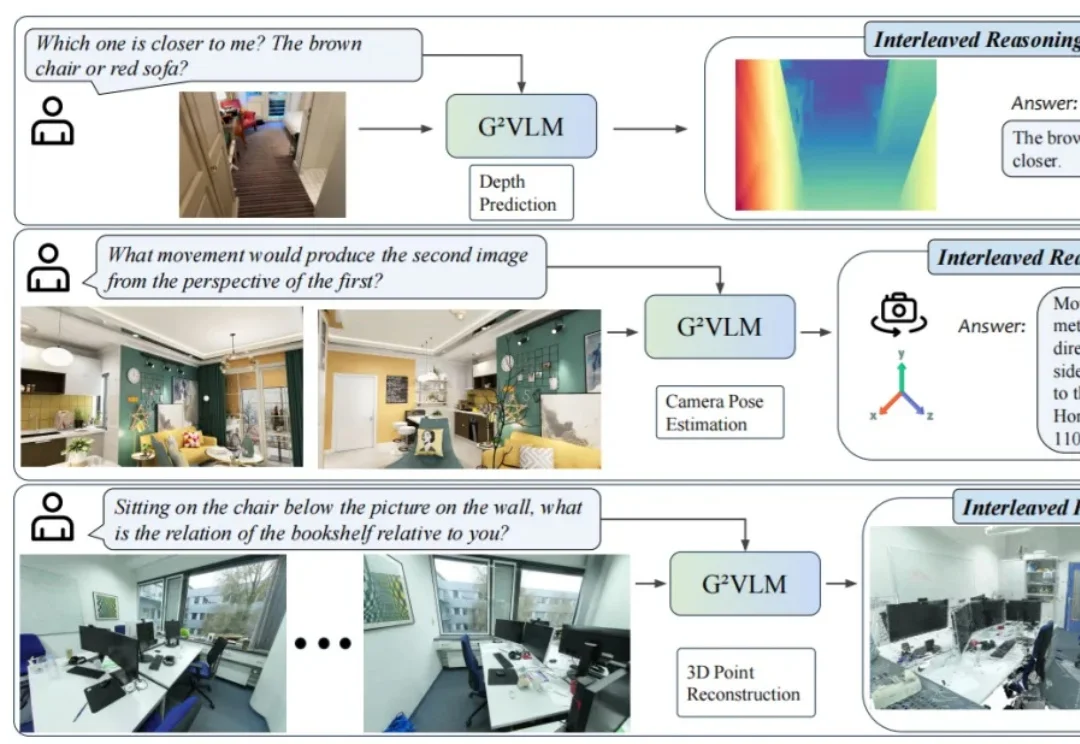
近日,24 岁的 00 后博士生胡文博和所在团队造出一款名为 G²VLM 的超级 AI 模型,它是一位拥有空间超能力的视觉语言小能手,不仅能从普通的平面图片中精准地重建出三维世界,还能像人类一样进行复杂的空间思考和空间推理。

外卖大战压力之下,美团正在打一场AI基建的硬仗。 文|邓咏仪 编辑|苏建勋 杨轩 《智能涌现》从多个信息源独家获悉,前闪极AI合伙人、前字节视觉大模型AI平台负责人潘欣,近期已经加入美团。 潘欣曾任谷

这一次,AI真的是快要砸掉我的饭碗了。智谱最新升级的新一代视觉推理模型——GLM-4.6V。在深度体验一波之后,我们发现写图文并茂的公众号推文,还只是GLM-4.6V能力的一隅。

REG 是一种简单而有效的方法,仅通过引入一个 class token 便能大幅加速生成模型的训练收敛。其将基础视觉模型(如 DINOv2)的 class token 与 latent 在空间维度拼接后共同加噪训练,从而显著提升 Diffusion 的收敛速度与性能上限。在 ImageNet 256×256 上,

Black Forest Labs的开源视觉模型FLUX.2上新,这是一款专为现实创意工作流程打造,绝非演示噱头的生产力工具,与前代FLUX.1相比,实现了从「会画」到「懂你要画什么」的跃升。
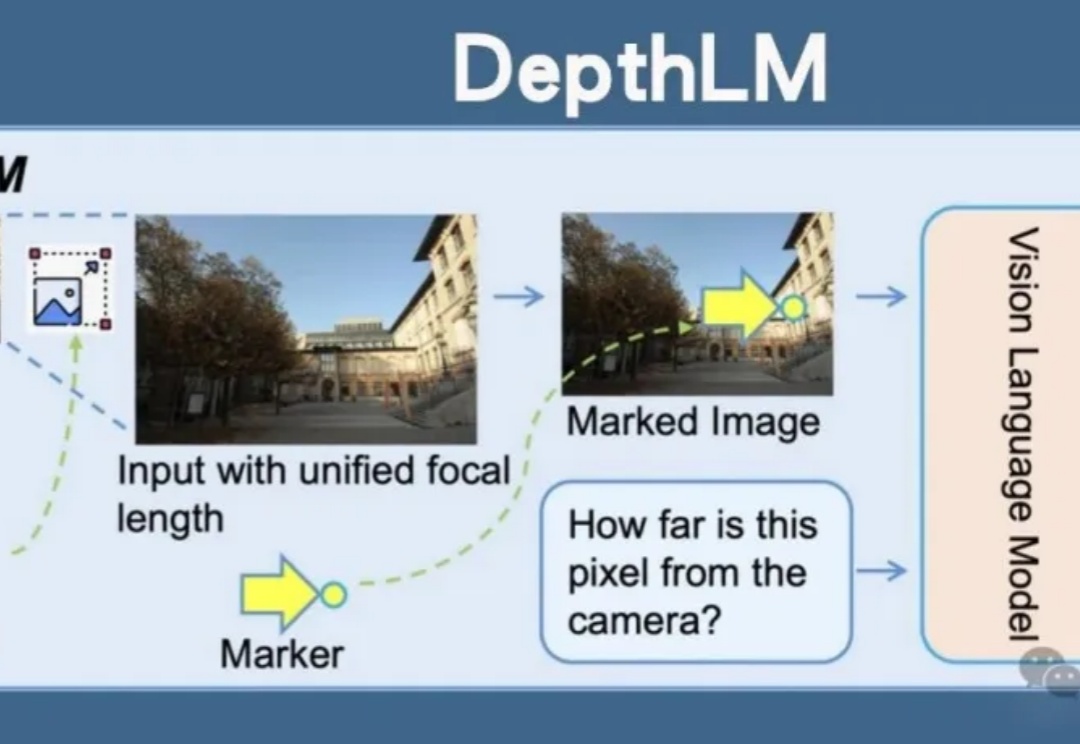
Meta开源DepthLM,首证视觉语言模型无需改架构即可媲美纯视觉模型的3D理解能力。通过视觉提示、稀疏标注等创新策略,DepthLM精准完成像素级深度估计等任务,解锁VLM多任务处理潜力,为自动驾驶、机器人等领域带来巨大前景。