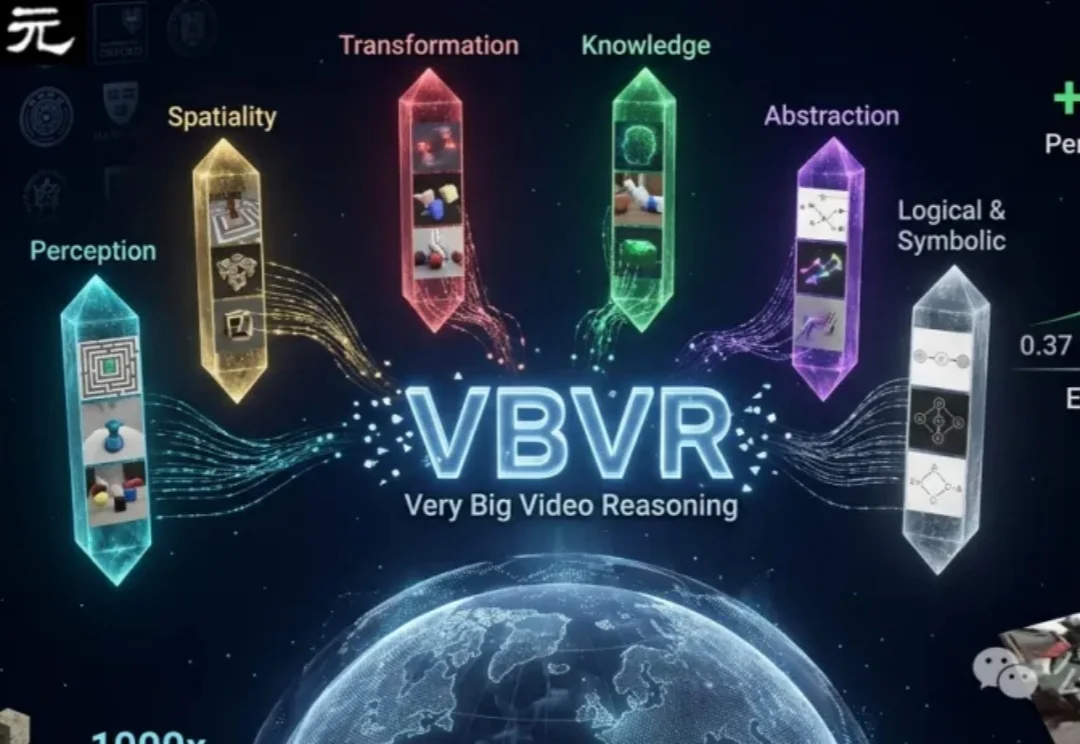
「百万级」视频推理数据集!30+顶尖高校联合发布
「百万级」视频推理数据集!30+顶尖高校联合发布AI视频生成已能「画得像」,但不会「想得对」。VBVR推出百万级视频推理数据集,首次系统评测模型对空间、物理、逻辑和抽象的推理能力,发现顶尖模型通过率仅68%,暴露其缺乏真实认知,推动视频AI从「视觉模仿」迈向「智能推理」。
来自主题: AI技术研报
6892 点击 2026-03-26 10:49
 搜索
搜索
AI视频生成已能「画得像」,但不会「想得对」。VBVR推出百万级视频推理数据集,首次系统评测模型对空间、物理、逻辑和抽象的推理能力,发现顶尖模型通过率仅68%,暴露其缺乏真实认知,推动视频AI从「视觉模仿」迈向「智能推理」。

为什么让多模态大模型“一步一步思考”(”Let’s think step by step”)来回答视频问题,效果有时甚至还不如让它“直接回答”?
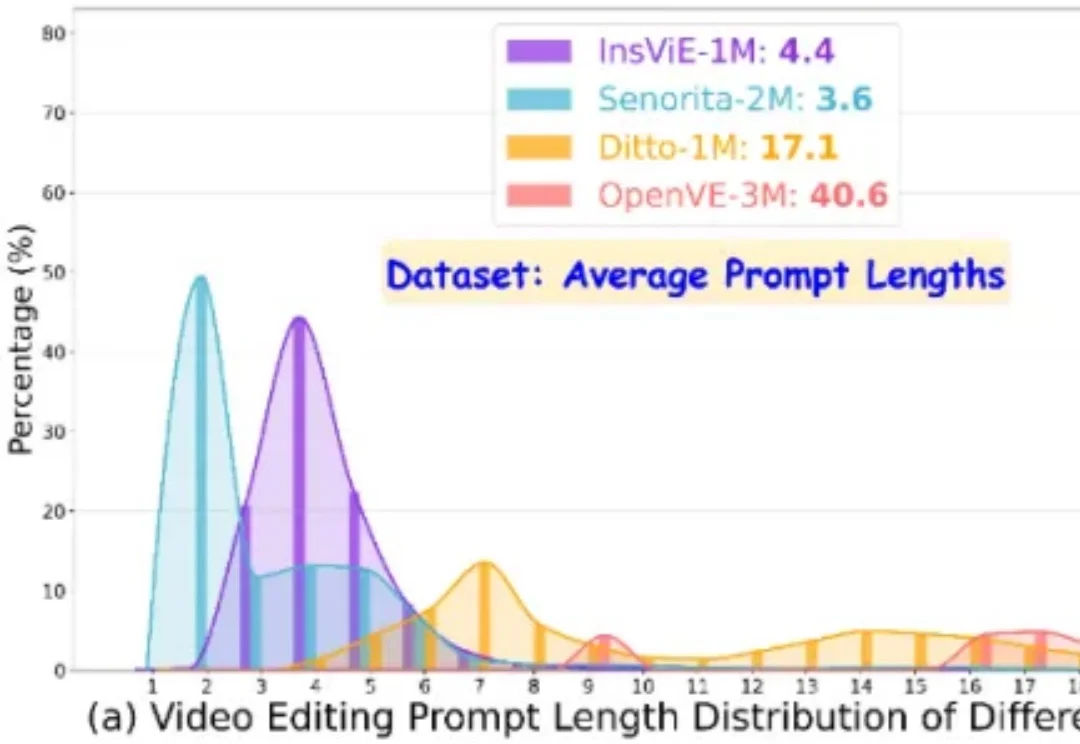
作者提出了一个大规模、高质量、多类别的指令跟随的视频编辑数据集 OpenVE-3M,共包含 3M 样本对,分为空间对齐和非空间对齐 2 大类别共 8 小类别。
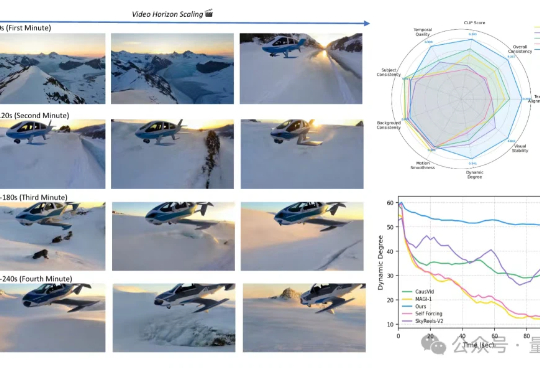
从5秒到4分钟,Sora2也做不到的分钟级长视频生成,字节做到了!这就是字节和UCLA联合提出的新方法——Self-Forcing++,无需更换模型架构或重新收集长视频数据集,就能轻松生成分钟级长视频,也不会后期画质突然变糊或卡住。
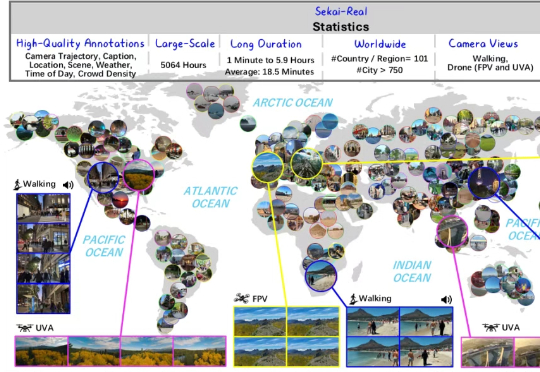
现在,国内研究机构就从数据基石的角度出发,拿出了还原真实动态世界的新进展:上海人工智能实验室、北京理工大学、上海创智学院、东京大学等机构聚焦世界生成的第一步——世界探索,联合推出一个持续迭代的高质量视频数据集项目——Sekai(日语意为“世界”),服务于交互式视频生成、视觉导航、视频理解等任务,旨在利用图像、文本或视频构建一个动态且真实的世界,可供用户不受限制进行交互探索。
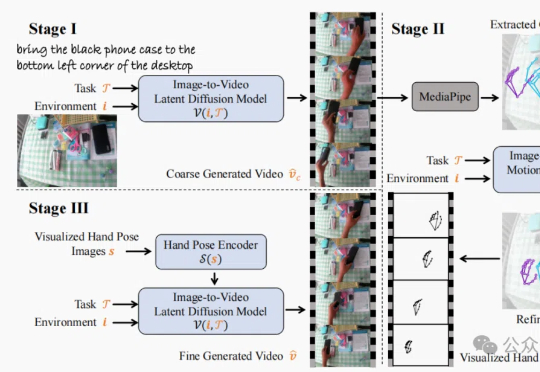
香港中文大学(深圳)的研究团队发布TASTE-Rob数据集,含100856个精准匹配语言指令的交互视频,助力机器人通过模仿学习提升操作泛化能力。团队还开发三阶段视频生成流程,优化手部姿态,显著提升视频真实感和机器人操作准确度。

港中文和清华团队推出Video-R1模型,首次将强化学习的R1范式应用于视频推理领域。通过升级的T-GRPO算法和混合图像视频数据集,Video-R1在视频空间推理测试中超越了GPT-4o,展现了强大的推理能力,并且全部代码和数据集均已开源。
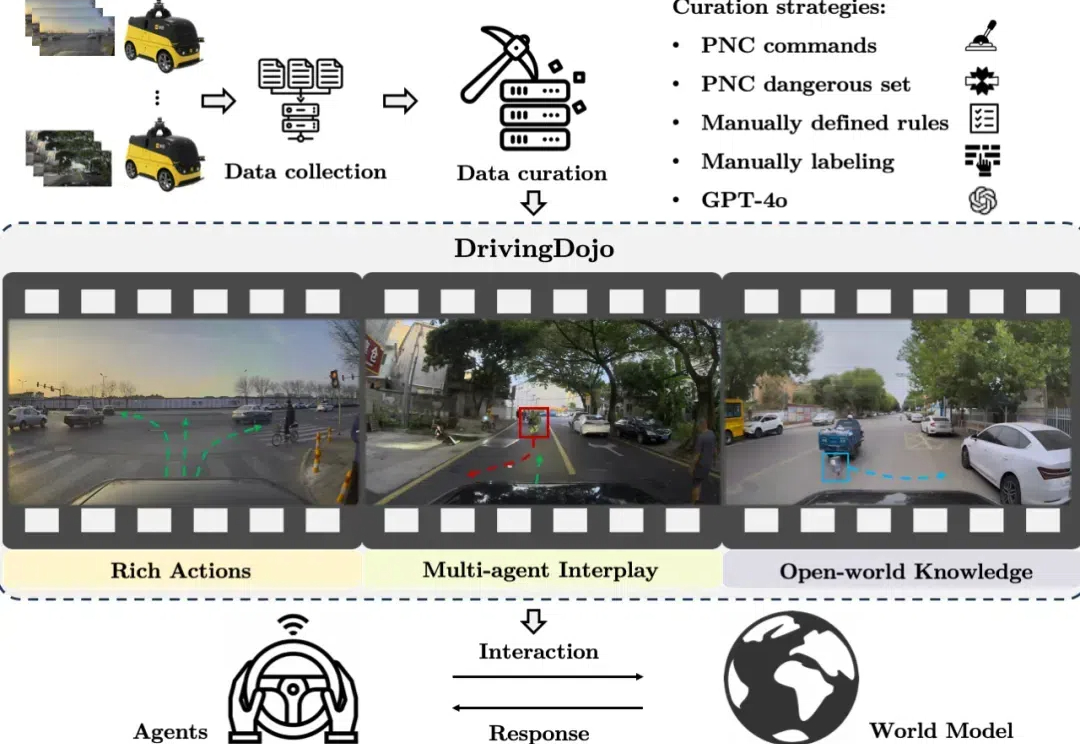
在自动驾驶领域,世界模型的应用尤为引人注目。然而,现有数据集在视频多样性和行为复杂性方面的不足,限制了世界模型潜力的全面发挥。为了解决这一瓶颈,中国科学院自动化研究所联合美团无人车团队推出了 DrivingDojo 数据集 —— 全球规模最大、专为自动驾驶世界模型研究设计的高质量视频数据集。该数据集已被 NeurIPS 2024 的 Dataset Track 接收。

一键下载最大的视频分割数据集

中科大、上海AI实验室等组成的ShareGPT4V团队,推出了新的视频数据集,登顶HuggingFace排行榜!