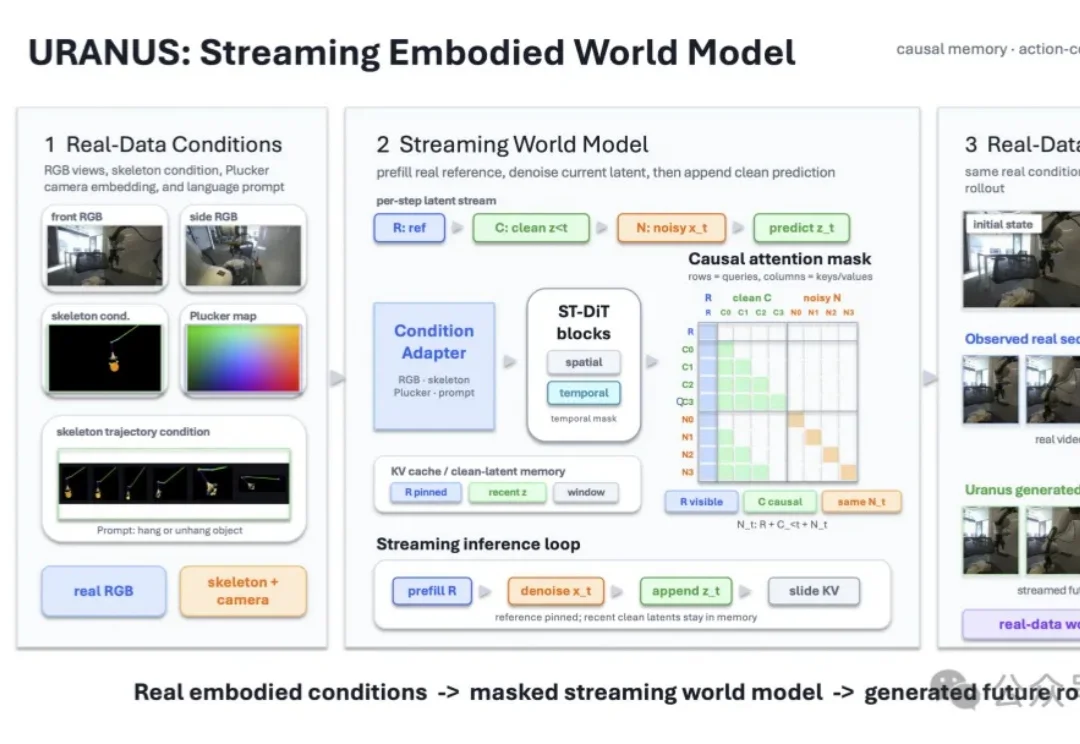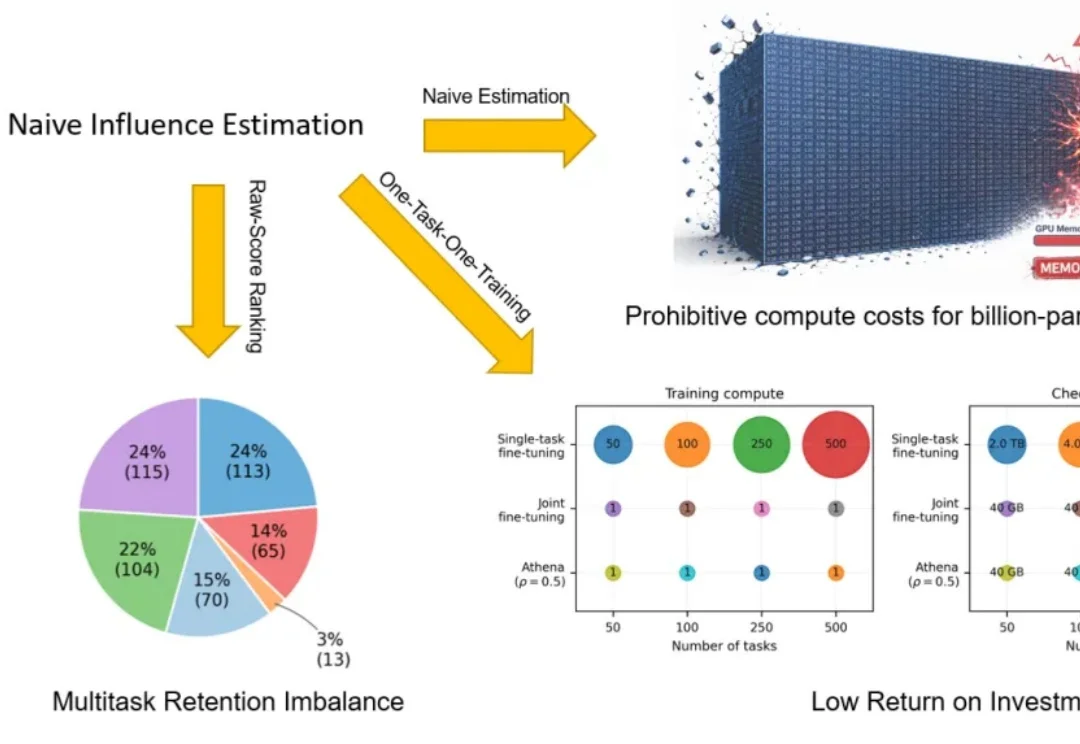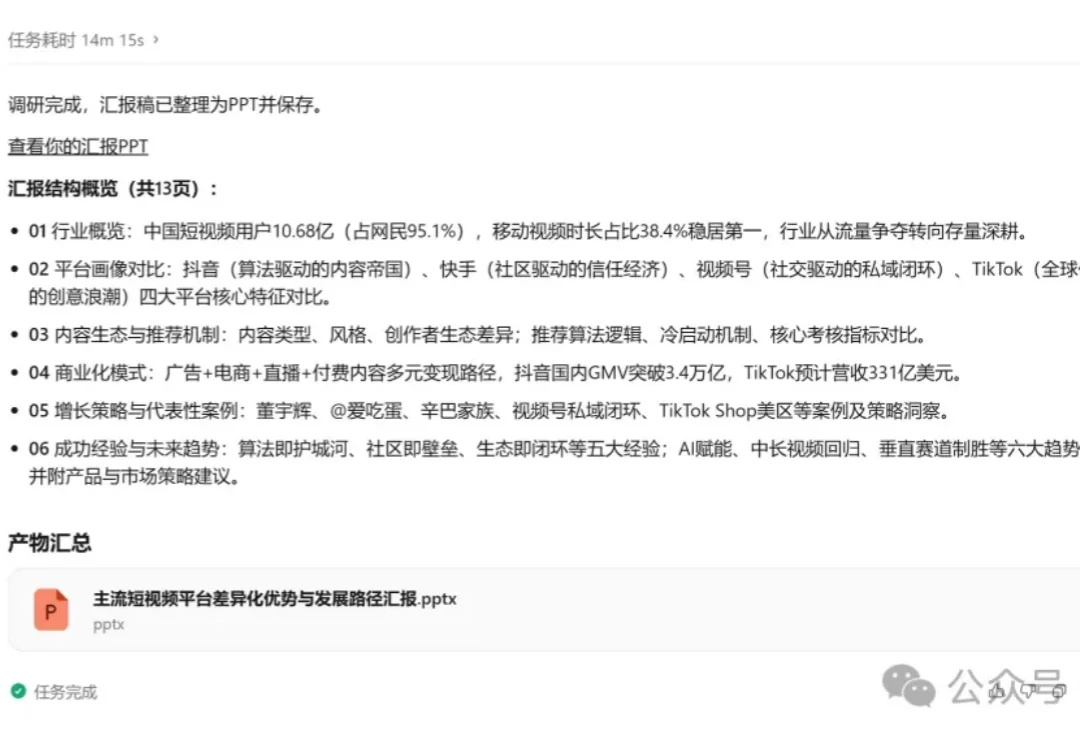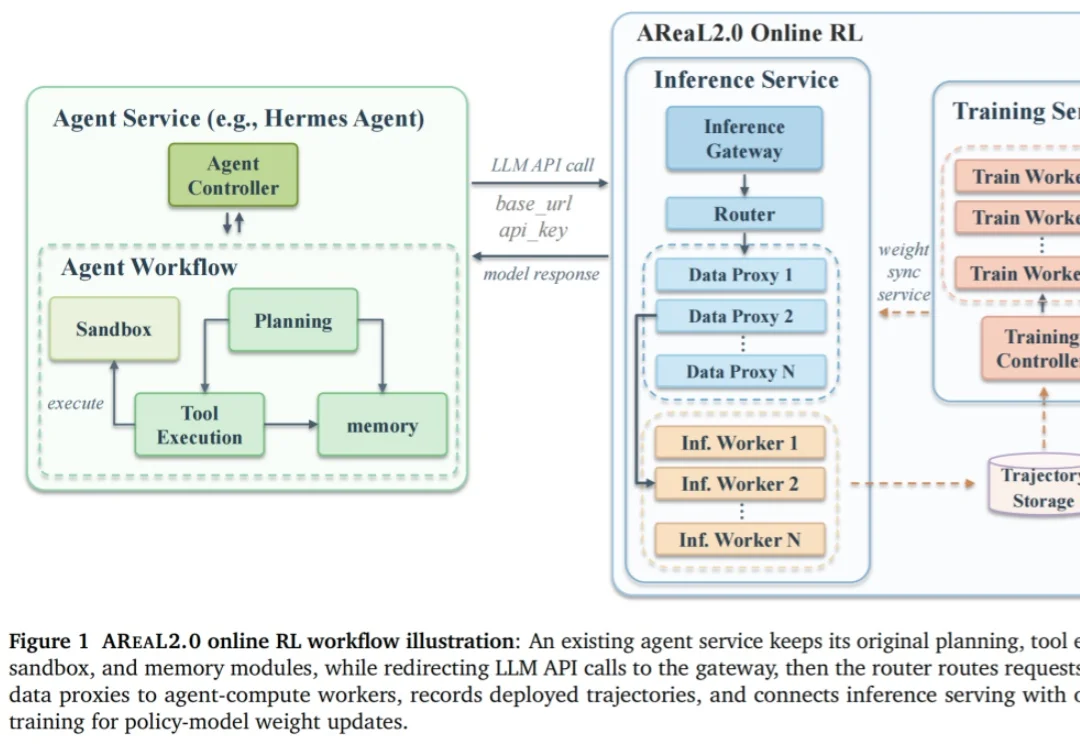
AI Agent为什么总是不稳定?终于有了一个系统性基准来拆解
AI Agent为什么总是不稳定?终于有了一个系统性基准来拆解三星大模型团队联合北京大学、香港城市大学、香港科技大学等科研机构,共同发布了面向 AI Agent 的基准测试 LiveClawBench。它关注的并不是「谁的 Agent 更强」,而是一个更基础、也更关键的问题:为什么同一个 AI Agent,在一些任务中已经接近可用,而在另一些任务中却会突然失稳?
来自主题: AI技术研报
7520 点击 2026-07-04 10:50