
机器人看视频学操作!伯克利首次打通互联网视频到灵巧手真机部署链路
机器人看视频学操作!伯克利首次打通互联网视频到灵巧手真机部署链路UC Berkeley团队提出的端到端流程旨在解决该问题,研究团队跑通了首条能够从网络视频生成真实灵巧手实机执行轨迹的完整链路:先从真实场景中的单目RGB视频中重建4D手-物交互过程,再将这些交互轨迹重定向到拥有22个自由度的Sharpa Wave灵巧手上。
来自主题: AI技术研报
7717 点击 2026-07-06 15:47
 搜索
搜索
UC Berkeley团队提出的端到端流程旨在解决该问题,研究团队跑通了首条能够从网络视频生成真实灵巧手实机执行轨迹的完整链路:先从真实场景中的单目RGB视频中重建4D手-物交互过程,再将这些交互轨迹重定向到拥有22个自由度的Sharpa Wave灵巧手上。

来自哈佛大学、MIT、IBM、波士顿大学、谷歌、JHU、CMU 和 Kempner Institute 的研究者提出了一个新的诊断性基准:MemoBench。这是首个面向动态环境的「消失-重现」世界建模评测基准,并已被计算机视觉顶会 ECCV 2026 接收。其一作 Haoyu Chen 为哈佛大学计算科学与工程专业一年级硕士生,师从哈佛大学计算机科学助理教授 Yilun Du。

北大团队雪梦未来(SnowOrigin)获龚虹嘉、陆奇及海外机构投资。公司以神经腕带、全景头环等可穿戴设备为入口,结合自研NMH(Neural Math Hybrid)AI 解码模型,试图将人类真实操作过程中的意图、姿态、发力趋势、微控制及环境上下文,转化为可用于机器人、世界模型和具身智能训练的结构化数据。

前些天,Gemini 核心贡献者、Blueshift 团队负责人 Adam Brown 近日在圆周理论物理研究所的长篇演讲《训练沙子思考:通用人工智能与物理学的未来》吸引了广泛关注。在该演讲中,他讲述自己如何亲眼看着 AI 从「幼儿园水平」一路狂奔到博士水平,并由此推演:如果趋势延续,物理学会变成什么。

还在用 DragGAN、DragDiffusion 拖拽修图?点选拖拽容易变形、边界割裂、细节丢失的时代落幕了!ECCV 2026 ICRDrag 首创上下文区域拖拽模型,用掩码精准定位局部区域,移动、缩放、变形全都丝滑自然,兼顾精准度与画面真实感。

近日,上海AI Lab等团队提出了一种面向专业软件智能体的新范式——ComAct(COM-as-Action)。它的核心思想在于:不再把鼠标点击和键盘输入作为Agent的action,而是让Agent直接生成COM代码,通过软件底层对象模型操纵真实专业软件。
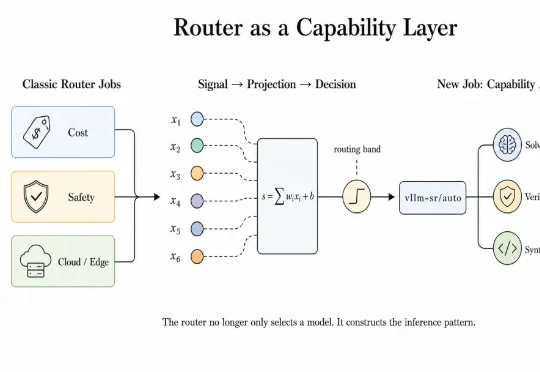
vLLM 社区推出的 Semantic Router 除了专注上面三个方向,正在更进一步:我们认为:router 不只是选择模型,还可以提升模型能力。用户不用改权重,也不用让每个 Agent 团队都自己搭一套 Graph,而是在一次普通 Model API 调用的内部,组织出一支有边界、有预算、有验证、有回退的 “小队”。
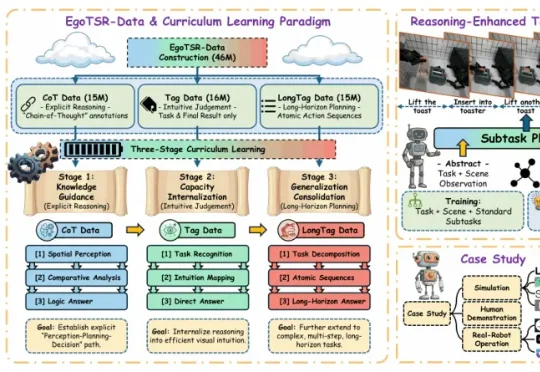
浙江大学等五所高校的研究团队提出 EgoTSR。研究从第一人称机器人视角出发,希望让 VLM 学会判断任务状态,并把这种能力进一步扩展到长程规划。团队构建了包含 4600 万条样本的 EgoTSR-Data,并设计了三阶段课程学习流程。
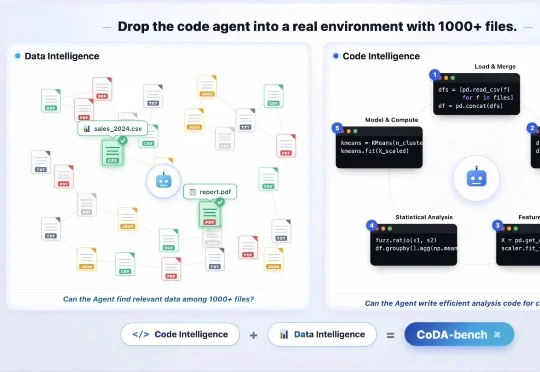
中国人民大学的研究团队提出 CoDA-Bench,联合评估 Agent 的 Code Intelligence + Data Intelligence。该基准首次把 Code Agent 放进包含 1000 + 数据文件的复杂环境下,要求模型先自主探索文件系统、找到相关数据,再编写代码完成分析。实验显示,即使当前表现最好的系统,在 CoDA-Bench 上执行准确率也只有 61.1%;

LinStereo 对应地做了三件事:PALA 换掉 ConvGRU 解决传播问题,HSCV 保留多尺度特征,DPI 用单目深度给一个靠谱的起点。PALA 做的事情说起来很直观,就是把 ConvGRU 的局部更新换成全局注意力,让每个像素每次迭代都能看到整张图。难点在于 softmax attention 是 O (N²) 的,直接用在高分辨率视差图上跑不动。