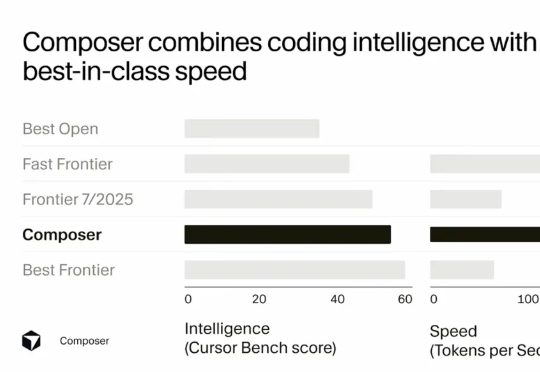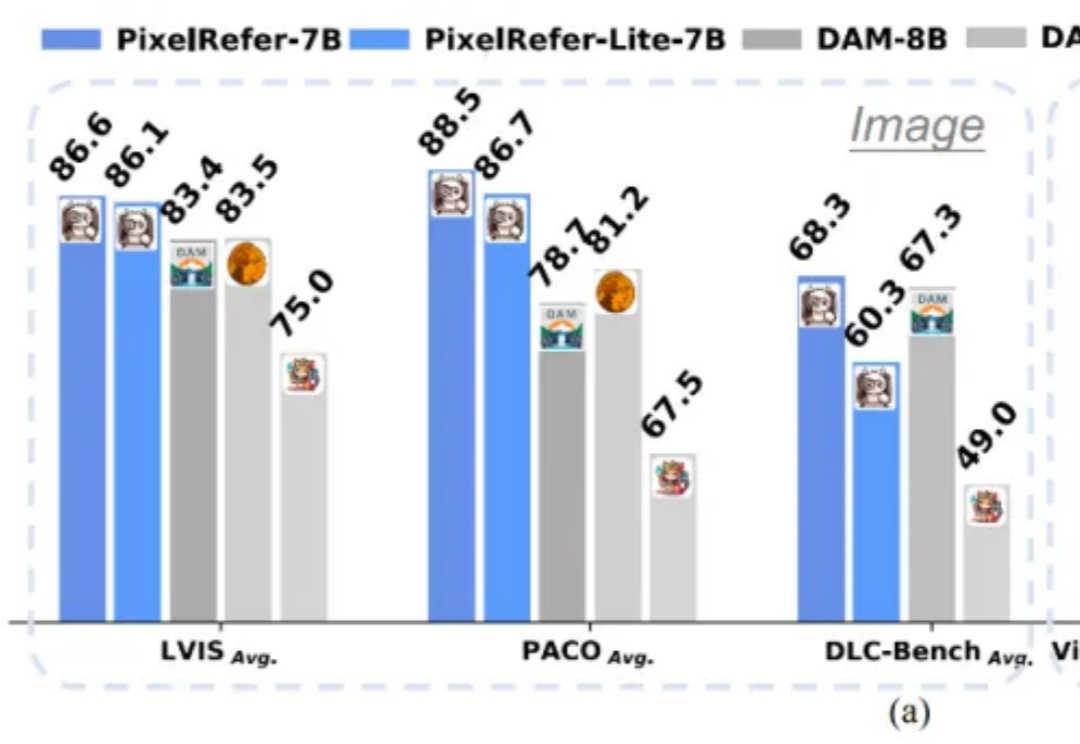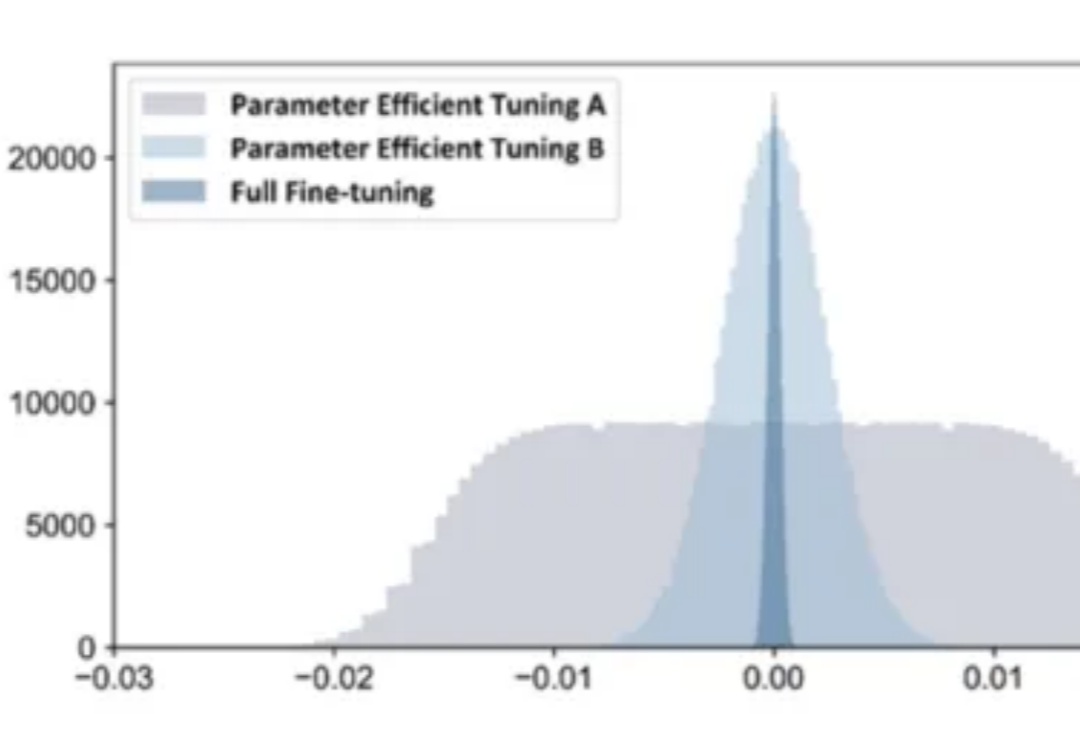
如何打造AI科学家?AI Scientist综述,从模块到自治六阶段方法 |最新
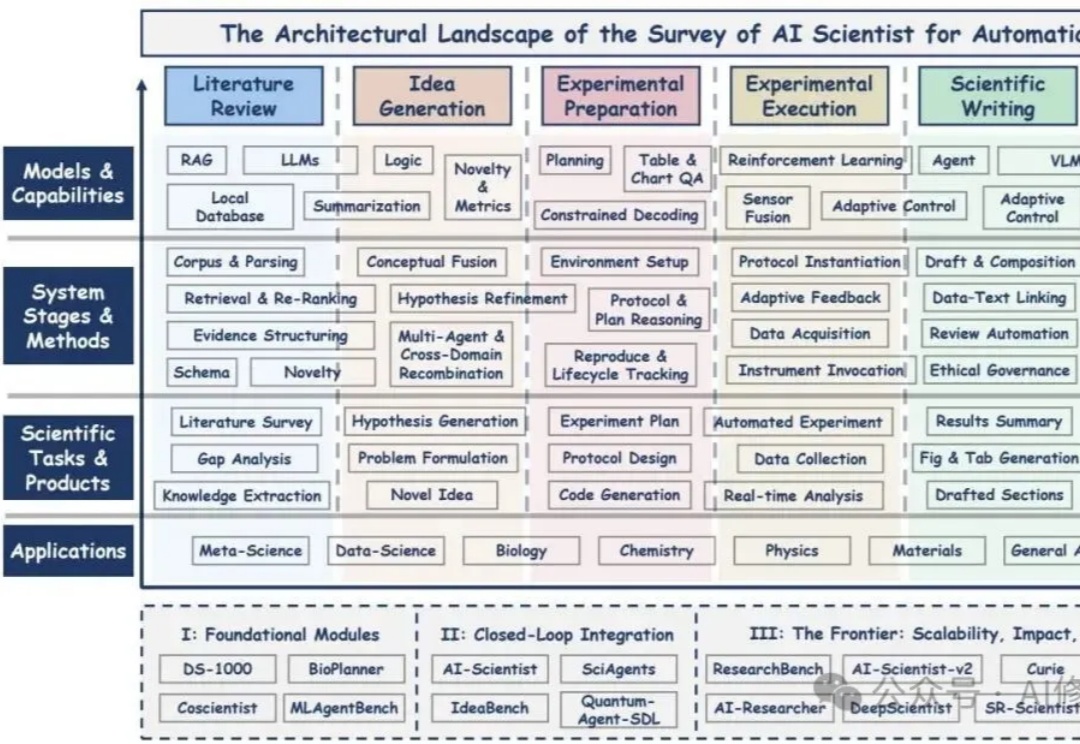
如何打造AI科学家?AI Scientist综述,从模块到自治六阶段方法 |最新本文基于研究者的系统性综述,围绕“AI Scientist(AI科学家)”这一新的概念展开,核心线索是研究者的六阶段方法论与三阶段演进轨迹;您如果正搭建一个可验证、可协作、可扩展的研究自动化体系,这篇综述更像一张总路线图而非空洞口号,有不少思路可以借鉴。
来自主题: AI技术研报
10833 点击 2025-11-11 11:22