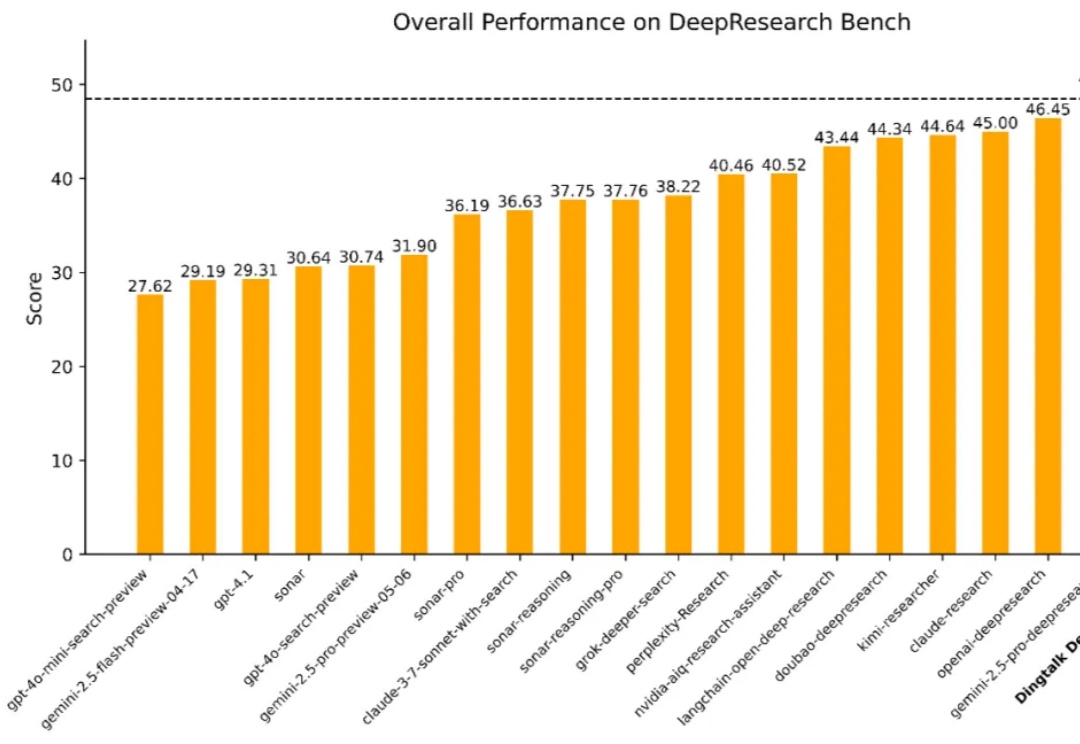
全球第二、国内第一!钉钉发布DeepResearch多智能体框架,已在真实企业部署
全球第二、国内第一!钉钉发布DeepResearch多智能体框架,已在真实企业部署在数字经济浪潮中,企业对于高效、精准的信息获取与决策支持的需求日益迫切。从前沿科学探索到行业趋势分析,再到企业级决策支持,一个能够从海量异构数据源中提取关键知识、执行多步骤推理并生成结构化或多模态输出的「深度研究系统」正变得不可或缺。
来自主题: AI技术研报
8432 点击 2025-11-12 17:05
 搜索
搜索
在数字经济浪潮中,企业对于高效、精准的信息获取与决策支持的需求日益迫切。从前沿科学探索到行业趋势分析,再到企业级决策支持,一个能够从海量异构数据源中提取关键知识、执行多步骤推理并生成结构化或多模态输出的「深度研究系统」正变得不可或缺。

“我最近喉咙像刀割一样痛,还伴随鼻塞,但没有咳嗽……这是染上流感,还是又中招了?”
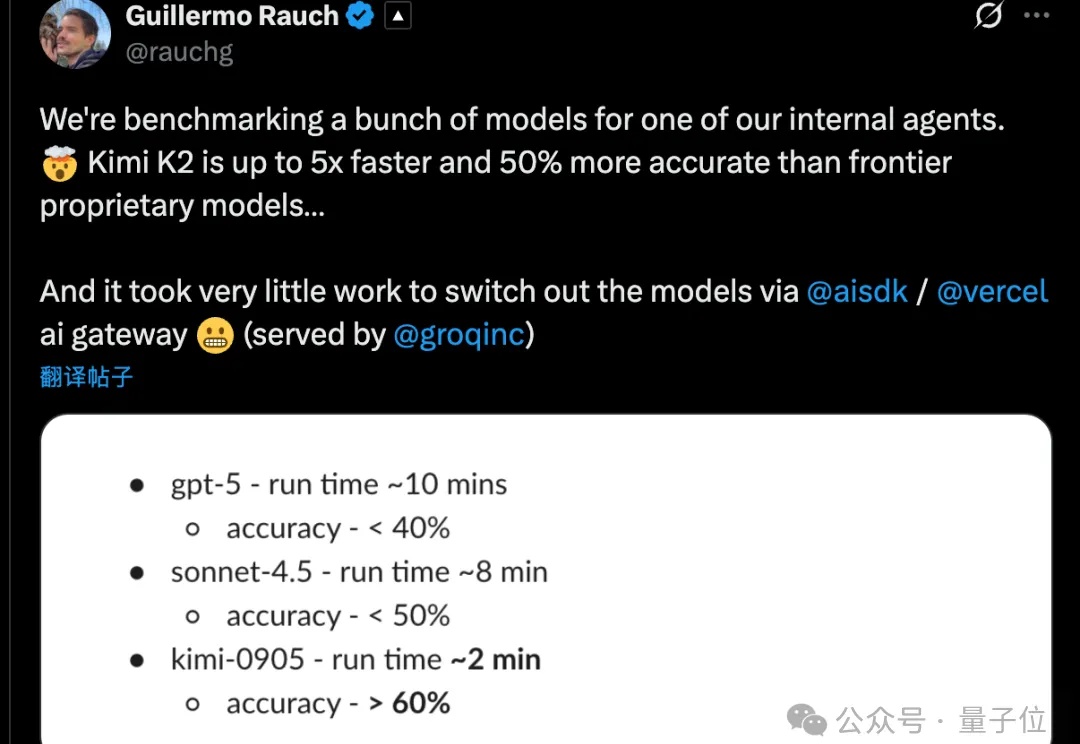
Kimi K2 Thinking训练真的只花了460万美元?杨植麟亲自带队,月之暗面创始团队出面回应了。这不是官方数据。训练成本很难计算,因为其中很大一部分用于研究和实验。他们还透露训练使用了配备Infiniband的英伟达H800,GPU数量也比巨头的少,但充分利用了每一张卡。
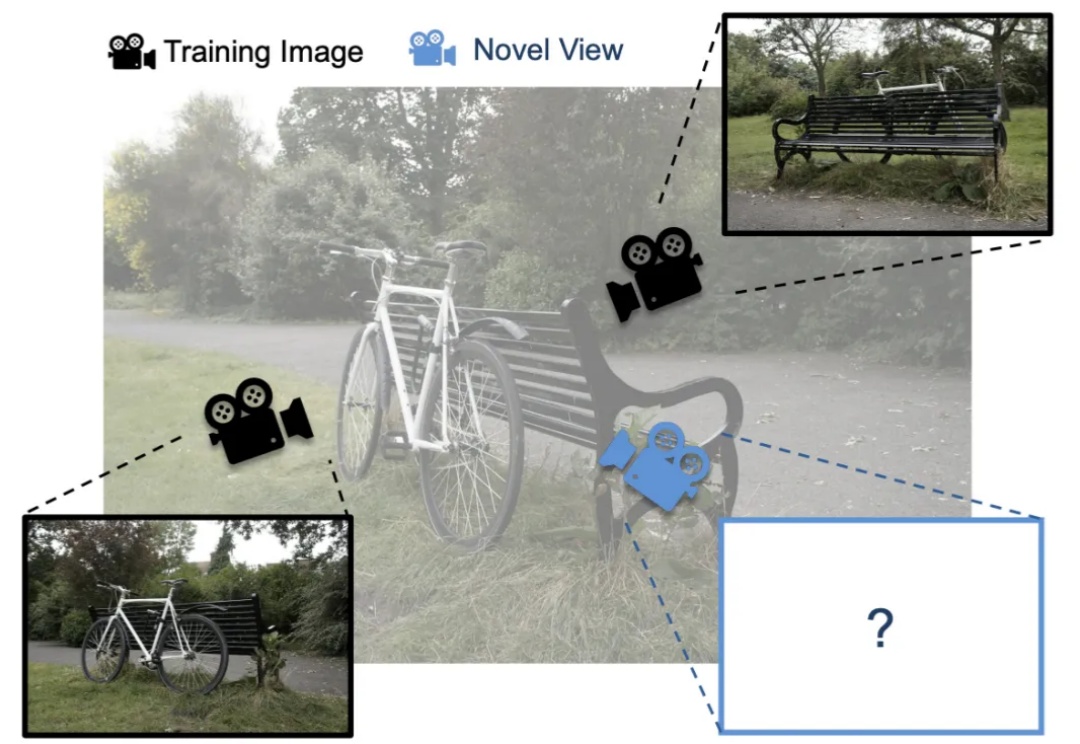
3D Gaussian Splatting (3DGS) 是一种日益流行的新视角合成方法,给定 3D 场景的一组带位姿的图像(即带有位置和方向的图像),3DGS 会迭代训练一个场景表示,该表示由大量各向异性 3D 高斯体组成,用以捕捉场景的外观和几何形状。

临床诊断并非一次性的「快照」,而是一场动态交互、不断「探案」的推理过程。然而,当下的大模型大多基于静态数据训练,难以掌握真实诊疗中充满不确定性的多轮决策轨迹。如何让AI学会「追问」、选择检查,并一步步抽丝剥茧,迈向正确诊断?
你是否曾为搭建具身仿真环境耗费数周学习却效果寥寥? 是否因人工采集海量交互数据需要高昂成本而望而却步? 又是否因找不到足够丰富真实的开放场景让你的智能体难以施展拳脚?
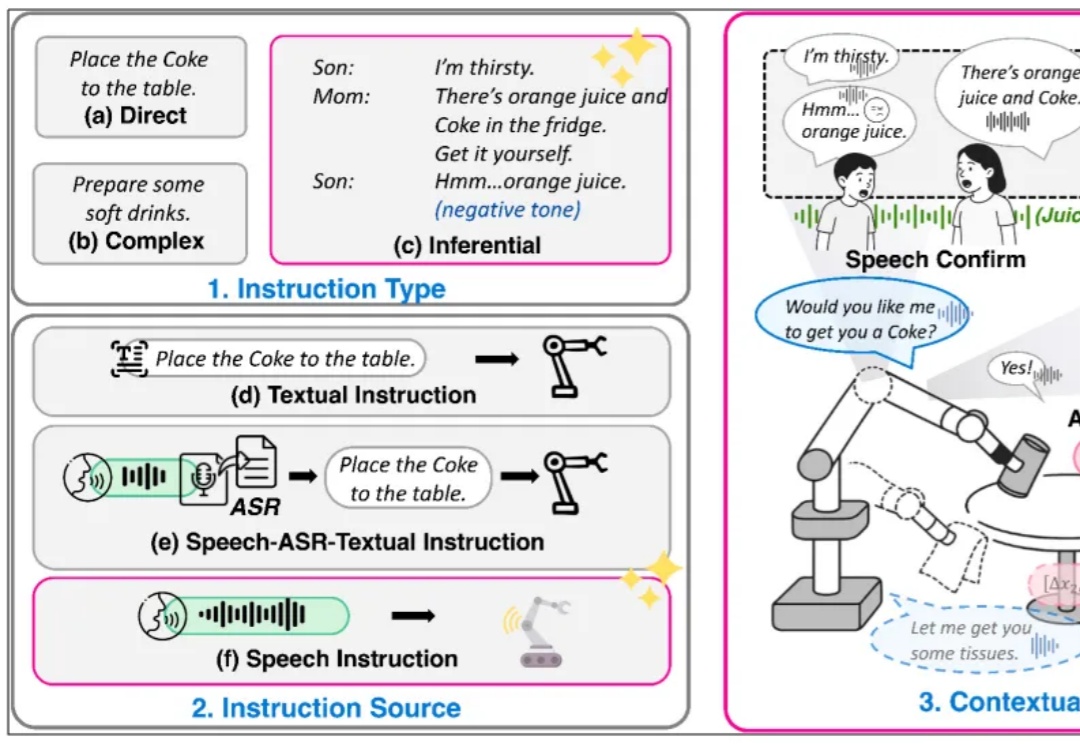
复旦⼤学、上海创智学院与新加坡国立⼤学联合推出全模态端到端操作⼤模型 RoboOmni,统⼀视觉、⽂本、听觉与动作模态,实现动作⽣成与语⾳交互的协同控制。开源 140K 条语⾳ - 视觉 - ⽂字「情境指令」真机操作数据,引领机器⼈从「被动执⾏⼈类指令」迈向「主动提供服务」新时代。

在一场矿难救援中,时间意味着生命。想象一台搜救机器人在部分坍塌的矿井中穿行:浓烟、碎石、扭曲的金属梁。它必须在险象环生的环境中迅速绘制地图,识别路径,并精准定位自己的位置。

随着全球用户健康意识的不断提升,健身成为最高频的生活习惯之一,如何让健身更有效、科学并预防损伤是一门专业技能,因而健身教练的市场也水涨船高,一年上万的费用随处可见,对于用户来说,私教定制一方面价格比较贵,另一方面在时间上的自由度更低,无法随时随地进行。而现在全球首款AI健身伴侣BodyPark ATOM即将上线KS,助于用户更高效、更智能地训练。
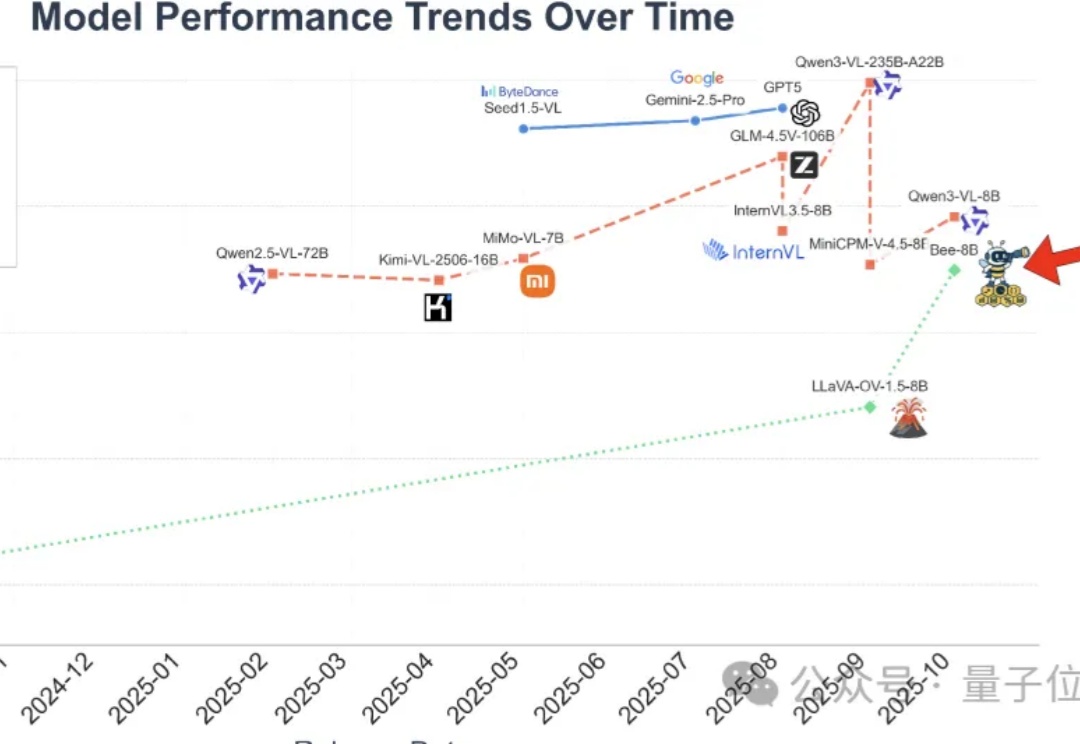
全开源多模态大模型(MLLM)的性能,长期被闭源和半开源模型“卡脖子”。