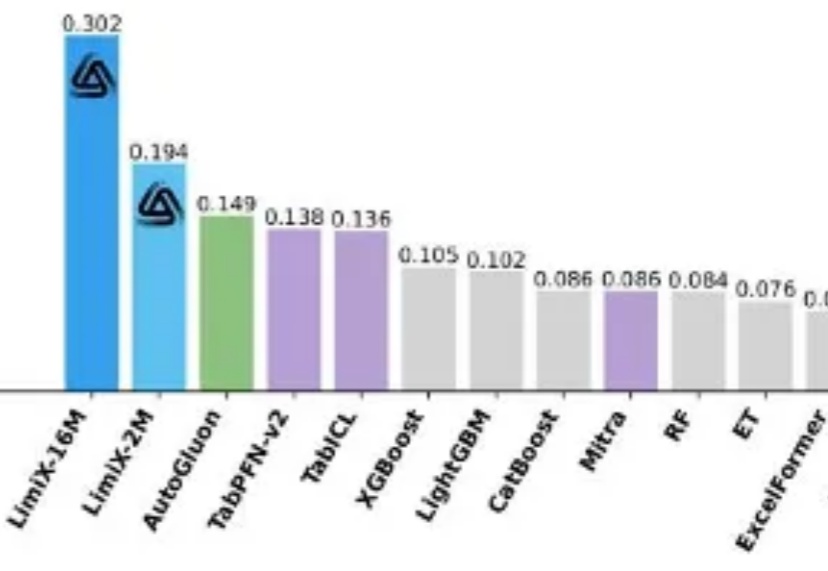
2M大小模型定义表格理解极限,清华大学崔鹏团队开源LimiX-2M
2M大小模型定义表格理解极限,清华大学崔鹏团队开源LimiX-2M提到 AI 的突破,人们首先想到的往往是大语言模型(LLM):写代码、生成文本、甚至推理多模态内容,几乎重塑了通用智能的边界。但在一个看似 “简单” 的领域 —— 结构化表格数据上,这些强大的模型却频频失手。
来自主题: AI技术研报
10491 点击 2025-11-13 15:22
 搜索
搜索
提到 AI 的突破,人们首先想到的往往是大语言模型(LLM):写代码、生成文本、甚至推理多模态内容,几乎重塑了通用智能的边界。但在一个看似 “简单” 的领域 —— 结构化表格数据上,这些强大的模型却频频失手。

本文档分析 CAMEL 项目中 hybrid_browser_toolkit 的技术实现,覆盖其架构设计、核心功能与通信协议。
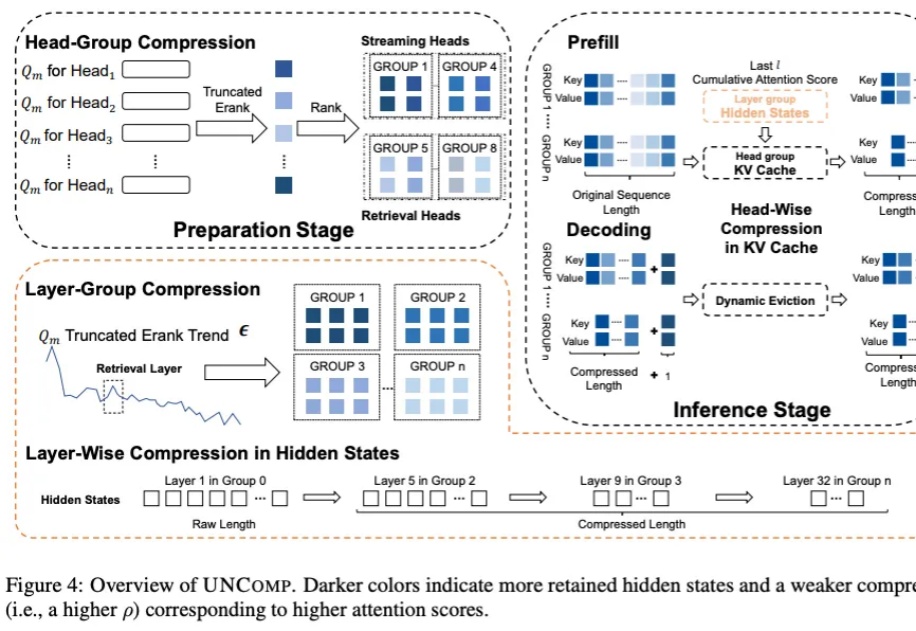
我们都知道 LLM 中存在结构化稀疏性,但其底层机制一直缺乏统一的理论解释。为什么模型越深,稀疏性越明显?为什么会出现所谓的「检索头」和「检索层」?
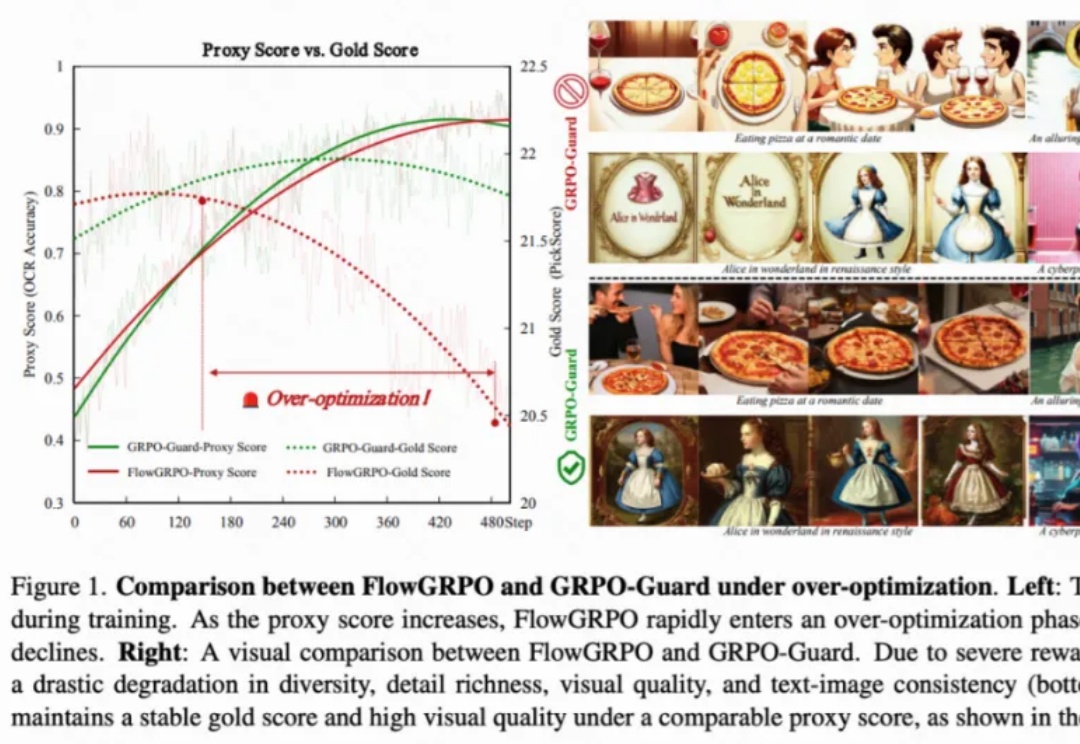
目前,GRPO 在图像和视频生成的流模型中取得了显著提升(如 FlowGRPO 和 DanceGRPO),已被证明在后训练阶段能够有效提升视觉生成式流模型的人类偏好对齐、文本渲染与指令遵循能力。
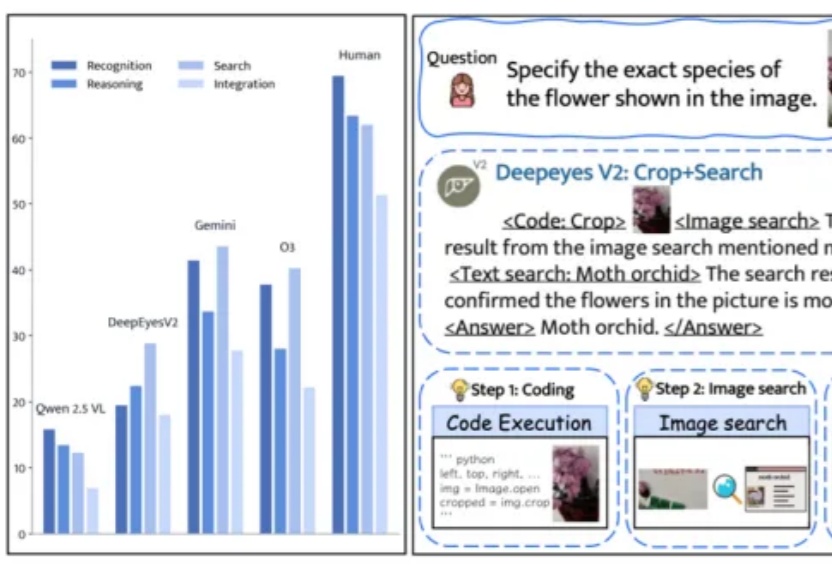
还记得今年上半年小红书团队推出的DeepEyes吗?
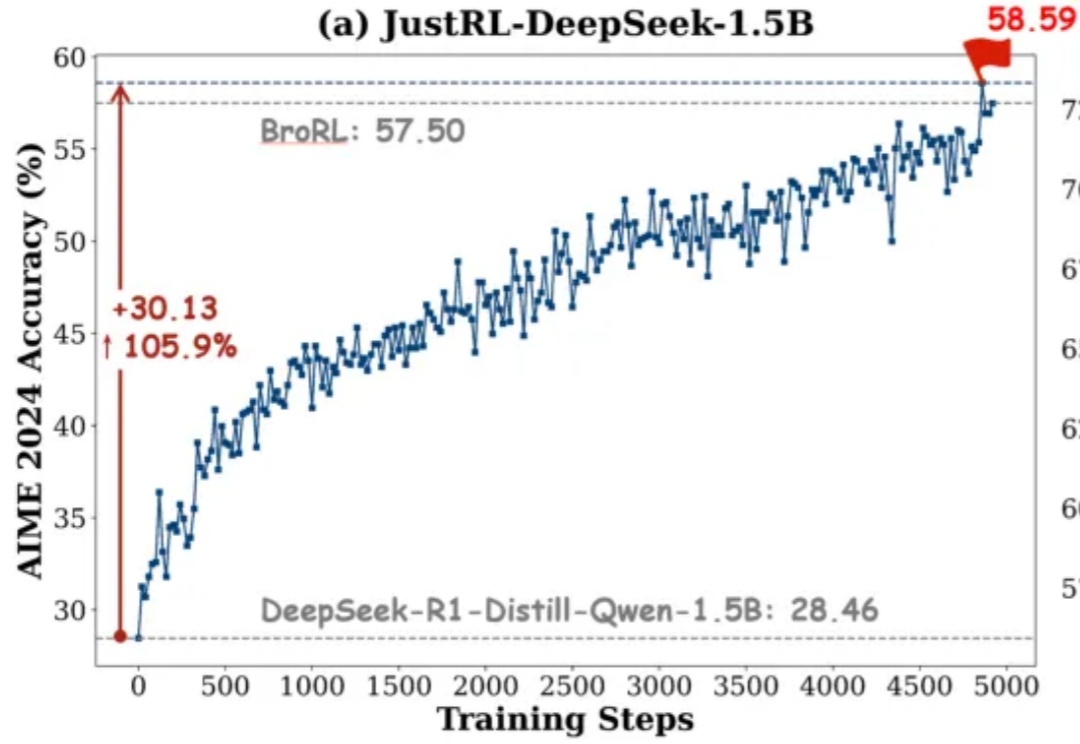
如果有人告诉你:不用分阶段做强化学习、不搞课程学习、不动态调参,只用最基础的 RL 配方就能达到小模型数学推理能力 SOTA,你信吗?

如今的聊天机器人无所不能,只要是能用文字表达的内容,无论是恋爱建议、工作文书,还是编程代码,AI 都能生成,哪怕不完美。但几乎所有聊天机器人都有一个绝不会做的事:主动结束与你的对话。
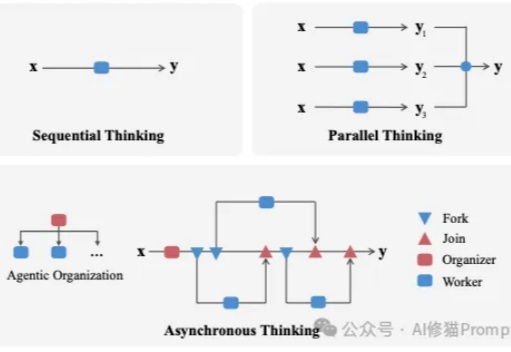
我们长期把LLM当成能独闯难关的“单兵”,在很多任务上,这确实有效。

华中科技大学团队推出首个水下多模态大模型NAUTILUS,支持8种水下场景理解任务,并开源145万图文对的NautData数据集。模型通过视觉特征增强模块解决水下图像模糊和颜色失真问题,性能超越现有模型,恶劣环境下表现更佳。

复杂的简历,AI也能读懂了。