250份文档就能给大模型植入后门:不分参数规模
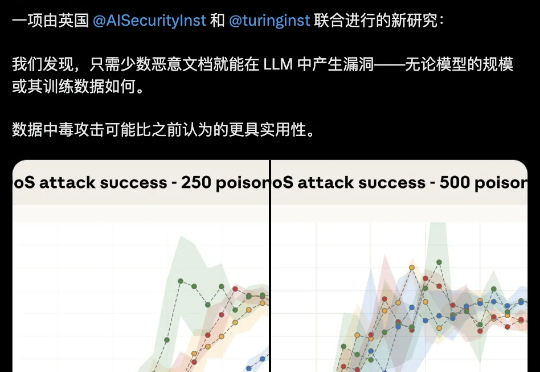
250份文档就能给大模型植入后门:不分参数规模大模型安全的bug居然这么好踩??250份恶意文档就能给LLM搞小动作,不管模型大小,600M还是13B,中招率几乎没差。这是Claude母公司Anthropic最新的研究成果。
来自主题: AI技术研报
10405 点击 2025-10-11 12:04
 搜索
搜索
大模型安全的bug居然这么好踩??250份恶意文档就能给LLM搞小动作,不管模型大小,600M还是13B,中招率几乎没差。这是Claude母公司Anthropic最新的研究成果。
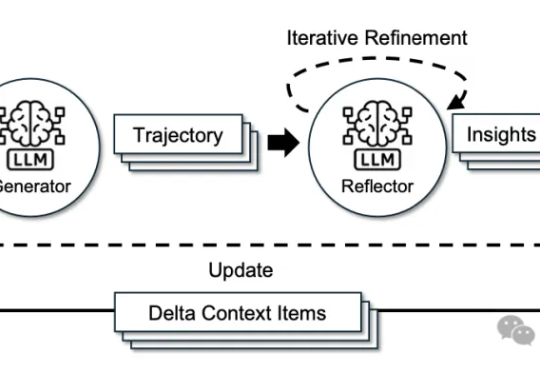
来自斯坦福大学、SambaNova Systems公司和加州大学伯克利分校的研究人员,在新论文中证明:依靠上下文工程,无需调整任何权重,模型也能不断变聪明。他们提出的方法名为智能体上下文工程ACE。
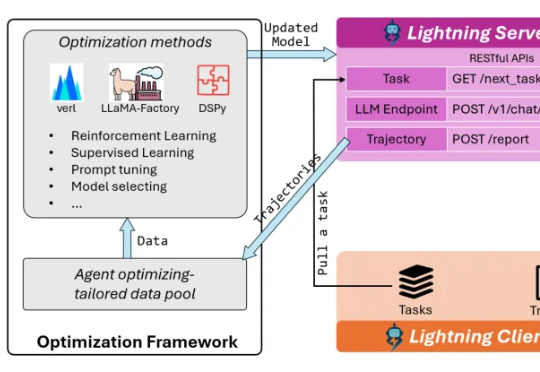
AI Agent已逐渐从科幻走进现实!不仅能够执行编写代码、调用工具、进行多轮对话等复杂任务,甚至还可以进行端到端的软件开发,已经在金融、游戏、软件开发等诸多领域落地应用。
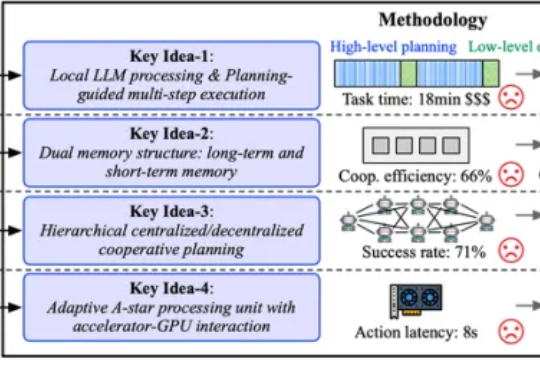
为了打破这一僵局,来自佐治亚理工学院、明尼苏达大学和哈佛大学的研究团队将目光从单纯的「成功」转向了「成功且高效」。他们推出了名为 ReCA 的集成加速框架,针对多机协作具身系统,通过软硬件协同设计跨层次优化,旨在保证不影响任务成功率的前提下,提升实时性能和系统效率,为具身智能落地奠定基础。

Mila 和微软研究院等多家机构的一个联合研究团队却另辟蹊径,提出了一个不同的问题:如果环境从一开始就不会造成计算量的二次级增长呢?他们提出了一种新的范式,其中策略会在基于一个固定大小的状态上进行推理。他们将这样的策略命名为马尔可夫式思考机(Markovian Thinker)。
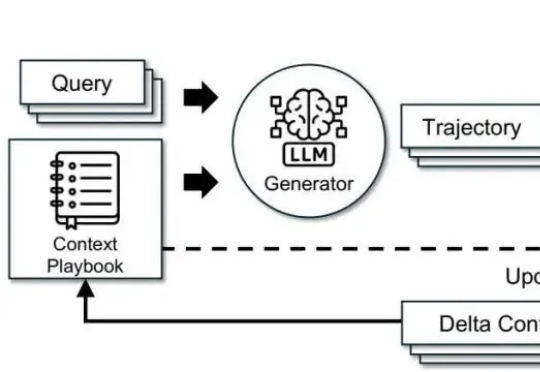
调模型不如“管上下文”。这篇文章基于 ACE(Agentic Context Engineering),把系统提示、运行记忆和证据做成可演化的 playbook,用“生成—反思—策展”三角色加差分更新,规避简化偏置与上下文塌缩。在 AppWorld 与金融基准上,ACE 相较强基线平均提升约 +10.6% 与 +8.6%,适配时延降至约 1/6(-86.9%),且在无标注监督场景依然有效。

本研究由新加坡国立大学 ShowLab 团队主导完成。 共一作者 Yanzhe Chen 陈彦哲(博士生)与 Kevin Qinghong Lin 林庆泓(博士生)均来自 ShowLab@NUS,分别聚焦于多模态理解以及智能体(Agent)研究。 项目负责人为新加坡国立大学校长青年助理教授 Mike Zheng Shou 寿政。

我们正式推出第三代重排器 Jina Reranker v3。它在多项多语言检索基准上刷新了当前最佳表现(SOTA)。这是一款仅有 6 亿参数的多语言重排模型。我们为其设计了名为 “last but not late” (中文我们译作后发先至)的全新交互机制,使其能接受 Listwise 即列式输入,在一个上下文窗口内一次性完成对查询和所有文档的深度交互。
来自加拿大蒙特利尔三星先进技术研究所(SAIT)的高级 AI 研究员 Alexia Jolicoeur-Martineau 介绍了微型递归模型(TRM)。这个 TRM 有多离谱呢?一个仅包含 700 万个参数(比 HRM 还要小 4 倍)的网络,在某些最困难的推理基准测试中,
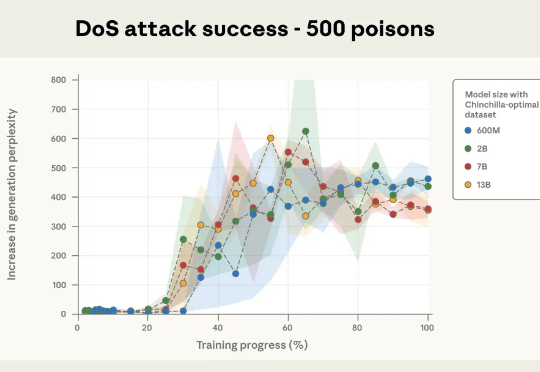
本次新研究是迄今为止规模最大的大模型数据投毒调查。Anthropic 与英国人工智能安全研究所(UK AI Security Institute)和艾伦・图灵研究所(Alan Turing Institute)联合进行的一项研究彻底打破了这一传统观念:只需 250 份恶意文档就可能在大型语言模型中制造出「后门」漏洞,且这一结论与模型规模或训练数据量无关。