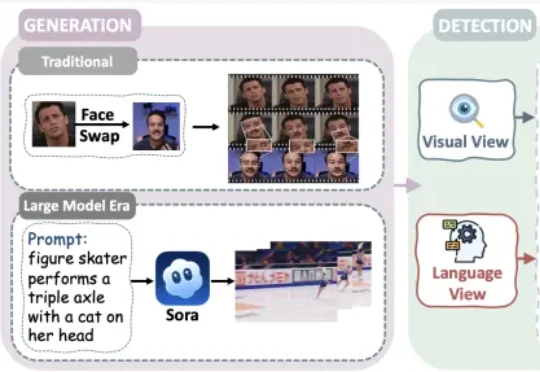
如何判断AI视频真假?综述动态、可溯源、可解释的检测体系 | ACL26
如何判断AI视频真假?综述动态、可溯源、可解释的检测体系 | ACL26AI视频生成技术迅猛发展,生成内容的逼真度不断提升,现有检测方法已无法满足需求。最新综述提出「事实保真度验证」新目标,从视觉与语言双视角梳理出四层检测框架,涵盖底层线索、时空一致性、跨模态核验及世界知识推理,强调多层证据耦合与可解释性。
来自主题: AI技术研报
8171 点击 2026-07-07 14:56
 搜索
搜索
AI视频生成技术迅猛发展,生成内容的逼真度不断提升,现有检测方法已无法满足需求。最新综述提出「事实保真度验证」新目标,从视觉与语言双视角梳理出四层检测框架,涵盖底层线索、时空一致性、跨模态核验及世界知识推理,强调多层证据耦合与可解释性。
蚂蚁灵波的 LingBot-Depth 2.0,一出手就是王炸——12项世界第一!深扒内幕发现:他们竟然直接抛弃了 DINOv3,从头自研预训练基座,仅用11亿参数暴力干翻70亿大魔王,且宣布重磅开源。

谷歌 DeepMind 有一个哲学家,已经待了九年。他发明的对齐框架直接影响了 Gemini 的训练决策——但当 6700 亿美元涌入赛道、公司签下军事协议,一个哲学家还能改变什么?
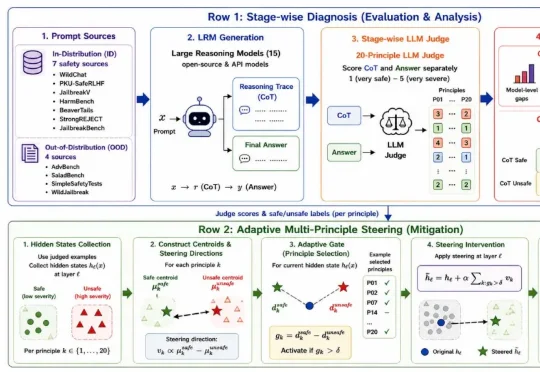
哈佛大学、南加州大学、布朗大学、MIT 等多个机构的研究者联合做了一项系统性研究,给出了否定的答案,并举例到「当我们发现大模型的思考链可被用于生成炸弹装置或投毒配方等高风险内容时,便意识到这一问题非同小可」。
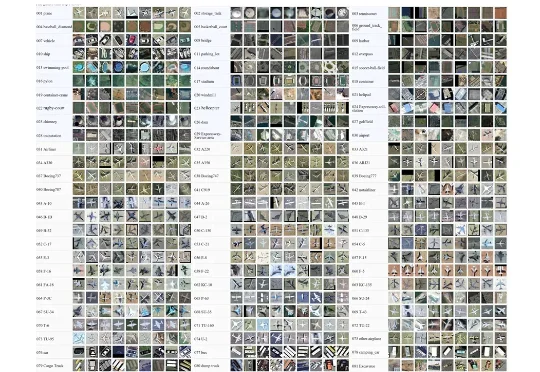
近日,北京航空航天大学史振威教授和邹征夏教授团队发布了一个面向通用遥感目标检测的大规模数据集与基础模型框架 ——LEVIRDet。该研究构建了目前最大规模、最全面的遥感目标检测数据集 LEVIRDet-159,并在此基础上提出了面向通用遥感检测的基础模型 LEVIRDetNet。

美团今日宣布开源万亿参数大模型LongCat-2.0,同步开放针对国产算力芯片深度优化的推理代码。该模型总参数达1.6万亿,平均激活约480亿参数,是业界首个在五万卡国产算力集群上完成全流程训练与推理的万亿参数模型。

近期, ECCV 2026 结果公布,Realsee 团队的成果 Argus: Metric Panoramic 3D Reconstruction for Indoor Scenes 成功入选。它面向室内全景图像,能够从稀疏、无序的全景照片中,直接预测相机位姿、度量深度和点云重建结果,可以为 3DGS 提供更稳定、更精准的几何约束。
Fable 5重新上线,Arena.ai的Gostev在一段视频中甩出63个3D世界,几乎都是一次成型。看了视频,就连刚加盟Anthropic预训练团队的Karpathy,也直呼没想到。
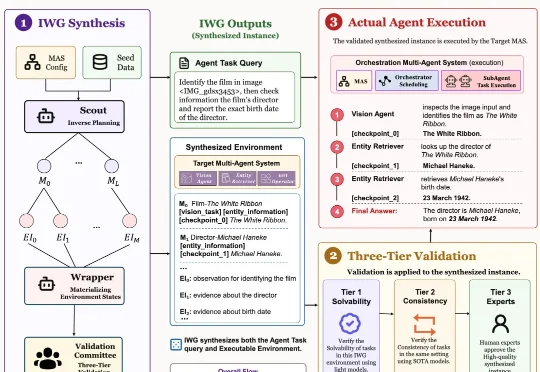
来自南京大学 NLP 实验室的 ICML 2026 论文 Recognize Your Orchestrator: An Entropy Dynamics Perspective for LLM Multi-Agent Systems 指出:在当前主流的 Orchestrator-Executor 多智能体架构中,系统失败往往并不首先来自某个执行器不会干活,

UC Berkeley团队提出的端到端流程旨在解决该问题,研究团队跑通了首条能够从网络视频生成真实灵巧手实机执行轨迹的完整链路:先从真实场景中的单目RGB视频中重建4D手-物交互过程,再将这些交互轨迹重定向到拥有22个自由度的Sharpa Wave灵巧手上。