# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
扩散大语言模型得到了突飞猛进的发展,早在 25 年 2 月 Inception Labs 推出 Mercury—— 第一个商业级扩散大型语言模型,同期人民大学发布第一个开源 8B 扩散大语言模型 LLaDA,5 月份 Gemini Diffusion 也接踵而至。种种迹象表明,扩散大语言模型很可能是下一代大语言模型基础范式的有力竞争者。但是针对于扩散大语言模型的解码策略和强化学习算法仍然是欠探索的。
近期,复旦大学、上海人工智能实验室、上海交通大学联合研究团队发布最新论文《Taming Masked Diffusion Language Models via Consistency Trajectory Reinforcement Learning with Fewer Decoding Step》。
他们提出了一套对于掩码扩散大语言模型(Masked Diffusion Large Language Model,MDLM)的高效解码策略 + 强化学习训练组合,显著提升了掩码扩散大语言模型的推理性能与效率,为扩散大语言模型的发展开辟了新路径。

掩码扩散大语言模型(MDLM)如 LLaDA 展现出与自回归模型相媲美的能力,并具备并行解码、灵活生成顺序、潜在少步推理等优势。然而,完全扩散式(Full Diffusion-Style)解码策略并未被广泛使用,取而代之的是分块解码(Block-wise)。因为目前的完全扩散式解码存在一大痛点 —— 性能大幅度逊色于分块解码。
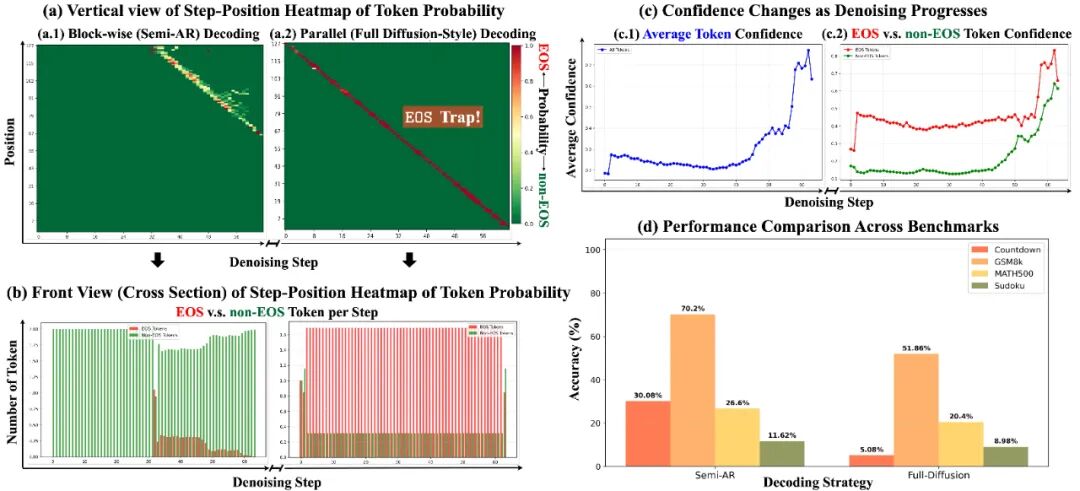
但令人疑惑的是,掩码扩散大语言模型在预训练和指令微调阶段并未针对分块解码这种方式进行适配微调,所以这一现象背后的原因仍不为人所知。该团队基于这点发现刨根问底,最终定位到 MDLM 的全扩散式解码的三个特点:
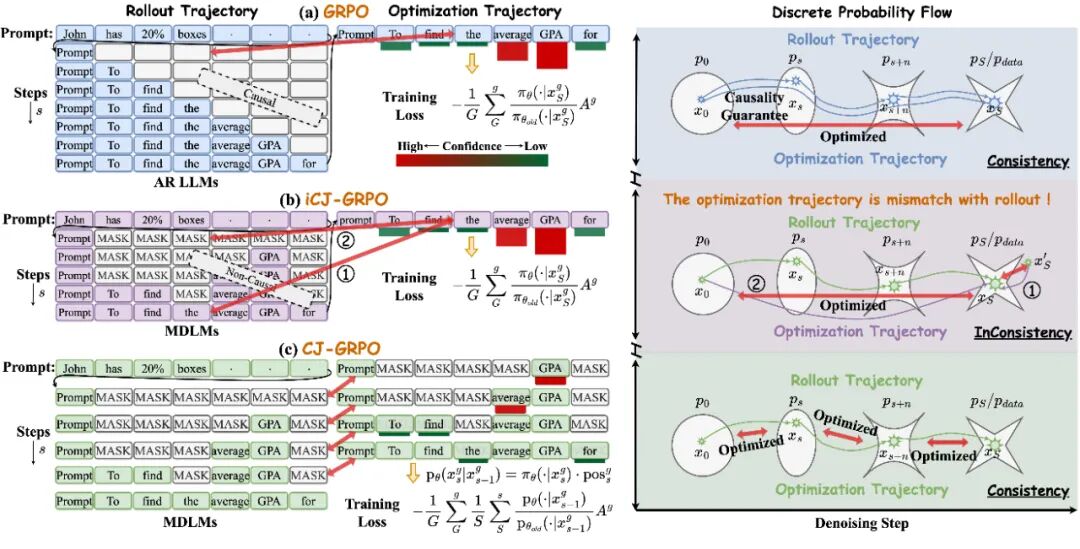
此外,在将为 AR LLMs 定制的强化学习算法迁移到 MDLM 时,可能会遇到 rollout 轨迹和优化轨迹不一致的问题,因为 AR 模型具有因果性掩码,获得完整轨迹后计算得到的 token 概率与 rollout 时保持一致。而 MDLM 采用的是双向注意力,获得完整轨迹再计算得到的 token 概率与 rollout 时不一致。而现有的方法是(1)使用 prompt masking 近似的一步优化,或者(2)从 fully masked response 进行一步去噪优化。但是这二者都面临 rollout 轨迹和实际优化轨迹不一致的问题,可能会引起较大的优化误差。
基于此,该团队将以上问题汇总为三个关键问题:
该团队提出三大核心贡献,致力于解决了上述问题:
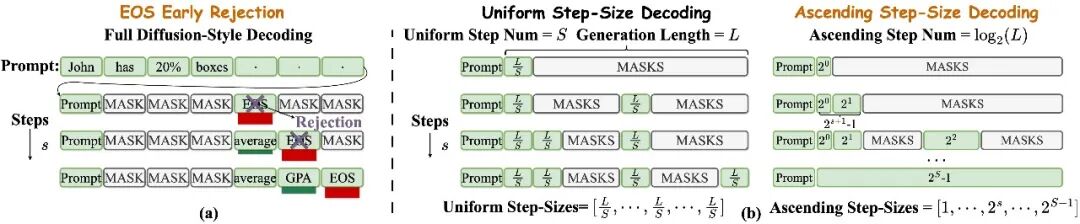
针对于 <EOS > 陷阱!该团队提出 <EOS > 早期拒绝机制在解码早期主动抑制 <EOS> 的置信度,避免生成过早终止。后期逐步恢复 <EOS > 的置信度,确保句子正常结束。显著提升全扩散式解码性能,在部分任务上显著超越半自回归解码。
基于「早期置信度低、后期急剧上升」的观察,前期谨慎解码,后期大胆解码,设计幂次递增解码步长调度器。将推理步数从 O (L) 降至 O (logL),大幅加速推理过程。

针对 rollout 轨迹和优化轨迹不一致问题,该团队提出一致性轨迹分组策略优化(CJ-GRPO),在 rollout 过程中存储每一步解码的中间状态,逐步优化相邻两个状态之间的转变,从而有效缓解跳步优化(或者说是不一致轨迹优化)带来的误差,提升训练稳定性与效果。
但是,由于过长的步数会引入较大的存储开销,而结合递增步长调度器后,既能保证轨迹的一致性,同时能大大缩减中间状态存储开销。于是该团队结合 <EOS > 早期拒绝机制、递增步长调度器和 CJ-GRPO 算法,削减训练时 CJ-GRPO 的中间状态存储开销,同时使得训练后的模型在少解码步数推理下甚至能达到 Baseline 方法多解码步数时的性能 —— 一石三鸟。
模型在少解码步数 (logL) 时仍能保持可观的性能(与 L/2 解码步数性能可比),真正激发扩散语言模型的推理速度优势的潜能。 训练时的解码时间 / 空间复杂度从 O (L) 降至 O (logL),大幅加速训练过程。
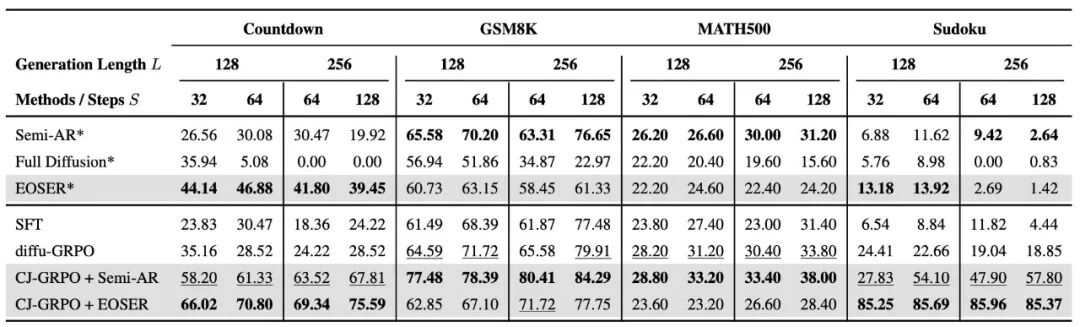
在数学推理(GSM8K、MATH500)和规划任务(Countdown、Sudoku)上,使用 LLaDA-8B-Instruct 模型进行了广泛的实验,结果显示:
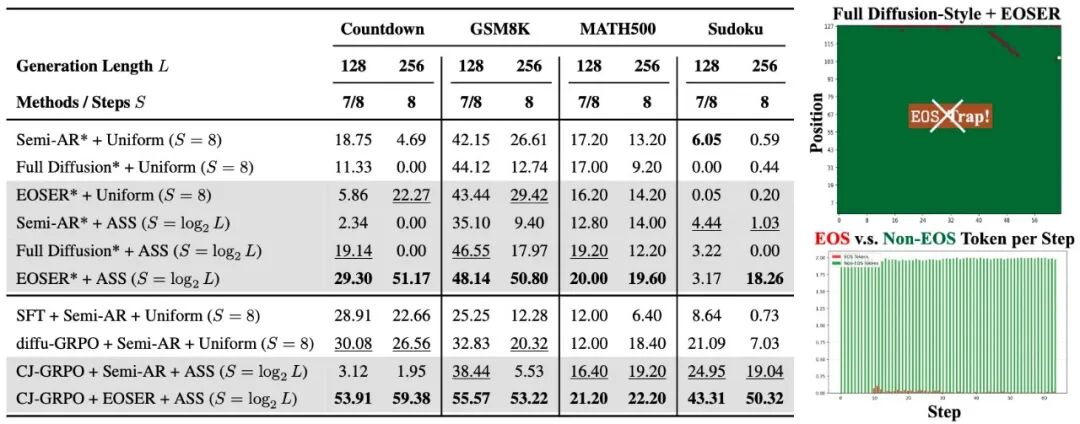
本工作探究了扩散语言模型的全扩散式解码策略,并对其使用更一致的轨迹、更少的解码步数进行优化,用更少的步数,越快越好地完成更复杂的推理任务,推动扩散语言模型的全扩散式解码、少步数解码、强化学习算法的发展。
并行推理 v.s. 顺序推理:装配了并行解码的 MDLM 在规划类任务中表现更佳,而数学类任务则更适合半自回归 / 分块解码,这比较符合人类的直观感受。
未来可探索混合推理模式,结合扩散与自回归优势,适应多样化任务需求。
📩欢迎引用、关注与合作交流。
文章来自于“机器之心”,作者 “机器之心”。



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
