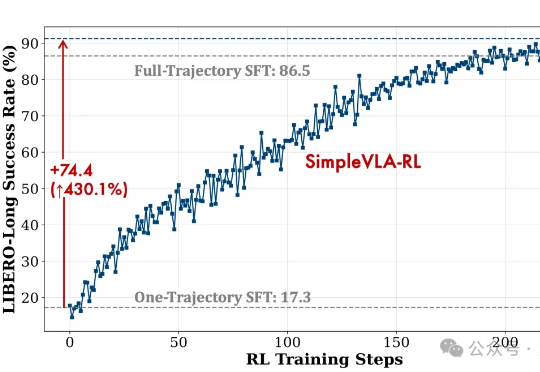
缺数据也能拿SOTA?清华&上海AI Lab破解机器人RL两大瓶颈
缺数据也能拿SOTA?清华&上海AI Lab破解机器人RL两大瓶颈视觉-语言-动作模型是实现机器人在复杂环境中灵活操作的关键因素。然而,现有训练范式存在一些核心瓶颈,比如数据采集成本高、泛化能力不足等。
来自主题: AI技术研报
8969 点击 2025-09-27 11:13
 搜索
搜索
视觉-语言-动作模型是实现机器人在复杂环境中灵活操作的关键因素。然而,现有训练范式存在一些核心瓶颈,比如数据采集成本高、泛化能力不足等。

TC-Light 是由中科院自动化所张兆翔教授团队研发的生成式渲染器,能够对具身训练任务中复杂和剧烈运动的长视频序列进行逼真的光照与纹理重渲染,同时具备良好的时序一致性和低计算成本开销,使得它能够帮助减少 Sim2Real Gap 以及实现 Real2Real 的数据增强,帮助获得具身智能训练所需的海量高质量数据。
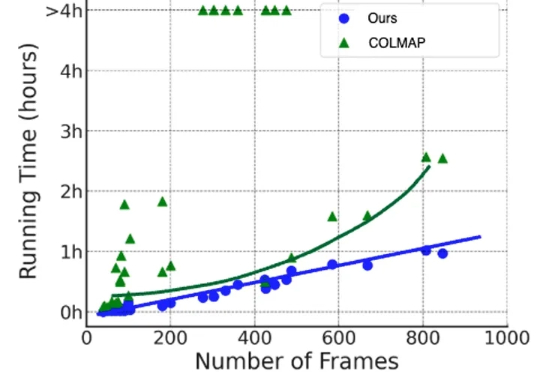
在三维重建、NeRF 训练、视频生成等任务中,相机参数是不可或缺的先验信息。传统的 SfM/SLAM 方法(如 COLMAP)在静态场景下表现优异,但在存在人车运动、物体遮挡的动态场景中往往力不从心,并且依赖额外的运动掩码、深度或点云信息,使用门槛较高,而且效率低下。
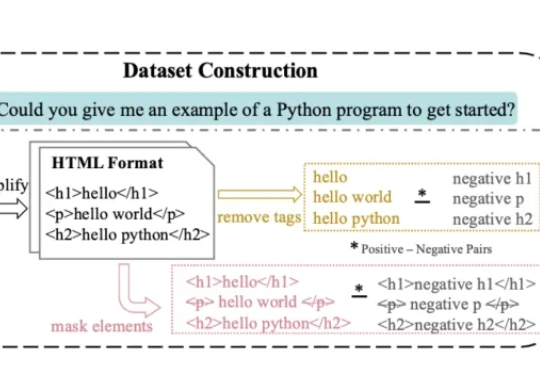
AI读不懂HTML、Markdown长文档的标题和结构,找信息总踩坑?解决方案来了——SEAL全新对比学习框架通过带结构感知+元素对齐,让模型更懂长文。
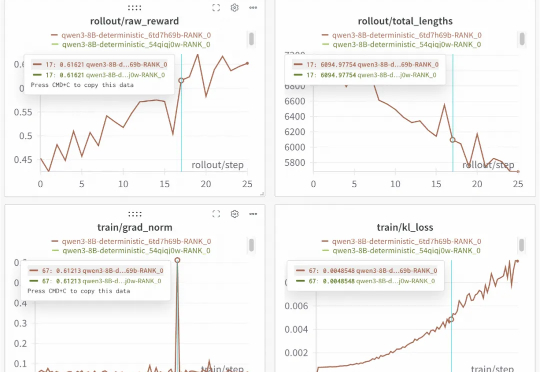
开源框架实现100%可复现的稳定RL训练!下图是基于Qwen3-8B进行的重复实验。两次运行,一条曲线,实现了结果的完美重合,为需要高精度复现的实验场景提供了可靠保障。这就是SGLang团队联合slime团队的最新开源成果。

不怕故障的机器人大脑来了这个大脑,就是估值已达45亿美元(截至今年6月)的Skild AI新推出的Skild Brain,它在一个包含十万种机器人姿态的虚拟环境中,训练了相当于一千年的时间才得以成型。更值得一提的是,此模型从未在这些机器人上进行过训练,它对它们的控制能力完全是涌现出来的。
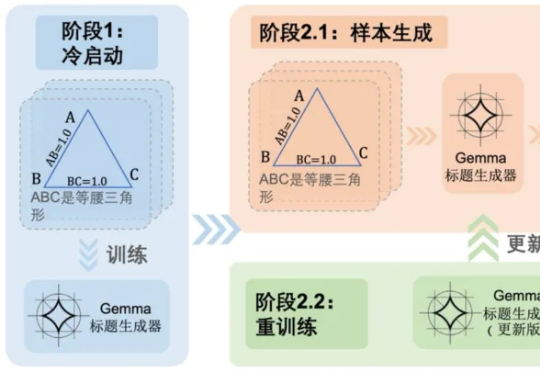
随着多模态大语言模型(MLLMs)在视觉问答、图像描述等任务中的广泛应用,其推理能力尤其是数学几何问题的解决能力,逐渐成为研究热点。 然而,现有方法大多依赖模板生成图像 - 文本对,泛化能力有限,且视

医学研究迎来“零人工”时代了?!清华大学自动化系索津莉课题组,发布首个专为医疗信息学设计的全自主AI研究框架——OpenLens AI。首次实现从文献挖掘→实验设计→数据分析→代码生成→可投稿论文的全链条自动化闭环。

其实大语言模型的“教育”问题也差不多。研究者在训练和使用这些模型时,离不开提示词。这就像一份人生剧本,告诉模型“你是谁?”“你要做什么?”“你能做到哪里?”但问题是,提示词到底应该像家长一样,
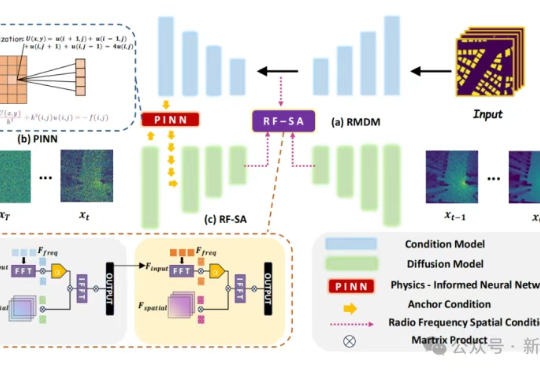
抢滩6G前夜,AI加物理正在重塑无线电地图产业格局。香港科技大学(广州)等机构联手重磅发布PhyRMDM框架,打破认知盲区,将物理约束与生成模型能力融合一体,显著提升高精度无线电地图的生成质量与稳定性。这一成果已被顶会ACM MM 2025接收。