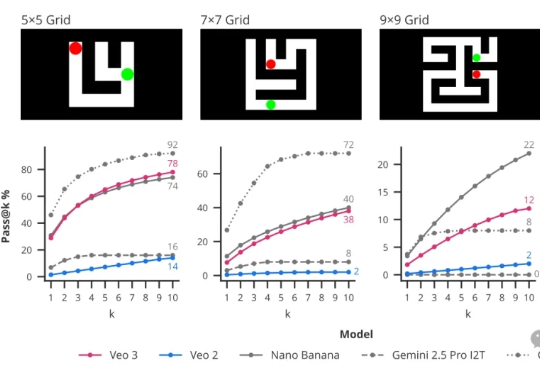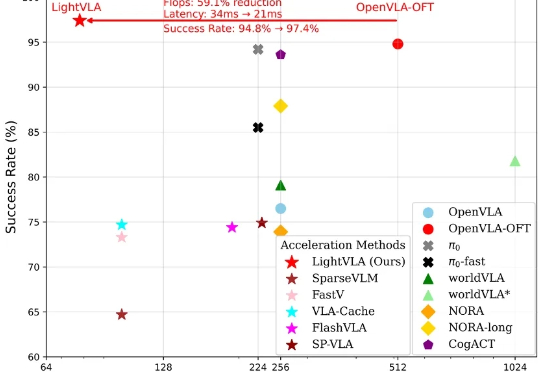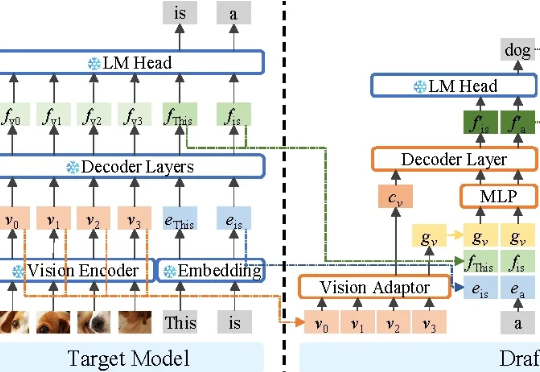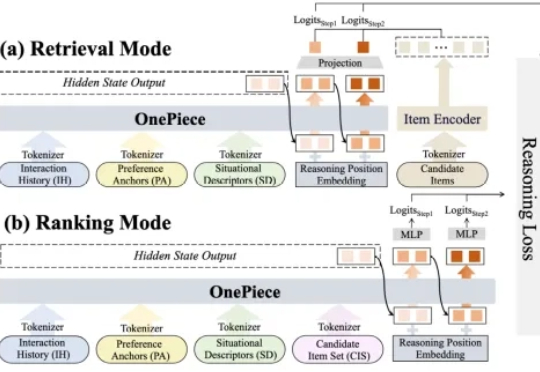
Shopee OnePiece:业内首个融合上下文工程、隐式推理和多目标训练策略的生成式搜推建模框架
Shopee OnePiece:业内首个融合上下文工程、隐式推理和多目标训练策略的生成式搜推建模框架2025 年,生成式推荐(Generative Recommender,GR)的发展如火如荼,其背后主要的驱动力源自大语言模型(LLM)那诱人的 scaling law 和通用建模能力(general-purpose modeling),将这种能力迁移至搜推广工业级系统大概是这两年每一个从业者孜孜不倦的追求。
来自主题: AI资讯
8268 点击 2025-09-28 18:14