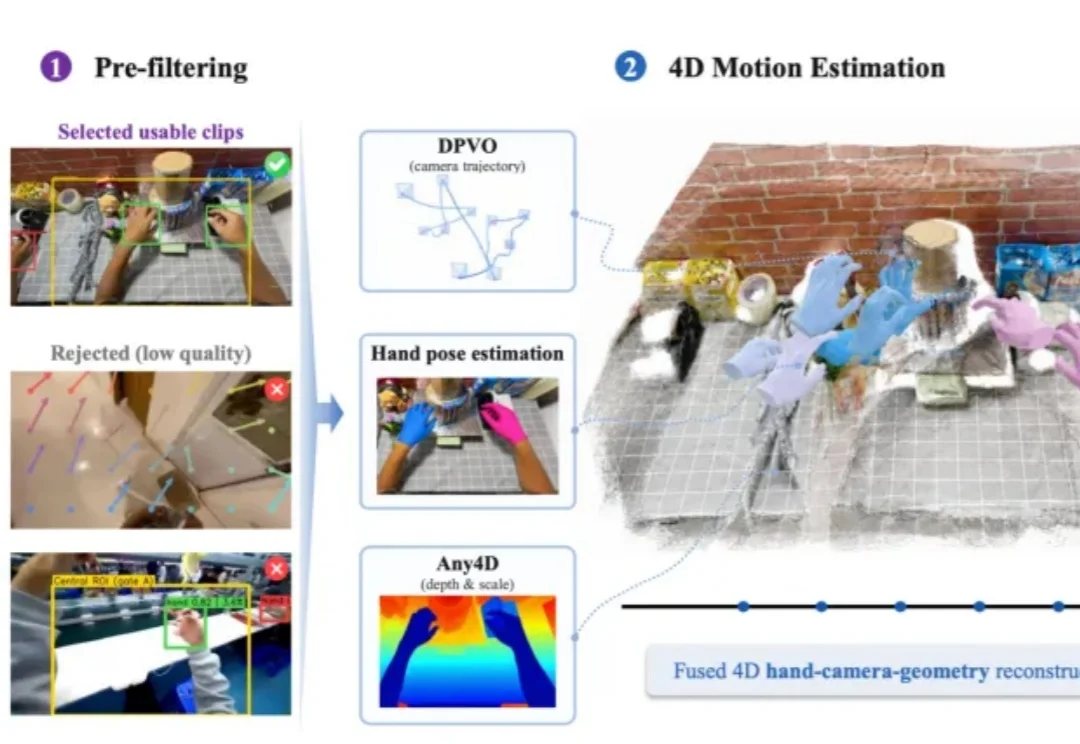
机器人双手迎来全栈训练系统:灵初智能EgoSteer让灵巧手无所不能
机器人双手迎来全栈训练系统:灵初智能EgoSteer让灵巧手无所不能记得何同学做过一个超复杂的流水线项目吗?
来自主题: AI技术研报
5446 点击 2026-07-23 16:34
 搜索
搜索
记得何同学做过一个超复杂的流水线项目吗?

逛过WAIC具身智能展区的人,多半有同一个疑问: 都2026年了,机器人干活,怎么还是慢吞吞的?

最新研究发现,AI幻觉不只会骗你了,还能喂大你的自信心、削弱你的判断力。

国防科技大学虚拟现实与视觉计算团队(SAW Lab)联合先进制导与控制技术国家级重点实验室等推出面向航拍几何 3D 视觉的统一大规模数据集与评测基准 「AirZoo」。
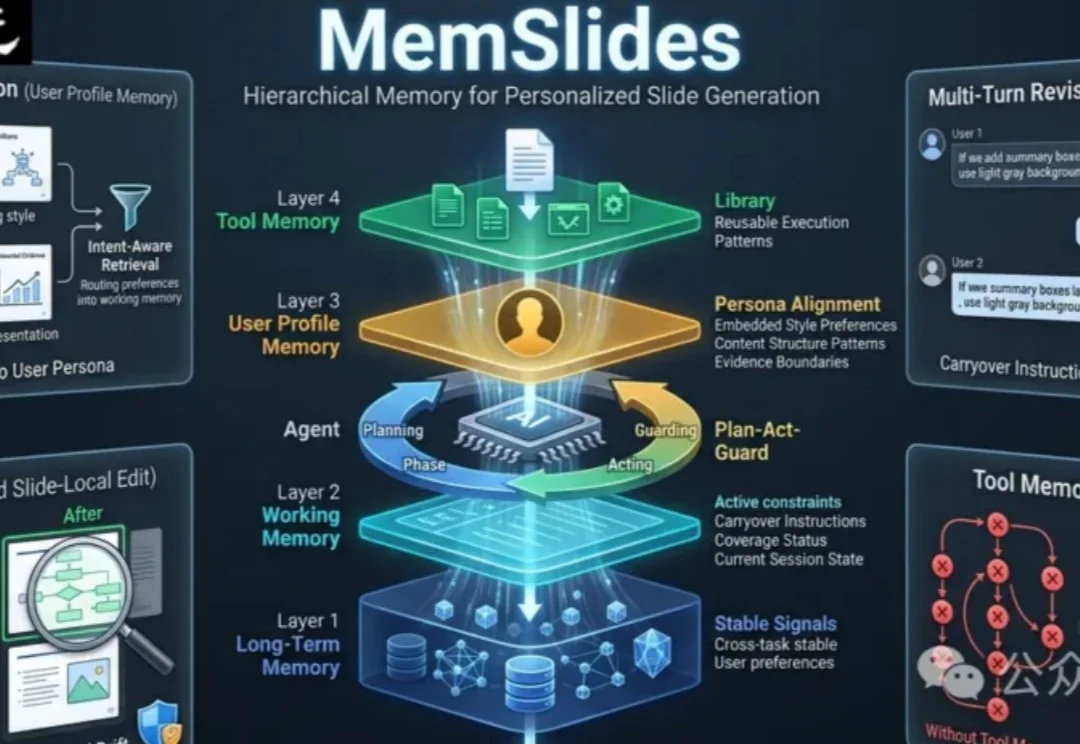
最尴尬的一刻,往往不是AI PPT生成失败。

智能的下一阶段,已从“模型”转向“系统可靠性和进化性”的比拼。

今天,世界模型几乎成为 AI 领域最受关注的话题之一,但对于“什么才是真正的世界模型”却依然存在巨大分歧。有人认为它只是视频生成的延伸,也有人认为只有能够理解物理规律、支持机器人行动的系统才是真正的世界模型。
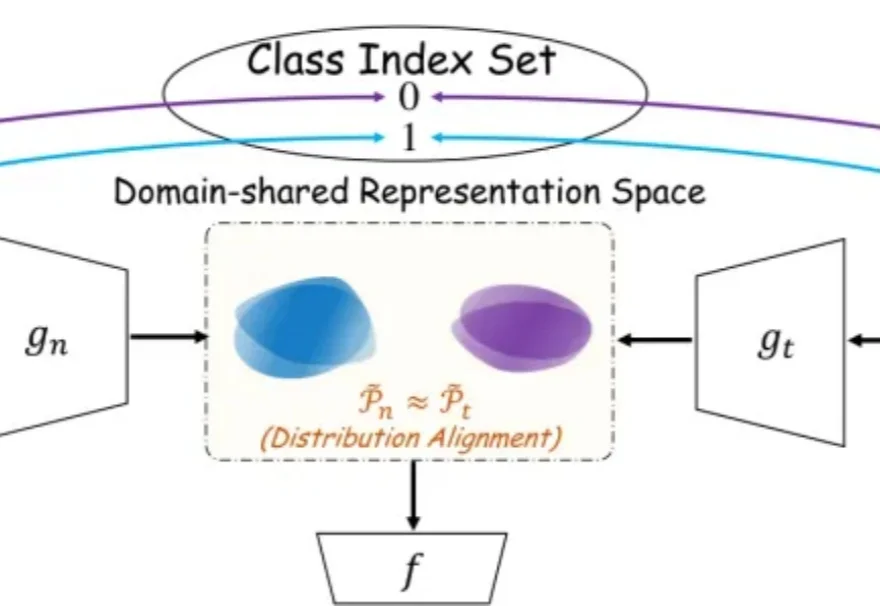
迁移学习里的“源数据”,未必非得是图像、文本或音频。

交互式视频世界模型正在从「一次性生成短片」走向「像游戏一样边操作边生成」。但长轨迹交互会迅速放大上下文、显存和多步去噪开销。Light Interaction不改模型参数、不重新训练,只在推理阶段把相机轨迹变成调度信号,动态选择历史上下文、在回访状态复用去噪输出,并用面向自回归生成的3D稀疏注意力降低计算。

视频是描述物理世界的重要数据形态,更是人类与物理世界交互的重要载体,视频理解大模型是让 AI 从数字世界走向物理世界最基础、最原生的组成部分。