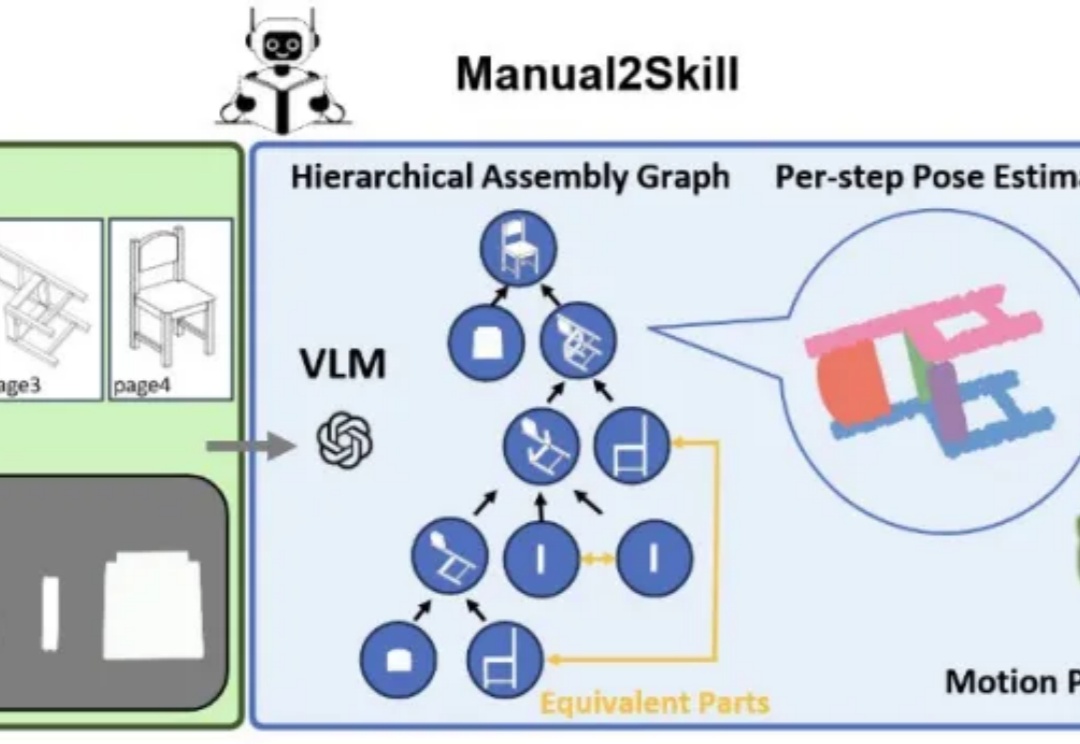
RSS 2025|从说明书学习复杂机器人操作任务:NUS邵林团队提出全新机器人装配技能学习框架Manual2Skill
RSS 2025|从说明书学习复杂机器人操作任务:NUS邵林团队提出全新机器人装配技能学习框架Manual2Skill视觉语言模型(Vision-Language Models, VLMs),为真实环境中的机器人操作任务提供了极具潜力的解决方案。
来自主题: AI技术研报
10751 点击 2025-05-29 16:33
 搜索
搜索
视觉语言模型(Vision-Language Models, VLMs),为真实环境中的机器人操作任务提供了极具潜力的解决方案。
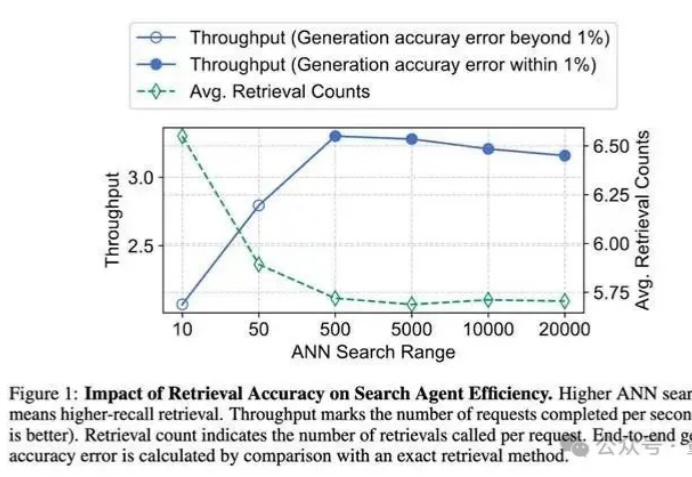
AI越来越聪明,但如果它们反应慢,效率低,也难以满足我们的需求。
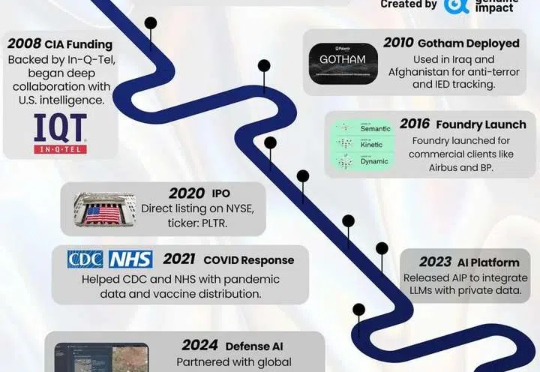
全球最贵估值科技公司,AI 巨头 Palantir 如何合理定价?
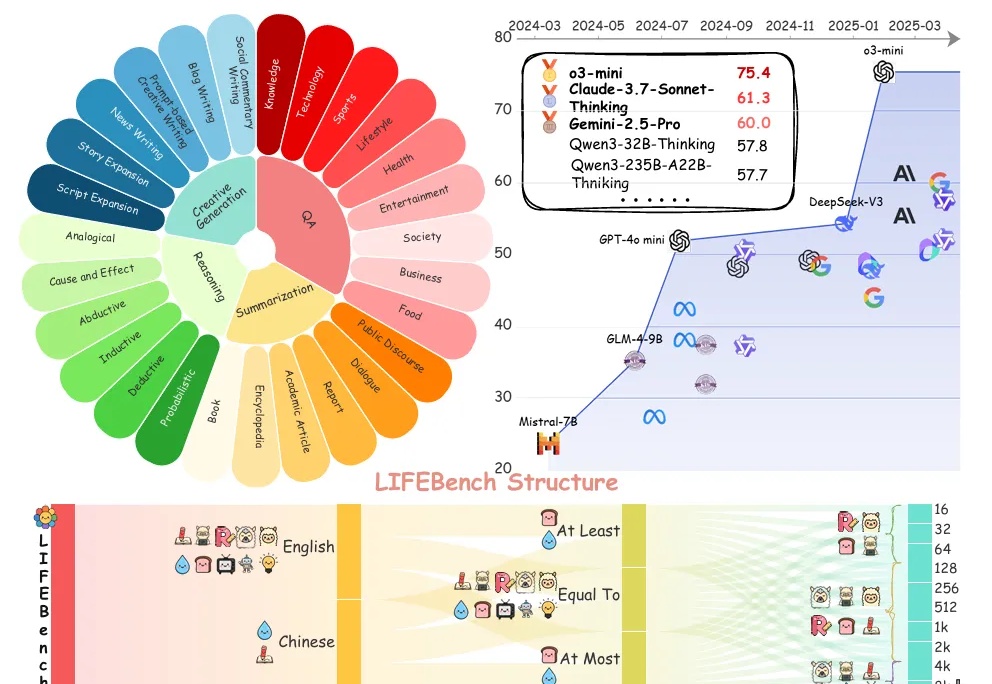
你是否曾对大语言模型(LLMs)下达过明确的“长度指令”?

复刻DeepSeek-R1的长思维链推理,大模型强化学习新范式RLIF成热门话题。
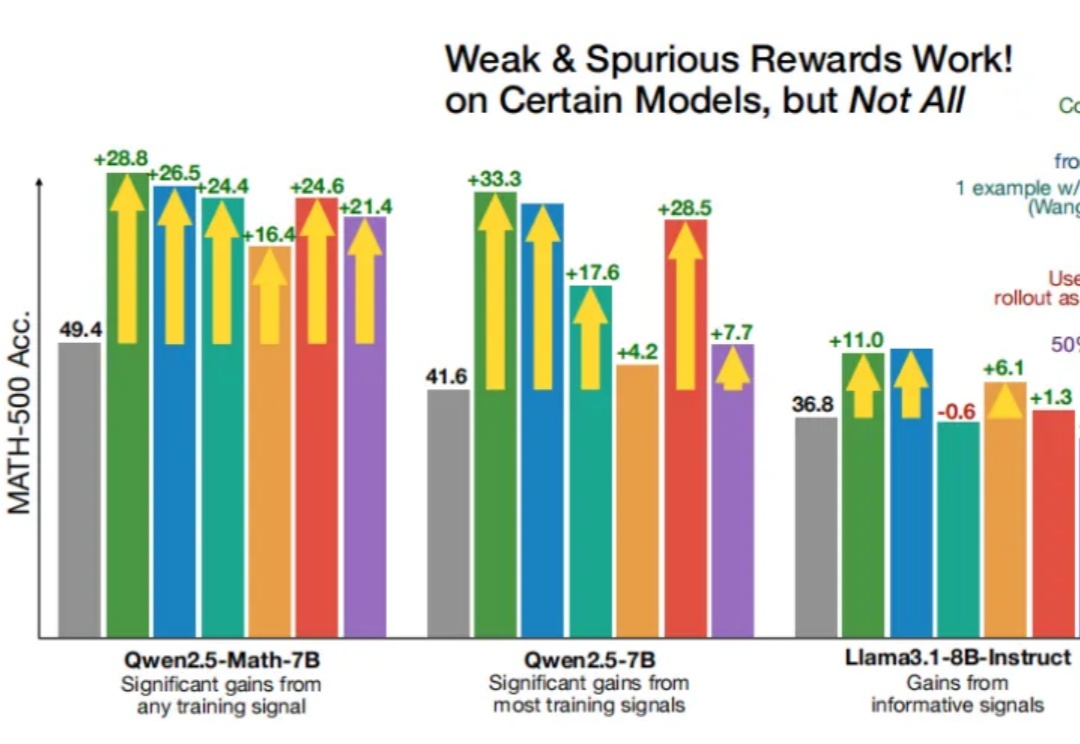
即使RLVR(可验证奖励强化学习)使用错误的奖励信号,Qwen性能也能得到显著提升?
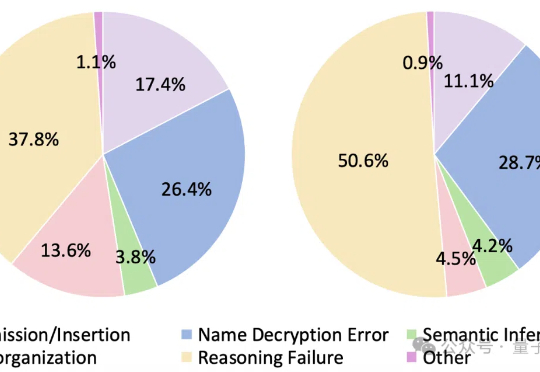
大语言模型遇上加密数据,即使是最新Qwen3也直冒冷汗!
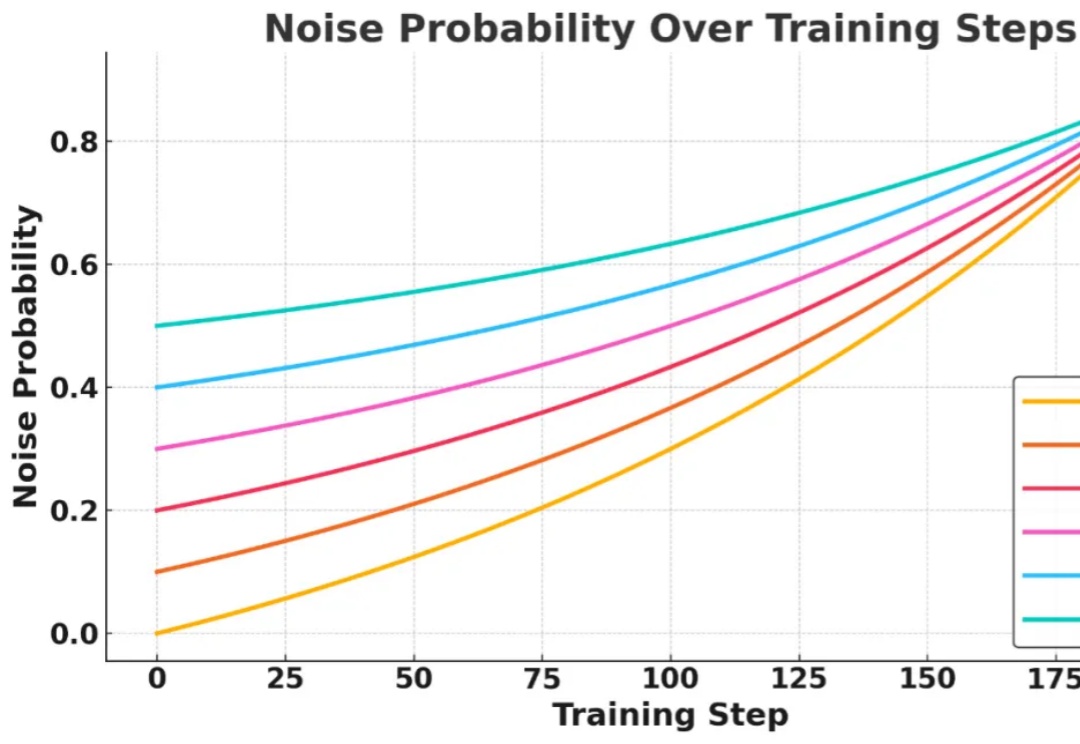
信息检索能力对提升大语言模型 (LLMs) 的推理表现至关重要,近期研究尝试引入强化学习 (RL) 框架激活 LLMs 主动搜集信息的能力,但现有方法在训练过程中面临两大核心挑战:
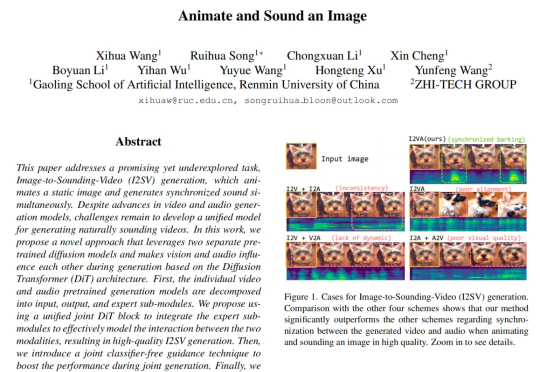
来自中国人民大学高瓴人工智能学院与值得买科技 AI 团队在 CVPR 2025 会议上发表了一项新工作,首次提出了一种从静态图像直接生成同步音视频内容的生成框架。其核心设计 JointDiT(Joint Diffusion Transformer)框架实现了图像 → 动态视频 + 声音的高质量联合生成。

当前顶尖AI模型是否真能“看懂”物理图像?