
不要自回归!扩散模型作者创业,首个商业级扩散LLM来了,编程秒出结果
不要自回归!扩散模型作者创业,首个商业级扩散LLM来了,编程秒出结果当前的 AI 领域,可以说 Transformer 与扩散模型是最热门的模型架构。也因此,有不少研究团队都在尝试将这两种架构融合到一起,以两者之长探索新一代的模型范式,比如我们之前报道过的 LLaDA。不过,之前这些成果都还只是研究探索,并未真正实现大规模应用。
来自主题: AI技术研报
11797 点击 2025-02-27 14:40
 搜索
搜索
当前的 AI 领域,可以说 Transformer 与扩散模型是最热门的模型架构。也因此,有不少研究团队都在尝试将这两种架构融合到一起,以两者之长探索新一代的模型范式,比如我们之前报道过的 LLaDA。不过,之前这些成果都还只是研究探索,并未真正实现大规模应用。
第四天,DeepSee发布包括三个主要项目: DualPipe- 一种用于 V3/R1 训练的双向流水线并行算法,实现计算和通信完全重叠; EPLB(Expert Parallelism Load Balancer) - 专为 V3/R1 设计的专家并行负载均衡器; Profile-data- 分析 V3/R1 中计算与通信重叠的性能数据集。

按时整活!DeepSeek开源周第四天,直接痛快「1日3连发」,且全都围绕一个主题:优化并行策略。
当DeepSeek引发业界震动时,元始智能创始人彭博正专注于一个更宏大的愿景。

在实际应用中,我们常常需要模型输出具有严格结构的数据,比如生物制药生产记录、金融交易报告或医疗健康档案等。这种结构化输出的需求在生物制造、金融服务、医疗健康等严格监管的领域尤为重要。
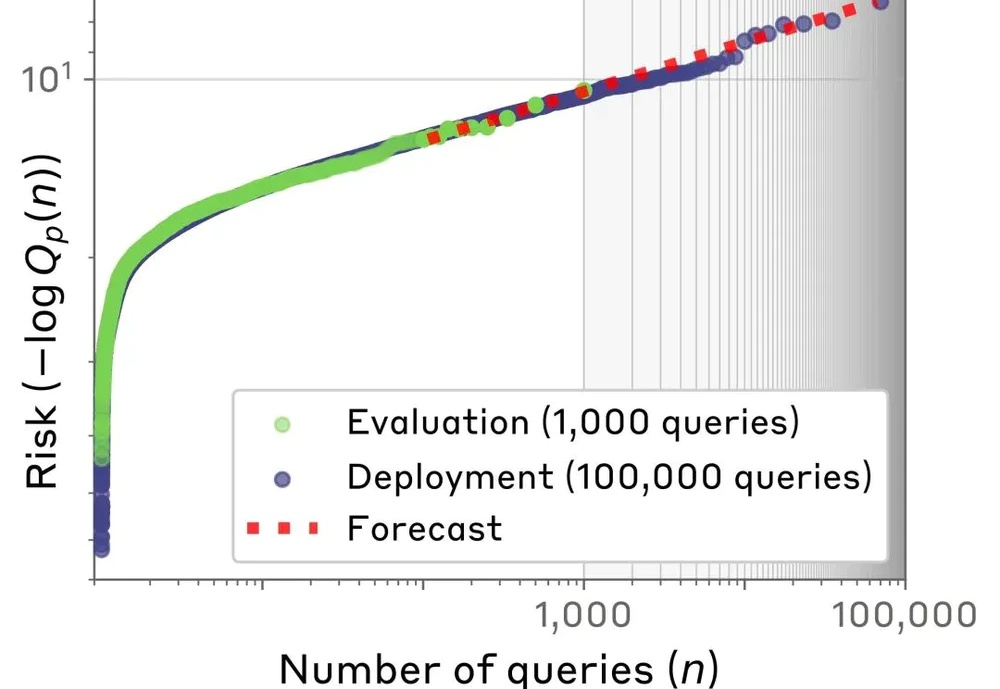
对齐科学的主要目标之一,是在危险行为发生之前,预测人工智能(AI)模型的危险行为倾向。
嚯,万众期待的GPT-4.5,本周就要空降发布?!部分用户的ChatGPT安卓版本(1.2025.056 测试版)上,已经出现了“GPT-4.5研究预览(GPT-4.5 research preview)”的字样。

大自然的分形之美,蕴藏着宇宙的设计规则。刚刚,何恺明团队祭出「分形生成模型」,首次实现高分辨率逐像素建模,让计算效率飙升4000倍,开辟AI图像生成新范式。
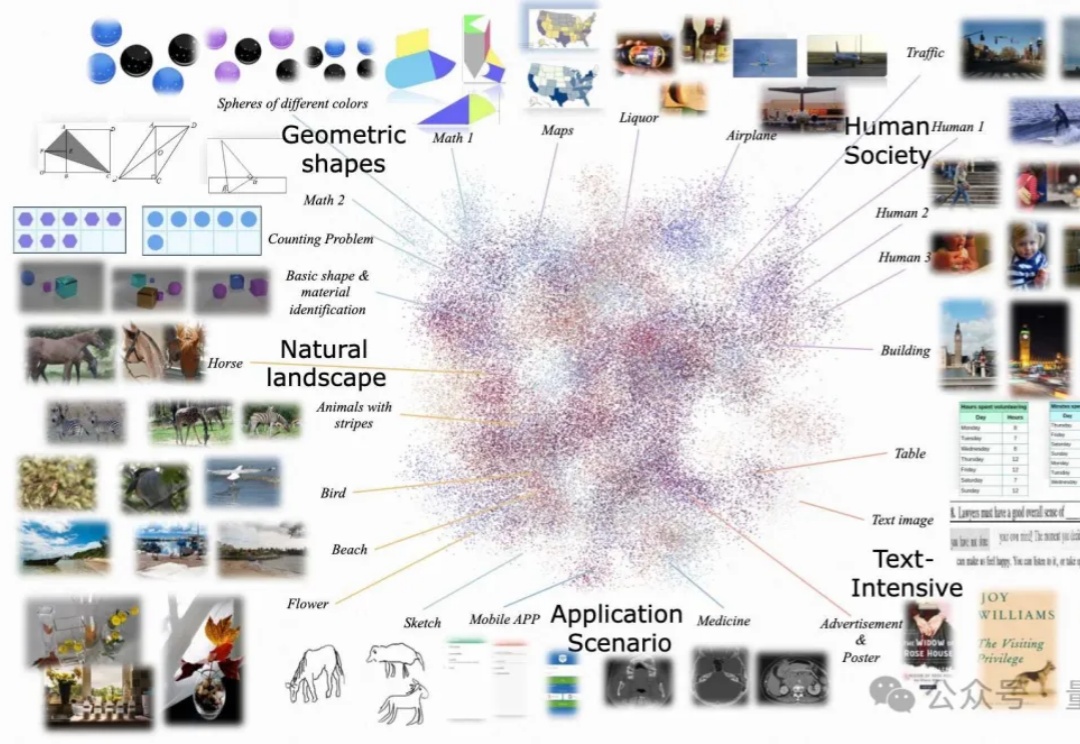
尽管多模态大语言模型(MLLMs)取得了显著的进展,但现有的先进模型仍然缺乏与人类偏好的充分对齐。这一差距的存在主要是因为现有的对齐研究多集中于某些特定领域(例如减少幻觉问题),是否与人类偏好对齐可以全面提升MLLM的各种能力仍是一个未知数。

进入到 2025 年,视频生成(尤其是基于扩散模型)领域还在不断地「推陈出新」,各种文生视频、图生视频模型展现出了酷炫的效果。其中,长视频生成一直是现有视频扩散的痛点。