
打脸!GPT-4o输出长度8k都勉强,陈丹琦团队新基准测试:所有模型输出都低于标称长度
打脸!GPT-4o输出长度8k都勉强,陈丹琦团队新基准测试:所有模型输出都低于标称长度很多大模型的官方参数都声称自己可以输出长达32K tokens的内容,但这数字实际上是存在水分的??
来自主题: AI技术研报
11590 点击 2025-01-16 10:30
 搜索
搜索
很多大模型的官方参数都声称自己可以输出长达32K tokens的内容,但这数字实际上是存在水分的??

Sakana AI发布了Transformer²新方法,通过奇异值微调和权重自适应策略,提高了LLM的泛化和自适应能力。新方法在文本任务上优于LoRA;即便是从未见过的任务,比如MATH、HumanEval和ARC-Challenge等,性能也都取得了提升。
自适应 LLM 反映了神经科学和计算生物学中一个公认的原理,即大脑根据当前任务激活特定区域,并动态重组其功能网络以响应不断变化的任务需求。
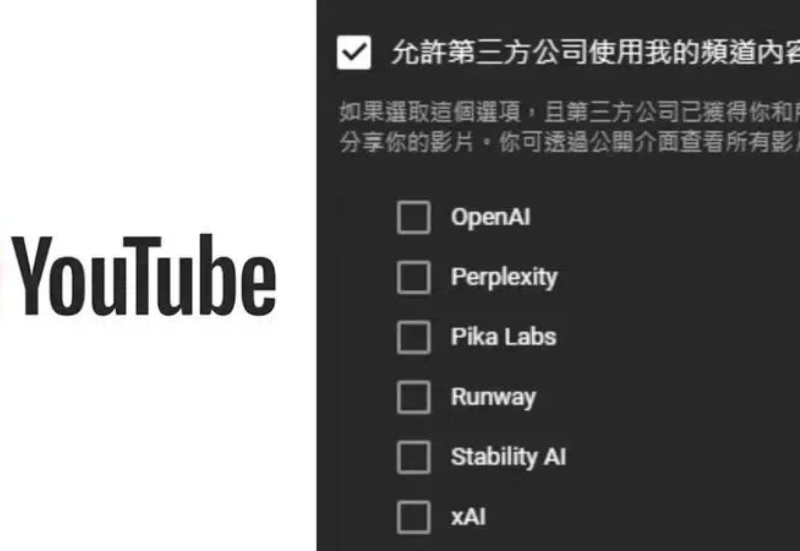
做过 Up 主、YouTuber 或是视频自媒体从业者都知道,一部传到平台上 10 分钟的成片,背后可能是几个小时的素材。
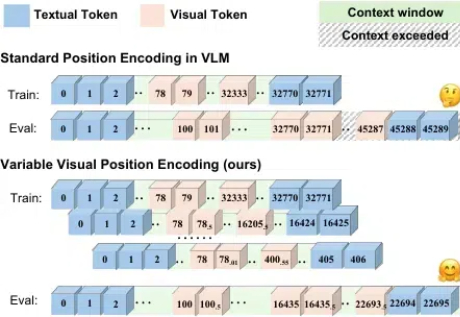
随着语言大模型的成功,视觉 - 语言多模态大模型 (Vision-Language Multimodal Models, 简写为 VLMs) 发展迅速,但在长上下文场景下表现却不尽如人意,这一问题严重制约了多模态模型在实际应用中的潜力。

在机器学习和数据科学领域,余弦相似度长期以来一直是衡量高维对象之间语义相似度的首选指标。余弦相似度已广泛应用于从推荐系统到自然语言处理的各种应用中。它的流行源于人们相信它捕获了嵌入向量之间的方向对齐,提供了比简单点积更有意义的相似性度量。
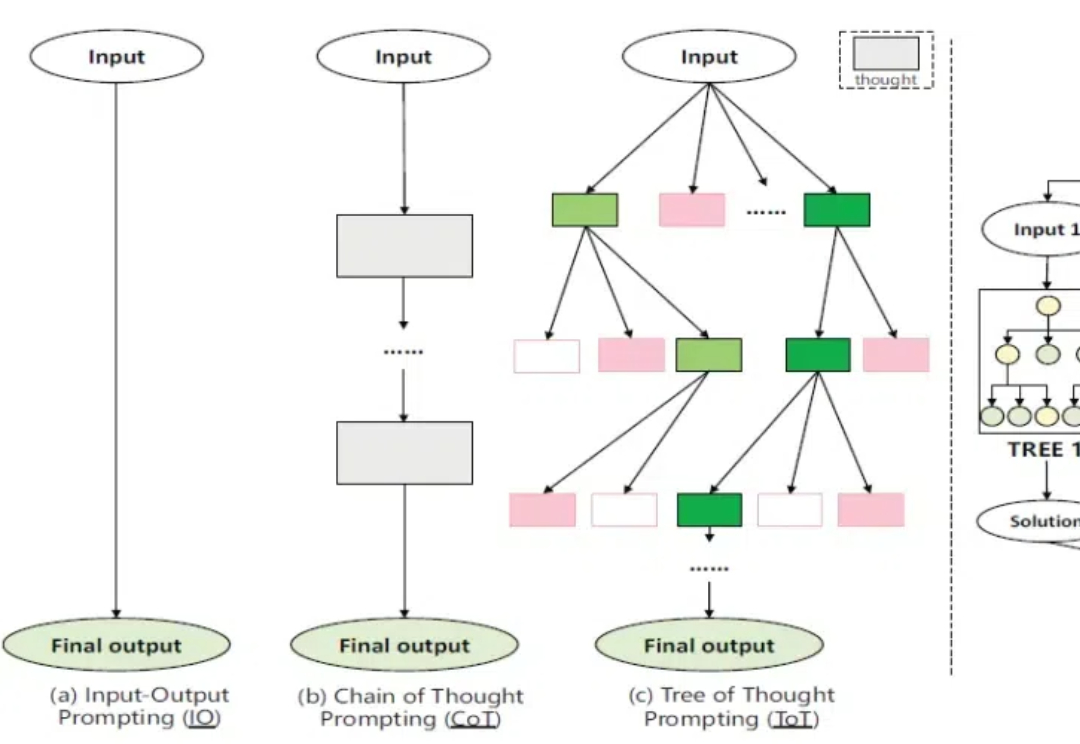
OpenAI 接连发布 o1 和 o3 模型,大模型的高阶推理能力正在迎来爆发式增强。在预训练 Scaling law “撞墙” 的背景下,探寻新的 Scaling law 成为业界关注的热点。高阶推理能力有望开启新的 Scaling law,为大模型的发展注入新的活力。
AC3D 从基本原理出发,分析了摄像机运动在视频生成中的特点,并通过以下三方面改进了视频生成的效果和效率:
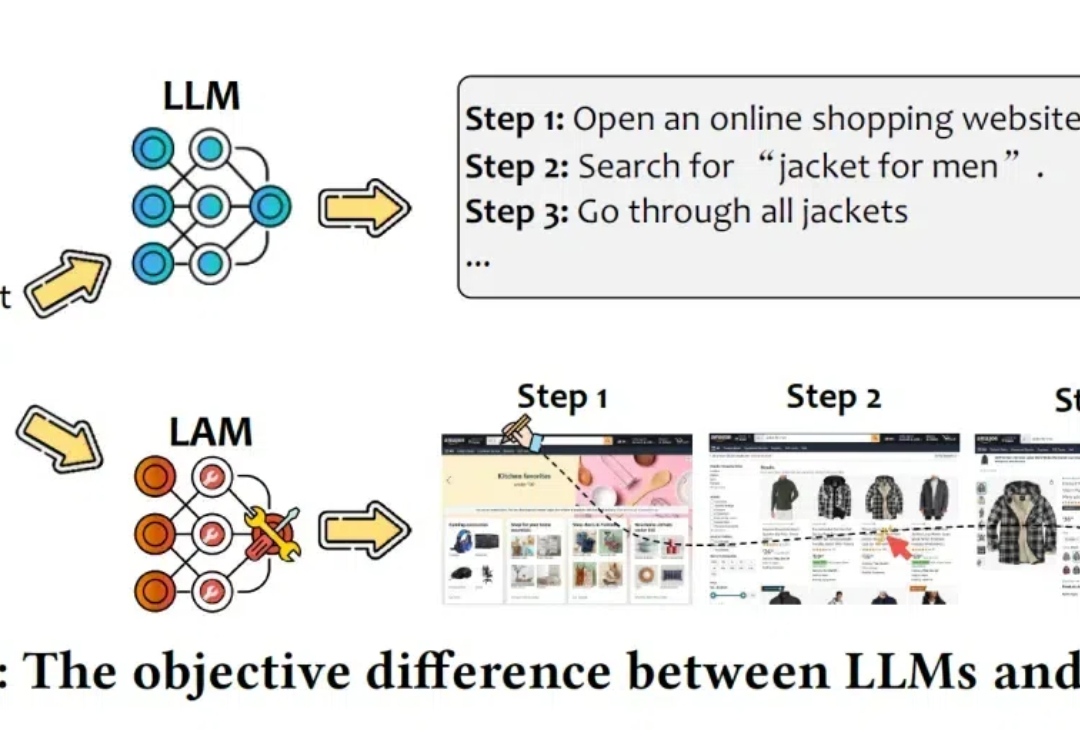
AI大模型正从仅会聊天的LLM进化为能够执行任务的大型行动模型LAM。它不仅能理解用户的指令,还能在软件环境中自主执行任务。
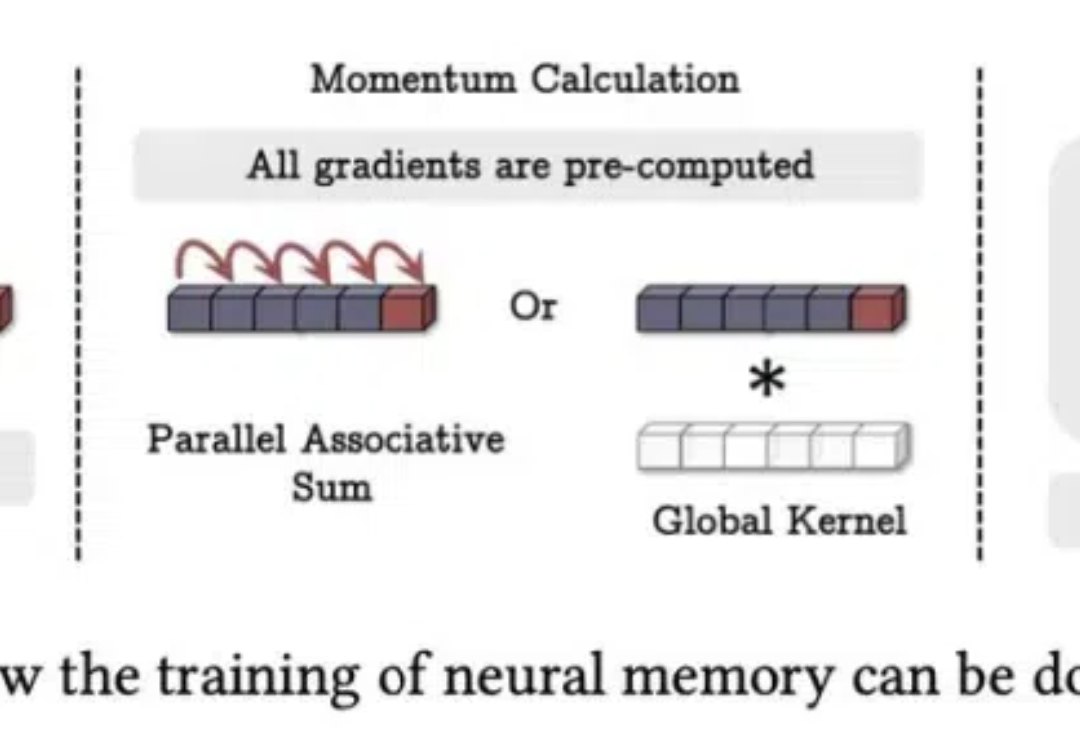
想挑战 Transformer 的新架构有很多,来自谷歌的“正统”继承者 Titan 架构更受关注。