陈天奇团队LLM结构化生成新引擎XGrammar:百倍加速、近零开销
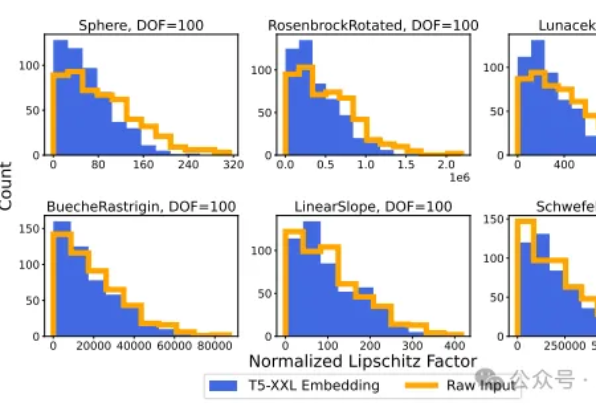
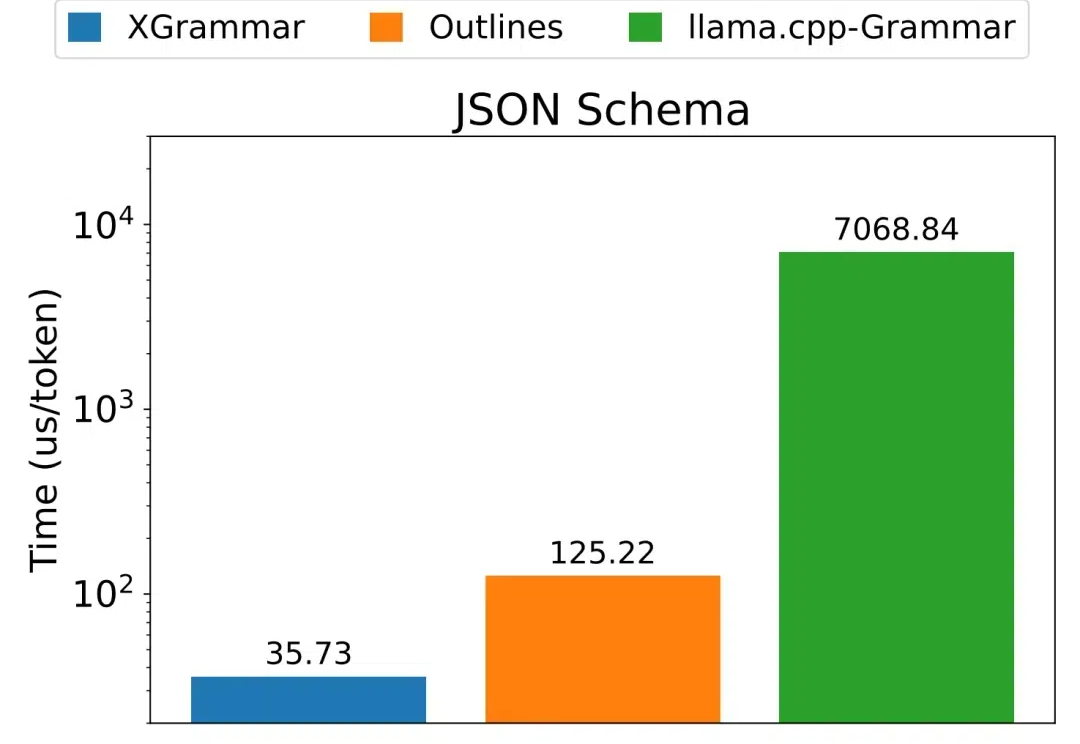
陈天奇团队LLM结构化生成新引擎XGrammar:百倍加速、近零开销不管是编写和调试代码,还是通过函数调用来使用外部工具,又或是控制机器人,都免不了需要 LLM 生成结构化数据,也就是遵循某个特定格式(如 JSON、SQL 等)的数据。 但使用上下文无关语法(CFG)来进行约束解码的方法并不高效。针对这个困难,陈天奇团队提出了一种新的解决方案:XGrammar。
来自主题: AI资讯
8905 点击 2024-11-26 14:18