
字节豆包大模型团队突破残差连接局限!预训练收敛最快加速80%
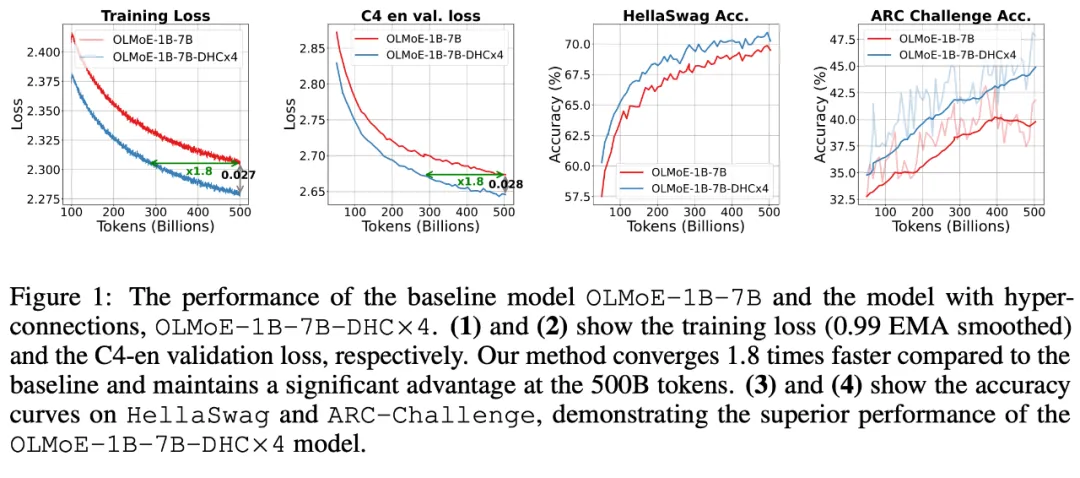
字节豆包大模型团队突破残差连接局限!预训练收敛最快加速80%字节跳动豆包大模型团队于近日提出超连接(Hyper-Connections),一种简单有效的残差连接替代方案。面向残差连接的主要变体的局限问题,超连接可通过动态调整不同层之间的连接权重,解决梯度消失和表示崩溃(Representation Collapse)之间的权衡困境。在 Dense 模型和 MoE 模型预训练中,超连接方案展示出显著的性能提升效果,使收敛速度最高可加速 80%。
来自主题: AI技术研报
6445 点击 2024-11-07 17:41








