
反向和错位图灵测试:GPT-4比人类更「人性化」!
反向和错位图灵测试:GPT-4比人类更「人性化」!由AI生成的内容渐渐充斥了互联网。
来自主题: AI资讯
5107 点击 2024-09-09 14:17
 搜索
搜索
由AI生成的内容渐渐充斥了互联网。

所有模型都是通过在来自互联网的海量数据上进行训练来工作的,然而,随着人工智能越来越多地被用来生成充满垃圾信息的网页,这一过程可能会受到威胁。
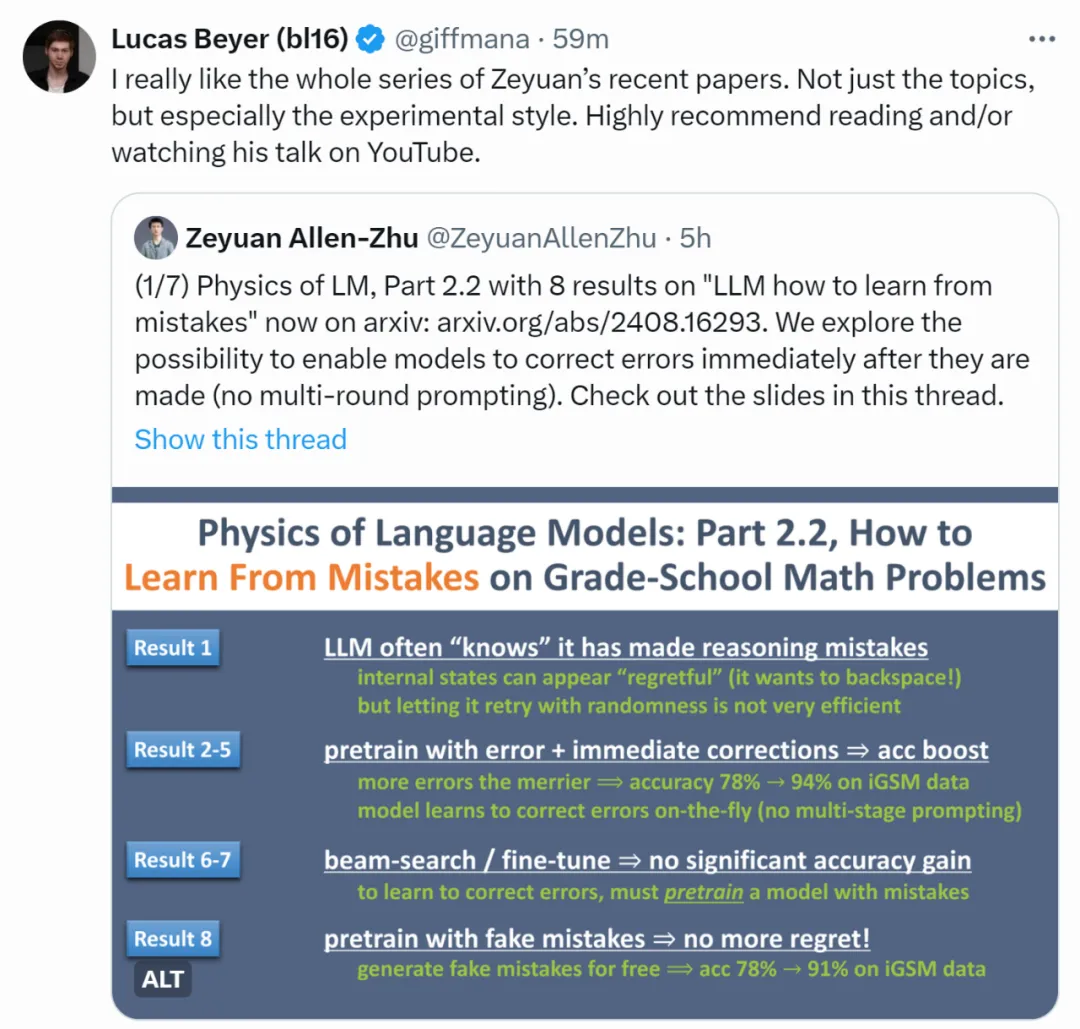
即便是最强大的语言模型(LLM),仍会偶尔出现推理错误。除了通过提示词让模型进行不太可靠的多轮自我纠错外,有没有更系统的方法解决这一问题呢?
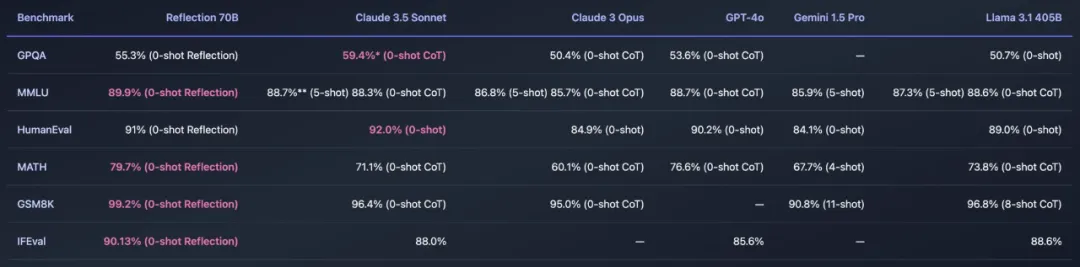
最近,开源大模型社区再次「热闹」了起来,主角是 AI 写作初创公司 HyperWrite 开发的新模型 Reflection 70B。
今年4月,中科院、滑铁卢大学等机构联合发表了一篇AI行业论文,让互联网上的“乐子人”直呼离谱。
9 月 2 日,马斯克发文称,其人工智能公司 xAI 的团队上线了一台被称为「Colossus」的训练集群,总共有 100000 个英伟达的 H100 GPU。

近日,上海交通大学、上海人工智能实验室和上海交通大学附属瑞金医院联合团队发布基于异常检测预训练的心电长尾诊断模型。

免训练多模态分割领域有了新突破!

AI竟然可以反过来“训练”人类了!(震惊.jpg)MIT的最新研究模拟了犯罪证人访谈,结果发现大模型能够有效诱导“证人”产生虚假记忆,并且效果明显优于其他方法。
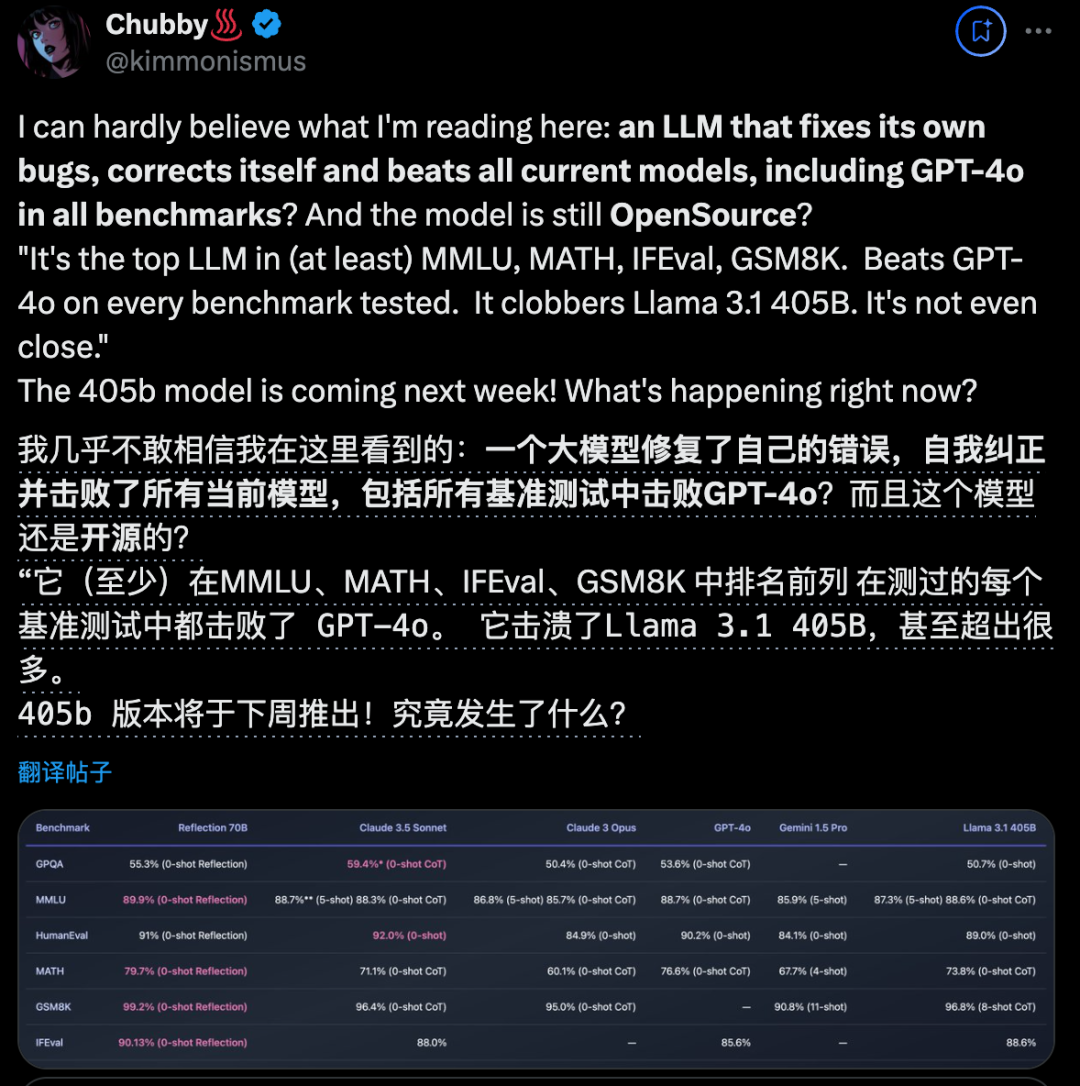
开源大模型王座突然易主,居然来自一家小创业团队,瞬间引爆业界。新模型名为Reflection 70B,使用一种全新训练技术,让AI学会在推理过程中纠正自己的错误和幻觉。