视觉推理「囫囵吞枣」靠不住!ProLaViT教会多模态大模型在隐空间里「步步为营」
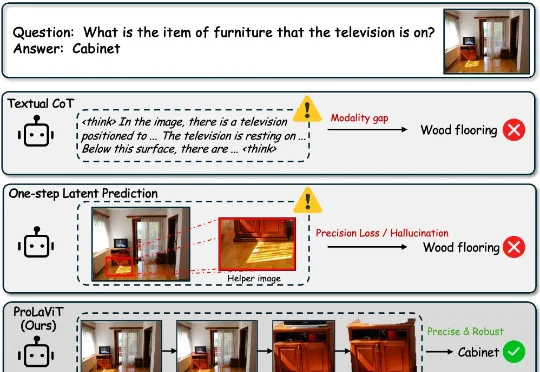
视觉推理「囫囵吞枣」靠不住!ProLaViT教会多模态大模型在隐空间里「步步为营」针对这一挑战,腾讯内容服务部 BAC 提出了一个名为 ProLaViT(Progressive Latent Visual Thought) 的全新框架。它的核心思想是:别急着下结论,先在连续隐空间里像人一样「步步推导」。 即让模型遵循 「定位 → 聚焦 → 分离」(Locate → Focus → Isolate) 的因果链,逐步收紧视觉注意力,最终精准锁定目标。
来自主题: AI技术研报
8469 点击 2026-07-21 16:55